August 9, 2018 / gbl08ma / 0 Comments
…and it’s also the next Steam.
Dear regular readers: we all know I’m not a regular writer, and you were probably expecting this to be the second post on the series about internet forums in 2018. That post is more than due by now – at this rate it won’t be finished by the end of the year – even though the series purposefully never had any announced schedule. I apologize for the delay, but bear with me: this post is not completely unrelated to the subject of that series.
Discord, in case you didn’t know, is free and proprietary instant messaging software with support for text, voice and video communication – or as they put it, “All-in-one voice and text chat for gamers that’s free, secure, and works on both your desktop and phone.” Launched in 2015, it has become very popular among gamers indeed – even though the service is definitely usable and useful for purposes very distant from gaming, and to people who don’t even play games. In May, as it turned three years old, the service had 130 million registered users, but this figure is certainly out of date, as Discord earns over 6 million new users per month.
If you have ever used Slack, Discord is similar, but free, easier to set up by random people, and designed to cater to everyone, not just businesses and open source projects. If you have ever used Skype, Discord is similar, but generally works better: the calls have much better quality (to the point where users’ microphones are actually the limiting factor), it uses less system resources than modern Skype clients on most platforms, and its UI, stability and reliability doesn’t get worse every month as Microsoft decides to ruin Skype some more. You can have direct conversations with other people or in a group, but Discord also has the concept of “servers”, which are usually dedicated to a game, community or topic, and have multiple “channels” – just like IRC and Slack channels – for organizing conversations and users into different topics. (Beware that despite the “server” name, Discord servers can not be self-hosted; in technical documents, servers are called “guilds”).
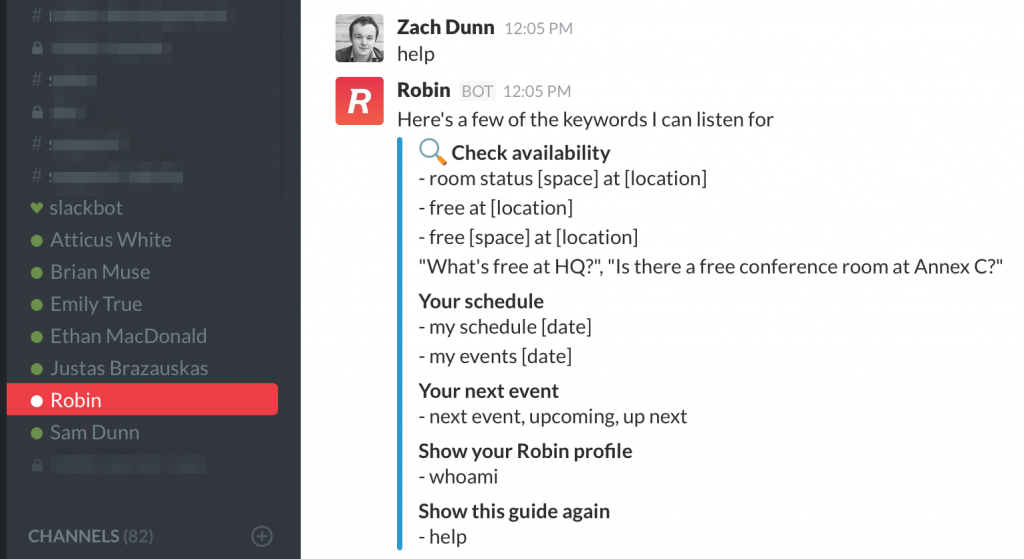
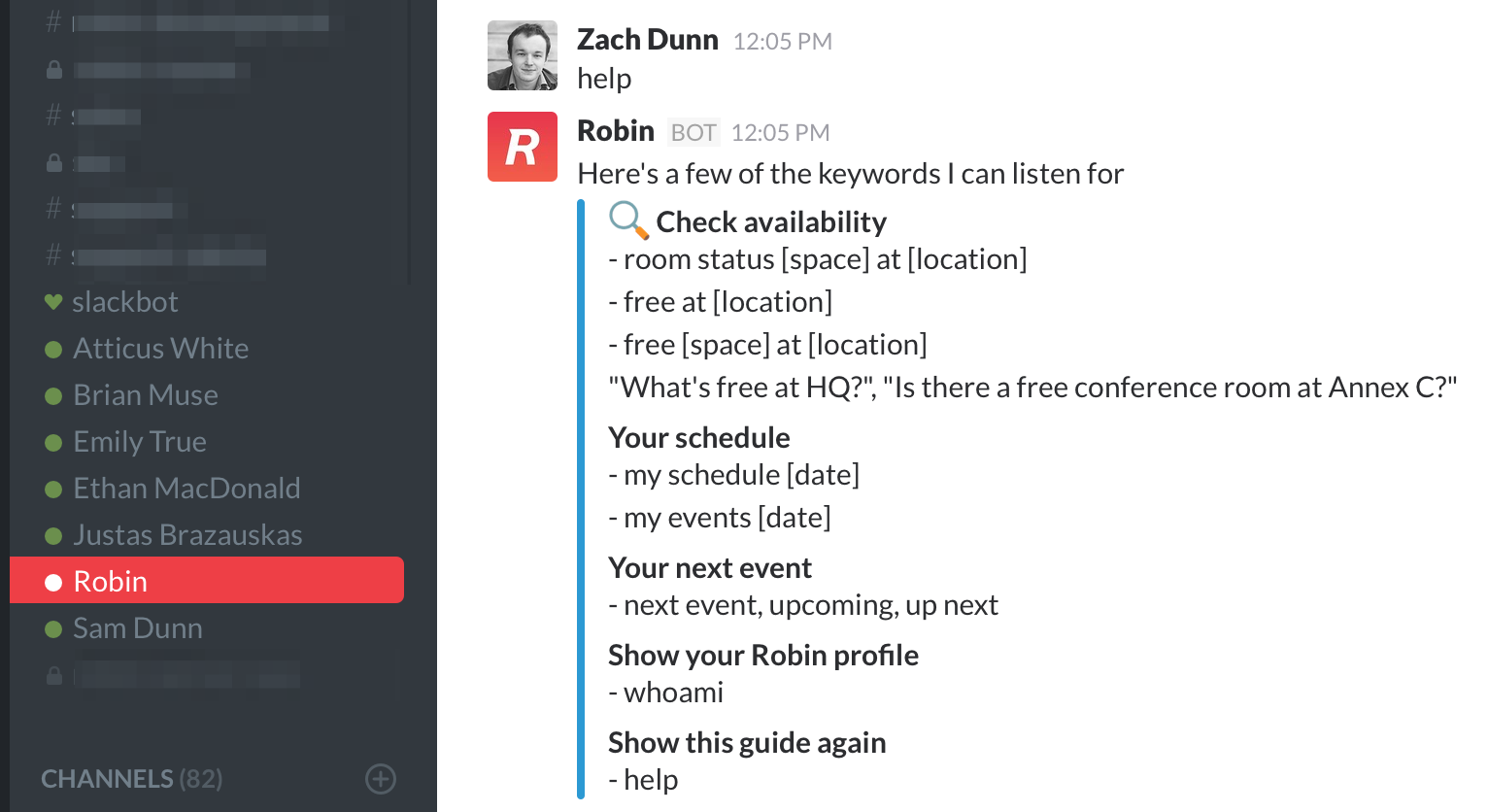
Example of Slack bot in action. Image credit: Robin Help Center
Much like in Slack (and, more recently, Skype, I believe), bots are first-class citizens, although they are perhaps not as central to the experience as in many Slack communities. In Discord, bots appear as any other user, but with a clearly visible “bot” tag, and they can send and receive messages like any other user, participate in text in voice chats, perform administrative/moderation tasks if given permission… to sum it up, the only limit is how much code is behind each bot.
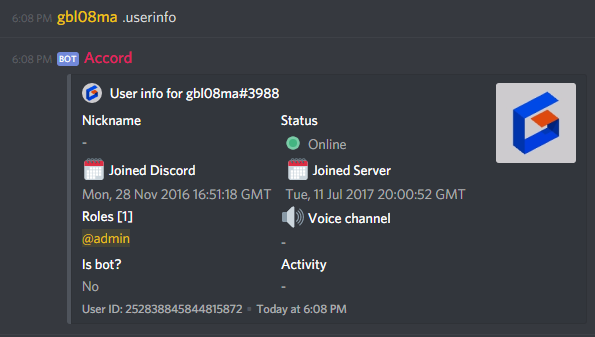
Example of Discord bot in action. Discord bots can also join voice channels, e.g. to play music.
I was introduced to Discord by a friend in the end of 2016. We were previously using Skype, and Discord was – even at the time – already clearly superior for our use cases. I found the “for gamers” aspect of it extremely cheesy, so much that for a while it put me off of using it as a Skype replacement. (At the time, we were using Skype to coordinate school work and talk about random stuff, and at the time, I really wasn’t a “gamer”, on PC or any other platform). I finally caved in, to the point where I don’t even have Skype start with my computers anymore, and the Android app stays untouched for weeks – I only open it to talk to the two or three people who, despite heavy encouraging, didn’t switch to Discord. It’s no longer the case, but the only thing Discord didn’t have back then was screen sharing, but it was so good that we kept using it and went with makeshift solutions for screen sharing.
As time went by, I would go on to advocate for the use of Discord, join multiple servers, create my own ones and even build a customized Discord bot for use in the UnderLX Discord server. Discord is pleasant to use, despite the fact that it tends to send duplicate messages under specific terrible network conditions – the issue is more prominent when using it on mobile, at least on Android, over mobile data.
Those who have been following what I say on the internet for longer, might be surprised that I ended up using and advocating for the use of a proprietary chat solution. After posts such as this one where I look for a “free, privacy friendly” IM/VoIP solution, or the multiple random forum posts where I complain that all existing solutions are either proprietary and don’t preserve privacy/prevent data collection, or are “for neckbeards” for being unreliable or hard to set up, seeing me talk enthusiastically about Discord might make some heads spin.
I suppose this apparent change of heart is fueled by the same reason why many people, myself included, use the extremely popular digital store, DRM platform (and wannabe Discord competitor… a topic for later) Steam: convenience. It’s convenient to use the same store, launcher and license enforcer for all games and software; similarly, it’s convenient to use the same software to talk to everyone, across all platforms, conversation modes, and topics. It’s an exchange of freedom and privacy for convenience.
Surprise, surprise: it turns out that making a free-as-in-freedom, libre if you prefer, platform for instant messaging that provides the desired privacy and security properties, in addition to all the features most people have come to expect from modern non-free platforms like Facebook Chat or Skype, while being as easy to use as them, is very difficult. Using the existing popular platforms does not involve setting up servers, sharing IP addresses among your contacts, dealing with DDoS attacks against those servers or the contacts themselves, etc. and for an alternative platform to succeed, it must have all that, and ideally be prepared to deal with the friction of getting everyone and their contacts to use a different platform. It was already difficult in 2013 when I wrote that post, and the number of hard-to-decentralize features in the modern chat experience didn’t stop growing in these five years. The technology giants are not interested in developing such a platform, and independent projects such as Matrix.org are quite promising but still far from being “there”. And so everyone turns to whatever everyone else is using.
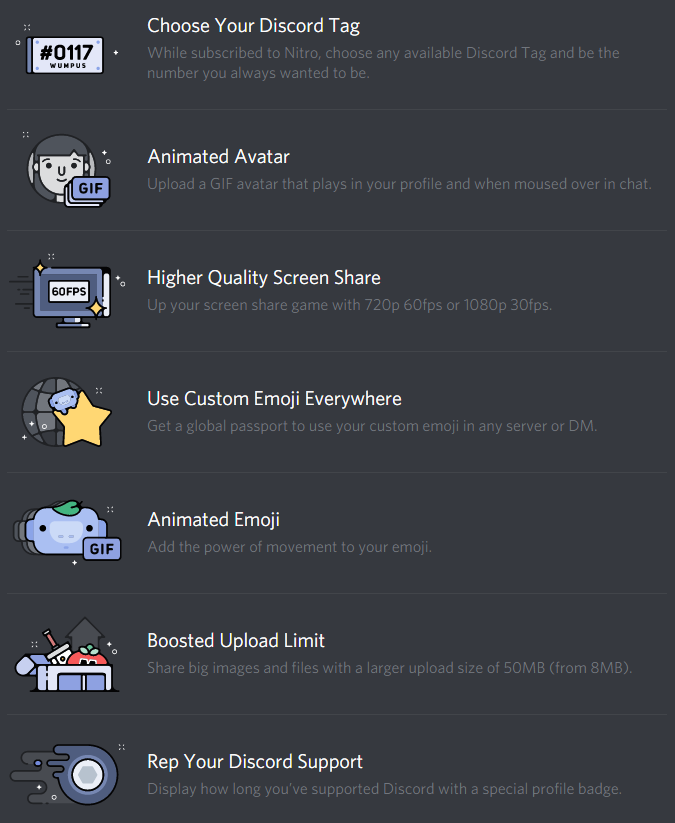
In my opinion, Discord happened to be the best of the currently available, viable solutions that all my friends could actually use. It is, or was, a company and a product focused on providing a chat solution that’s independent from other products or larger companies, unlike Messenger, Hangouts or Skype, which come with all the baggage from Facebook, Google and Microsoft respectively. Discord, despite having the Nitro subscription option that adds a few non-essential features here and there, is basically free to use, without usage limits – unlike Slack, which targets company use and charges by the user.
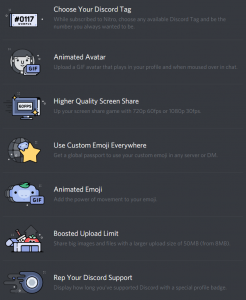
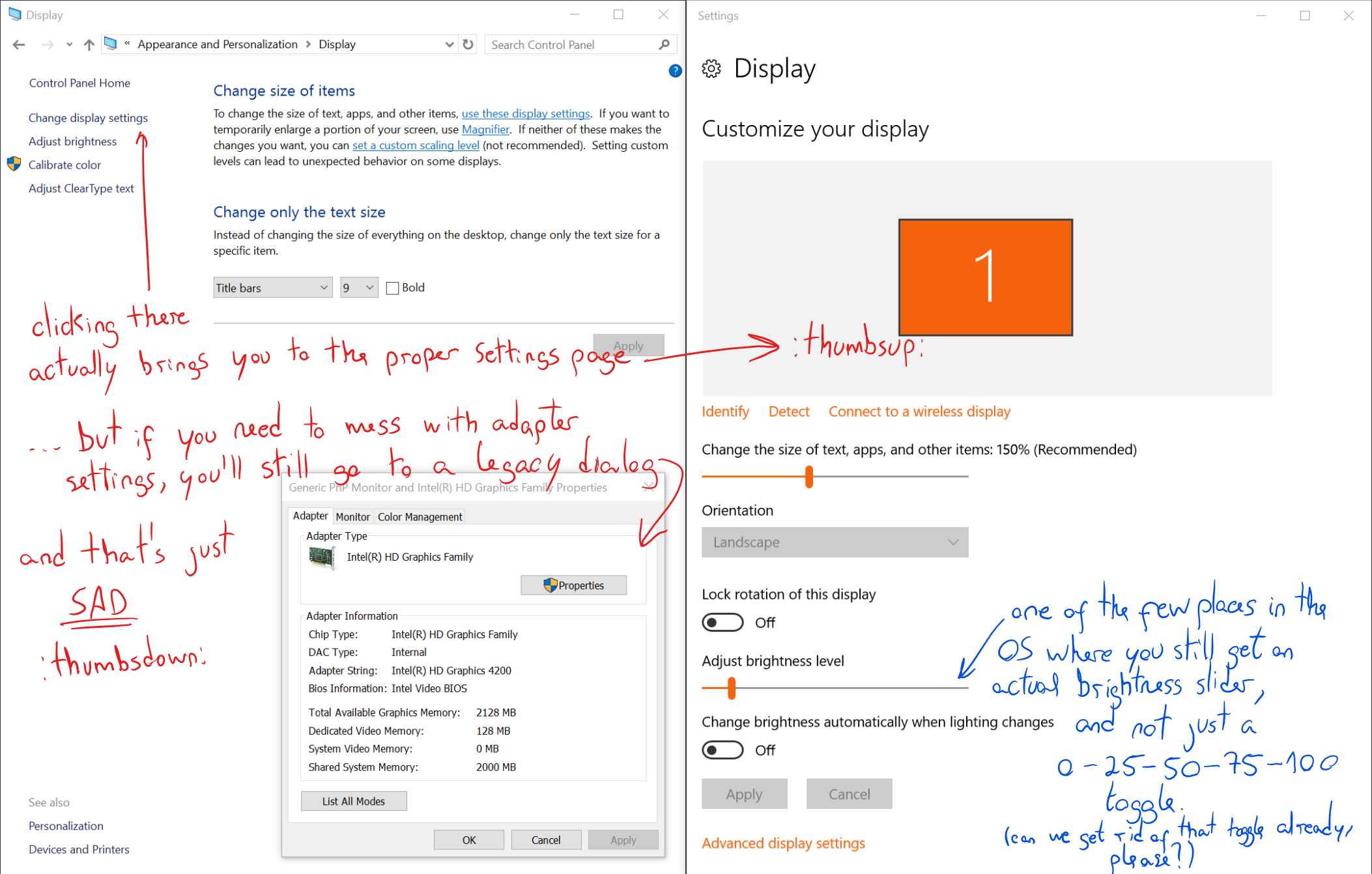
List of Discord Nitro Perks in the current stable version of Discord. Discord is free to use, but users can pay $4.99/month or ten times that per year to get access to these features.
What about sustainability, what is Discord’s business model? To me it was painfully obvious that Nitro subscriptions couldn’t make up for all the expenses. Could they just be burning through VC money only to die later? Even by selling users’ data, it wasn’t immediately obvious to me that the service would be sustainable on its own. But I never thought too much about this, because Discord is super-convenient, and alternative popular solutions run their own data collection too, so I just shrug and move on. If Discord eventually ran out of money, oh well, we’d find an alternative later.
Back to praising the product, Discord is cross-platform, with a consistent experience across all platforms, and can be used in both personal/informal contexts and work/formal contexts. In fact, Discord was initially promoted to Reddit communities as a way to replace their inconvenient IRC servers, and not all of those communities were related to gaming. If only it didn’t scream “for gamers” all over the place…
I initially dismissed this insistent targeting of the “gamers” market as just a way to continue the segmentation that already existed… after all, before Discord there was TeamSpeak, which was already aimed at gamers and indeed primarily used by them. By continuing to target and cater to this very big niche, Discord avoided competing head-to-head with established players in the general instant messaging panorama, like the aforementioned Skype, Facebook Messenger and Hangouts, and also against more mobile-centric solutions like WhatsApp or Telegram.
I believed that at some point, Discord would either gradually drop the “chat for gamers” moniker, or introduce a separate, enterprise-oriented service, perhaps with a self-hosting option, although Slack has taught us that isn’t necessary for a product to succeed in the enterprise space. This would be their true money-maker – after all, don’t they say the big money is on the enterprise side of things? Every now and then I joked, half-seriously, “when are they going to introduce Discord for Business?”
I was half-serious because my experience using Discord, a supposedly gaming-oriented product, for all things non-gaming, like coordinating an open source project or working remotely with my colleagues, was superb, better than what I had experienced in my admittedly brief contact with Slack, or the multiple years throughout which I used Skype and IRC for such things. The “for gamers” aspect was really a stain in what is otherwise a product perfectly usable in formal contexts for things that have nothing to do with playing games, and in some situations stopped me from providing my Discord ID and suggesting Discord as the best way to contact me over the internet for all the things email doesn’t do.
These last few days, Discord did something that solved the puzzle for me, and made their apparent endgame much more clear. It turns out their focus on gaming wasn’t just because the company behind Discord was initially a game development studio that had pivoted into online chat, or because it was a no-frills alternative to TeamSpeak (and did so much more), nor because it was an easy market to get into, with typically “flexible” users that know their way around installing software, are often eager to try new things, use any platform their parents are not on, and share the things they like with other players and their friends. I mean, all of these could certainly have been factors, but I think there’s a bigger thing: it turns out Discord is out to eat Steam’s (Valve’s) lunch. Don’t believe me? Read their blog post introducing the Discord Store.
In hindsight, it’s relatively obvious this was coming, in fact, I believe this was the plan all along. It’s a move so genius it must have been planned all along. Earn the goodwill of the gamer community, get millions of gamers who just want a chat client that’s better than what Steam and Skype provide while being as universal as those among the people they want to talk to (i.e. gamers), and when the time is right, become a game store which just happens to have the millions of potential clients already in it. It’s like organizing a really good bikers convention, becoming famous for being a really good bikers convention, and then during one year’s edition, ta-da! It’s also a dealership!
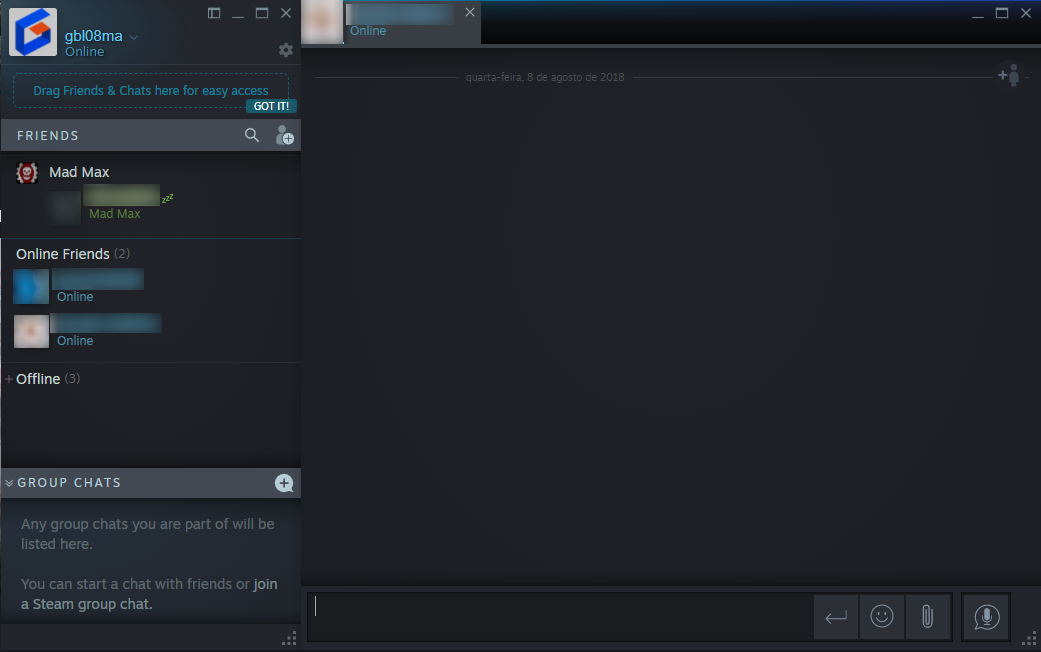
The most interesting part about all this, in my opinion, is that Discord and Steam’s histories are, in a way, symmetrical. Steam, launched in 2003, was created by Valve – initially a game development company – as a client for their games. Steam would evolve to be what’s certainly the world’s most recognizable and popular cross-platform software store and software licensing platform, with over 150 million users nowadays (and this number might be off by over 30 million). As part of this evolution, Steam got an instant messaging service, so users could chat with their friends, even in-game through the Steam overlay. After a decade without major changes, a revamped version of the Steam chat was recently released, and it’s impossible not to draw comparisons with Discord.
The recently introduced Steam Chat UI. Sure, it’s much nicer, and you can and should draw comparisons, but it’s no Discord… yet.
I had the opinion that Steam could ditch its chat component altogether and just focus on being great at everything else they do (something many people argue they haven’t been doing lately), and I wasn’t the only one thinking this. We could just use Discord, whose focus was being a great chat software, and Steam could focus on being a great store. But now, I completely understand what Valve has done, and perhaps their major failure I can point out right now was simply taking too long to draft a reply. Because, on the other, “symmetrical” side of the story…
Discord was developed by Hammer & Chisel, recently renamed Discord Inc., a game development studio founded in 2012, which only released one unsuccessful game before pivoting into what they do now – which used to be developing an instant messaging platform, but apparently now includes developing an online game store too. Discord, chat software that got a store; Steam, a store that got chat functionality, both developed by companies that are or once were into game development. Sadly, before focusing on the game store part of things, Discord, Inc. seems to have skipped the part where they would publish great games, their sequels, and stop as they leave everyone asking for the third iteration.
It is my belief that it was not too long after Discord became extremely successful – which, in my opinion, was some time in 2016 – and a huge amount of gamers got on it, that they set their eyes on becoming the next Steam. It’s not just gamers they are trying to cater to, as they started working with game developers to build stuff like Rich Presence long ago, not to mention their developer portal was always something focused not just on Discord bots, but applications that authenticate against Discord and generally interact with it. This certainly helped open communication channels with some game developers, which may prove useful to get games on their store.
Discord is possibly trying to eat some more lunches besides Valve’s, too. Discord Nitro (their subscription-based paid tier, which adds extra features such as the ability to use custom emoji across all servers or upload larger files in conversations) has always seemed to me as a poor value proposition, but I obviously know this is not the universal opinion, as I have seen multiple Nitro subscribers. Maybe it’s just that I don’t have enough disposable income; anyway, Nitro just became more interesting, as now “It’s kinda like Netflix for games.” From what I understand, it’ll work a bit like Humble Monthly, but it isn’t yet completely clear to me whether the games are yours to keep – like on Humble Monthly – or if it’s more like an “extended free weekend” where Nitro users get to play some games for free while they are in rotation. (Update: free games with Discord Nitro will not be permanent)
This Discord pivot also presents other unexpected ramifications. As you might now, on many networks all game-related stuff (like Steam) is blocked, even though instant messaging and social networks are often not blocked as they are used to communicate with clients, suppliers, or even between co-workers, as is the case with Slack. I fear that by introducing a store, Discord will fall even more into the “games” bucket, and once it definitively earns the perception of being a games-only thing, it’ll be blocked in many work and school networks, complicating its use for activities besides gaming. The positive side of things is that if they decide launching that enterprise version, this is an effective way of forcing businesses to use it instead of the free version, as the “general populace” version will be too tightly intertwined with the activity of playing games.
I’ll be honest… things are not playing out the way I wish they would. Discord scares me because now I feel tricked and who knows what other tricks they have up their sleeve. I would rather have an awesome chat and an awesome store, provided separately, or alternatively, an awesome chat and store, all-in-one. (And if the Discord team reads this, they’ll certainly say “but we’re going to be the awesome chat and store, all-in-one!”) But at this rate, we’ll have two competing store-and-chat-platforms… because we didn’t have enough stores/game clients or instant messengers, right?

Because of course this one had to be here, right? I could also have added a screenshot of Google’s IM apps, but I couldn’t bother finding screenshots of all of them, let alone installing them.
You can of course say, “just pick one side and your life will be simpler”, but we all know this won’t be the case. Steam chat is a long way from being as good as Discord, and the Discord store will certainly take its time to be a serious Steam competitor. Steam chat will never sound quite right for many of Discord’s non-officially assumed use cases; for example, even if Steam copies all of Discord’s features and adds the concept of servers/guilds, it’ll never sound quite right to have the UnderLX server on Steam, will it? (Well… unless maybe UnderLX pivots into something else as well, I guess). Similarly, I’ll be harder to “sell” Discord’s non-gaming use cases by telling people to ignore the “for gamers” part, as I’ve been doing, if Discord is blatantly a game store and game launcher.
Of course I’ll keep using Discord, but I’ll probably not recommend it as much now, and of course I’ll keep using Steam, and mostly ignoring its chat capabilities – even because most people I talk to are not in there, and most of those that are, are also on Discord. But for now, I’ll keep the games tab on Discord disabled, and I seriously hope they’ll keep providing an option to disable all the store/launcher stuff… so I can keep hiding the monster under the bed.
April 25, 2018 / gbl08ma / 2 Comments
In the introductory post to this series about the state of internet forums, I mentioned that, to me at least, forums felt like a relic of the past, a medium many internet users will never experience, and that many forums were seeing a downwards trend in the amount of activity in the past few years. But is this just a personal feeling supported by anecdotes, or is this really a general situation?
In the previous post, I also said that these posts would be subjective texts posted to a personal blog, not scientific studies. However, I thought it would be interesting to use these posts to do some introspection and try to understand where this feeling that “forums are dying” comes from. After all, it might just be that I and my circle of friends are abandoning forums, and (in a possibly correlated way) the forums we used to frequent are also dying, while the big picture is quite different. There’s also the possibility that this trend is limited to certain cultures, regions of the world, or specific forum topics/themes.
To do this “introspection”, I’ll be going through some of the forums I know about, and maybe even some I don’t know about, to see how they are doing. I have good news: you can completely skip this lengthy post and you probably will still enjoy the rest of the series. Yeah, this series will still be primarily anecdote-based, but at least we will have looked at a slightly larger number of anecdotes – and we will have taken a deeper look at them. Yay for small sample sizes. Let’s start with the ones I know about.
This forum was founded in April of 2010, and it is the first forum I remember being a part of, although I know for sure I signed up for other forums before that one – also related to web hosting, I just don’t remember their name anymore, and I’m sure that they have not been online for years now. I was one of the first 20 members of that forum, and I ended up being a quite relevant member, because I was a moderator there for over a year, between 2011 and 2012 (or even the start of 2013). I actually got through some “drama” together with the rest of the team, involving forum ownership/administration changes.
I put “drama” in quotes, because to this day I’m still not sure whether the things we were seeing as extremely serious threats were actually that serious… keep in mind that, at the time at least, most of the staff was under 20, perhaps even under 18. I know that at some point legal paperwork was flying around against us, someone wanted to trademark FreeVPS and take the forums from us, or something like that. Now I find all of this a bit cringe-worthy, but I learned quite a lot of stuff (from systems administration, to project management, time management and other soft-skills). Anyway, let’s set the nostalgia aside…
This was actually the first forum I “abandoned”, in the sense I stopped going there as frequently or participating there as much as I initially did. And thus it was only while I was “researching” for this post that I found out that this community, too, is in trouble. The activity levels are way, way down than back in the “golden days”, with what seems to be an average of five posts per day – and sometimes a day goes by without a post. Back in those “golden days”, there would be over 100 posts per day, so much that the statistics page of the forum still indicates an all-time average of 73 posts/day.
This one is not dead, it’s just… trying to find a way to evolve, maybe reinvent itself a bit, in an attempt to bring back the glory of the earlier days. Founded in 2000 – just barely after I learned the basics of how to read Portuguese (let alone write English) – Cemetech (pronounced KE’me’tek) is a community focused on graphing calculators and, to a lesser degree, DIY electronics, and other… nerd stuff. At least, this is how I saw it back when I joined in November 2011. To be fair, of all things this community had to offer and discuss, I really only ever cared about Casio Prizm discussions. After I moved on from Casio Prizm development – and at a time when forum activity was already decreasing – I tried to foment discussions on my Clouttery project, with mild but disappointing success.
Cemetech is a bit of a strange beast because, at least in my view, it hinges a bit too much on the interests, activities and projects of its founding member KermM and other staff, which to me at least, always seemed to be close friends with each other. For one example, I felt like a lot of attention was given to Casio calculators and especially the Prizm models at a time when KermM was “fed up” with TI for some reason, but once TI started releasing new models, with color screens and other features debuted by the Prizm, Casio calculators were slowly forgotten in that community. I’m sure they didn’t do this on purpose – for many years, until the Prizm was launched and caught the eyes of the staff, the community was much more TI-focused than Casio-focused, and it wasn’t unexpected to see it return a bit to its roots. Perhaps I should rephrase my sentence where I said it hinges too much on the staff’s interests… what I mean is, the staff there used to be a discussion promoter, posting a lot on every thread; since KermM kind of left to pursue his PhD and then to be a founder of a startup, Geopipe, activity levels took a hit – at least, and again, from my point of view.
This is a quite anecdotal example… not only is the community this “strange beast”, it’s also focused on the quite niche topic of graphing calculators – even though it always had so many more topics, it was calculator stuff that brought in the most people and the most posts. As a hacker’s platform, graphing calculators are dying, due to new exam regulations in multiple countries imposing restrictions on their hardware and software, and sometimes doing away with this kind of calculators entirely.
It isn’t surprising that a forum about a dying niche subject would be dying. Cemetech now seems down to about 40 posts per day… wait, that doesn’t seem very low. But if you look at the forum index alone, you’ll see that many sections have not even seen a new post in this month, and the number of topics with active discussion seems much lower to me than it once was. Oh well, maybe it’s just me – this is a subjective blog post, after all.
Yet another community focused on graphing calculators – at least initially. This one is much more recent than most of the communities around this topic, but it too has been struggling with lack of activity. In my opinion, it never had that much activity to begin with, but there’s no doubt it went through some rough months – fortunately, it seems to be speeding up a bit now.
CodeWalrus was founded in October 2014… and I’m not sure how to explain this, and I’ll probably get it wrong, but it was founded by people previously associated with Omnimaga (yet another calculator community) – including its founder – but who no longer wanted to be involved in Omnimaga. This older community is, too, pretty much inactive these days (see stats). As for CodeWalrus, which also has a stats page, things look way brighter. At least, you certainly can not accuse the members of not trying to cheer things up.
Before I move on to talking about another forum, note how I said that CodeWalrus was initially more focused on graphing calculators (by virtue of the interests of the members, not because that was the topic imposed by the administration). Well, their strategy – from the very first day – for catering to people with other interests seems to have paid off. A brief look at the active topic lists shows no posts related to graphing calculators… wow.
I don’t think this community needs to be introduced to my readers. It’s a giant community and I can’t quite take its pulse, unlike what I did with the other anecdotes in this post. With over eight million members, its scale is completely different from the other forums I mentioned so far. It isn’t a dying forum, and that’s why I brought it here: to show that definitely not all forums are dying. Or maybe only big forums survive? We shall look into that in future posts.
This forum might not be dying, but it could still be interesting to see whether the variation in number of posts and sign-ups is positive or negative. I searched, and searched, and could not find a live statistics page, or any up-to-date report. With a forum so big, it’s quite possible that computing these kinds of statistics in a real-time fashion is simply unfeasible. However, certain forum views still show the current totals at the bottom. With the help of Internet Archive’s Wayback Machine, we can plot stuff over time…
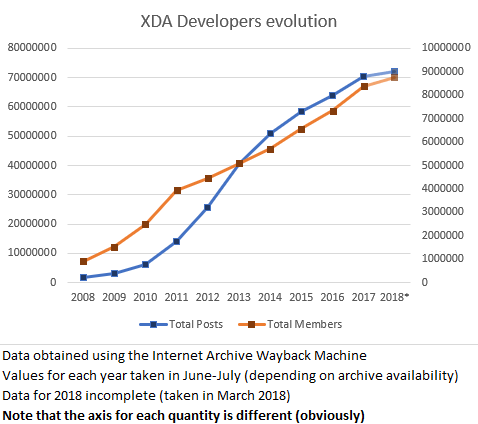
Take from that what you will… but its growth doesn’t seem to be decelerating, even if it apparently isn’t as active as it was in 2012-2013. It could also have happened that despite the slight decrease in the speed at which new posts are added, the quality of the discussion has improved, with an overall better result.
Still on the big forums league, SkyscraperCity – a community with about one million members and over 100 million posts that claims to be the world’s biggest community on “skyscrapers and everything in between”, founded in 2002. In practice, it’s a forum about urbanism that, along many international discussions, also hosts some regional sub-forums where all kinds of stuff is discussed. For example, in the Portuguese forum, you can find topics ranging from architecture and urbanism to transportation and infrastructures, and also general topics about what’s going on in the country as well as completely off-topic stuff like discussion about what’s on TV. It is at SkyscraperCity that you can find the most forum-based discussion around the Lisbon subway, for example – with over 3000 posts per year about that subject alone.
I only participate, precisely, in the Lisbon subway discussions at that forum, so even though I vaguely know about the other sub-forums and topics, I have no idea if the forum is more or less active than it used to be. Using, again, the Wayback Machine, let’s take a look at the evolution in the number of members and total posts in the last 10 years.
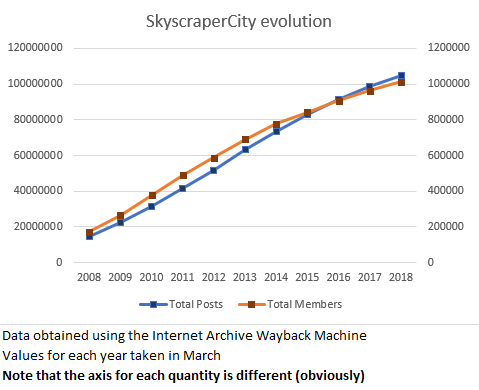
This graph is even less interesting than the XDA one. The number of members and posts has been growing essentially linearly. There is a slight deceleration in the last three to four years, especially in the member count, but that could be due to better spammer detection systems (something as simple as a better captcha system could have that effect).
SkyscraperCity is yet another forum that, despite using antiquated software and not having the best availability or reliability history, doesn’t seem to be going anywhere. It isn’t displaying “exponential user growth” like investors and shareholders like so much to hear. But hey, one of the nice things about forums, is that generally they don’t need to boost user counts like that, because they don’t typically have shareholders to report nice numbers to.
Looks like we’re back to the subject of web hosting. LowEndTalk is the discussion forum of LowEndBox, a website that lists deals on low-spec virtual and dedicated private servers. I never participated or followed this forum in any way, but I have known about its existence and have had a good idea of its “dimension” for almost as long as I have known about FreeVPS.
LowEndTalk makes my job a bit hard because, as far as I can see, they don’t list the total number of members nor the total number of posts anywhere. Fortunately, they do show the total number of threads (or “discussions”, as their forum software calls them), rounded to the nearest hundred. Let’s see if we can get any sort of trend out of this. Wayback Machine to the rescue…
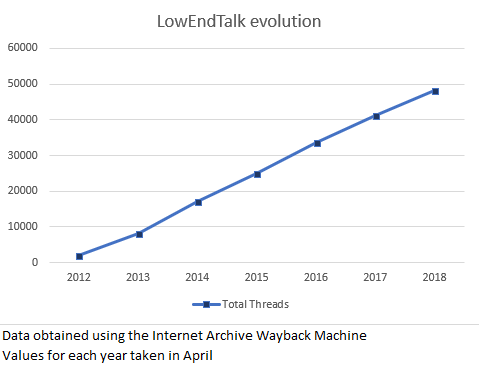
Judging by the thread counts alone, looks like LowEndTalk is yet another forum that isn’t going anywhere, with over 7000 new threads being added each year. The chart gives the impression that growth is slightly more linear than it actually is: the rise in the number of threads is actually slowing down a bit, from an average of about 8700 threads/year in 2013-2015 to about 7500 threads/year from 2015 to the present. Nothing to worry about.
You might be wondering why I brought LowEndTalk here, since it’s not an especially big or especially well-known forum, and it’s not a forum I frequent, either. The reason is that during my “research” for this post, a few things caught my eyes when looking at LowEndTalk.
For a start, their forum software (Vanilla Forums) is not one I commonly see in the wild, or at least one that I recognize – despite the fact that according to Vanilla Forums, they are “Used by many of the world’s leading brands”. At least in its LowEndTalk incarnation, it is extremely “clean”, simple and still good looking. It’s not “responsive” web design, but it’s very readable and fast. It’s definitely different from your run-of-the-mill SMF/phpBB/MyBB-powered forum. But is it better? We shall look into this in a future post.
LowEndTalk only became a “traditional forum” in 2011. Before, they were a Q&A website (like StackOverflow, for example) powered by OSQA. Using the Wayback Machine, it’s easy to see that some of the hot topcis were discussions about moving from OSQA to something more appropriate to their needs. Therefore, this community has yet another interesting quirk: they were not born as a “traditional forum”, they actually moved into one after the community was already bootstrapped and a Q&A model was deemed inappropriate.
LowEndTalk have recently set up a Discord “server”. Unlike what seemed to be the plan at CodeWalrus at one point, it is apparently not their intention to move discussion out of the forum and into Discord. Still, I think this is an interesting point for a future post about forum alternatives – what are people moving to, after all?
Including this one here is pretty ridiculous, but I thought I’d do so anyway, even if only as some sort of honorable mention to the thousands of small forums hosting communities of developers and users of open source projects. I feel that these kinds of forums, along with self-hosted issue trackers (such as Flyspray or Trac) were a much more common sighting in the distant past before GitHub.
Anyway, what is Rockbox and their forums? Rockbox is an open-source firmware for that ancient thing smartphones made us forget about, the MP3 player. You know, of the old-school iPod-with-clickwheel kind.
I used Rockbox for a couple years on the 2nd iPod Nano my parents won in some sort of raffle and which they never really heavily used. iTunes made it a PITA to use it; my family (unlike me) isn’t that much into listening to music and maintaining a music library; and finally, my dad was into PDAs and Pocket PCs way before the iPhone even launched.
For us, the thought of playing music on a MP3 player was already kind of strange even when that iPod was brand new – why go through the hassle of using iTunes, transcoding music files, having to charge and carry around yet another device… when we could just take a full-size SD card, insert it into one of these ginormous Pocket PCs (which also made phone calls) and listen to our existing MP3s and WMAs (no M4A transcoding required!) using Windows-freaking-Media Player on Windows Mobile (or any other player of our liking, since those phones could run arbitrary EXEs compiled for Windows Mobile, and many player application alternatives existed).
Anyway, to finish telling yet another personal story of my life: I found out about Rockbox at a point when the iPod was already forgotten in a drawer. Long story short, that iPod got 500% more use ever since I installed Rockbox on it. Rockbox can even run Doom and has a Gameboy/Gameboy Color emulator, how awesome is that? (And no, Rockbox is not Linux-powered, but there was a separate project which ported Linux to some older iPods.) Sadly the capacitors on my iPod’s screen have failed and only 30% of the screen is readable now, making it a bit hard to use the device.
I would still use that iPod to this day if it weren’t for that malfunction (which I don’t feel like spending $10 on a new screen to fix): the iPod has just 4 GB of storage, but Rockbox can play Opus, the awesome audio format that’s simply the best in terms of quality/filesize ratio (and I hope this sentence will look extremely dated in 10 years). I can fit the relevant part of my music library in there by converting over 10 GB of high-quality MP3, M4A and FLAC into less than 4 GB of Opus at 96 kbit/s – which sounds great.
Rockbox, as you might guess, is pretty much dead these days. It never got to the point where it supported the most recent MP3 players or the latest iPod models, thanks to Apple and their locked bootloaders. MP3 players became a niche/audiophile product as people moved on to smartphones and the demand for them dropped; the prices went up as a result. Perhaps most importantly, if it weren’t for the fact that it could support more devices, Rockbox is a finished product: it can play any relevant music format (including tracker music), it has everything you could possibly want from a music player in terms of sound effects/adjustments, playlist control and library browsing. And now for something that might take you off-balance: Rockbox is a project by Haxx – yes, the same Haxx of the extremely popular and successful program curl! In fact, there is a noticeable overlap between both development teams. Both are awesome pieces of software.
I just realized this post was supposed to be about “forums” and not “alternative firmware for embedded devices and opinions about sound formats”… shit. Anyway, Rockbox is dead and, surprise! the forums are pretty much dead too, for obvious reasons – it would be quite interesting if the forums outlived the open source project they were built around, but it doesn’t seem like this will be the case, and I never saw it happen.
Conclusions
Maybe forums aren’t dying left and right like I thought they were. But they don’t seem to be growing as fast as the rest of the internet. IDK, at this point I’m just making stuff up because I don’t know how fast “the internet” grows. Perhaps it has to do with that shareholder thing, forums don’t usually have to report inflated numbers to anyone. Or maybe people are really locked down inside the bubble-decorated walled-garden of the EVIL ZUCC. Yeah, let’s pretend that is the case, so that my plans for the following posts are not completely foiled. As for this pointless anecdote-based post, its end is here.
BTW: did you know I started working on this post on the 7th of March… only to leave it rotting unfinished since the 9th of March… and finally finish it today? But it’s fine: this way, I could include a ZUCC reference while people are still outraged at Facebook, and before they go back to using it again happily ever after.
March 2, 2018 / gbl08ma / 4 Comments
Internet forums… websites and communities where I spent thousands of hours. To me, they already feel like relics of the past. I’m 21 and began using the internet about 10 years ago, maybe more. I’m sure the majority of kids who are now starting to browse the web (probably at earlier ages than I was) will not participate in a classic forum, perhaps not even land there through some random search. You know, the kind of discussion websites where there are threads, posts, moderators and rules, things are typically ordered in chronological order, and reactions to posts (“votes”, “likes”, and similar) are either unavailable or something added to the system as an add-on rather than a core mechanic.
In recent years, even I – someone who used to be staff on a medium-sized forum, FreeVPS – have withdrawn from most forums where I used to actively participate. Many of my friends who know what a forum is, either never got to participating in one, or are now participating much less than they used to do two, three, four years ago.
In recent months, it has come to my attention that some of the forum-based communities I frequented are facing serious drops in activity levels, sometimes to the point where days go by without a post, where previously there used to be at least one post per hour. While this reduction in activity is in part because the main topics of those forums are becoming more and more niche, I believe a big chunk of the problem has to do with the fact that they are, well, forums. The lack of activity has even led to meta-discussions on new directions and ways to bring life back to these communities – see the threads at Cemetech and CodeWalrus.
This is the first post of a series of blog posts where I’ll look into the state of forums in today’s web, identifying what alternative discussion formats and platforms exist, why users seem to prefer (or hate) them, and what is the role of forums nowadays and what they can still do better than other mediums. With this being a blog and not a scientific study, I will obviously write from my own experience and the experience of my peers, producing subjective, unverifiable but hopefully enjoyable content. I’ll also provide my opinion on why forums are still necessary, and give suggestions on how forum-based communities become more appealing to today’s web users.
With this, I hope to be able to bring some life and schedule to this blog – blogs, which are another medium that is nowhere as popular as it once was… maybe I’ll look a bit into that too. This post will act as the index of the series, so links to new posts will appear here once they are published. Stay tuned.
Series Index
January 15, 2018 / gbl08ma / 0 Comments
If I haven’t posted much here, it’s in part because the masters degree I’m pursuing is quite demanding, and in part because my “creative writing” time is often spent replying to interviews for Portuguese national media (and dealing with the exposure, which sadly is not expo$ure) about my UnderLX project, over the last few months:
http://www.sabado.pt/portugal/detalhe/as-perturbacoes-no-metro-de-lisboa-sao-tantas-que-inspiraram-uma-app
https://www.noticiasaominuto.com/pais/937964/linha-mais-problematica-horarios-pico-de-falhas-app-poe-o-metro-a-nu
…and with more to probably come 😉
December 21, 2017 / gbl08ma / 0 Comments

“We’re adding another dimension to computing.”
Cliché and meaningless, but go on. I guess this is something revolutionary…
“Where digital respects the physical.”
Because, currently, digital somehow violates the laws of the universe?
“And they work together to make life better.”
“they”? who’s “they”? Oh, digital and physical, sorry. You really should learn to use commas instead of periods. So the digital and physical work together, uh? My guess is that this is about a robot.
“Magic Leap One is built for creators who want to change how we experience the world.”
Finally, now you’ve told me who it is for, and it probably helps to “change how we experience the world”, because it’s for creators who want to do that.
You still haven’t told me what it is or what it does, and bonus points for jamming the “creators” cliché in there! Congratulations, you have passed your final assignment in Unicorn University  of Shitty Vaporware Descriptions
of Shitty Vaporware Descriptions  with the grade of: flying colors
with the grade of: flying colors  !
!
October 10, 2017 / gbl08ma / 2 Comments
A few years ago, I was very active in the Casio Prizm development community, having developed three notable add-ins, contributed to the Prizm wiki, libfxcg (my fork), and even done a bit of reverse-engineering (the calculator OS is closed-source and there is no official SDK), that resulted in the discovery of a couple of syscalls and more detailed documentation on some other ones. Because of this, once in a while I still get messages about my add-ins, which I’m happy to support when possible. Most annoyingly, I also get messages about Prizm development, usually about how to start making add-ins.
Why are these messages annoying? Because I don’t really know how to answer. When I started developing add-ins for the Prizm, I had little to no knowledge of the C programming language, and yet, despite the fact that add-ins can’t make use of all the stuff “normal” C programs can (the libc provided by libfxcg is incomplete; the filesystem uses a different API, there’s no threading, the stack is giant compared to the heap, etc.), I managed to learn it. It certainly helped that I had some previous experience with programming in other languages, even if it was just sloppy code, but I don’t have much of an idea of what to say to someone who intends to learn programming using the Prizm.
I usually end up saying that learning programming using the Prizm it’s a bad idea, probably coming across as extremely discouraging. However, I do hope it’s for the best, and that these people will still learn programming – just not by developing add-ins! Had my first contact with programming been through Prizm add-in development, most certainly I would have chosen other career path than computer engineering. I mean this seriously. I’m glad my first contact with programming was through sloppy Visual Basic code. Anyway, I already wrote a post on my programming experience – it needs updating, but it should do.
Learning how to program, even in a “easy” language and common platform, can be overwhelming; for a programmer that is used to higher-level programming, learning the Prizm, a poorly documented platform with a small developer community, can be overwhelming; combine learning how to program with learning a poorly documented embedded system, and it will most likely be very overwhelming. Of course, nothing will stop someone extremely motivated – hopefully, not even my less encouraging replies, or this blog post.
What follows is the partial reproduction of an email I recently sent, in reply to yet another of these inquiries on how to start developing for the Prizm. I have edited it to make it less specific to the situation of the person I was replying to. I’ll also use the terms “Prizm” and “fx-CG 50” interchangeably, as add-ins built for the former run, with a few exceptions due to sloppy coding (one of mine’s one of these exceptions…), on all Casio Prizm models: fx-CG 10, fx-CG 20 and fx-CG 50.
Do you have any previous programming experience? If not, I honestly do not recommend starting with the Prizm or any other Casio graphical calculator. If yes, then be aware that this is not an “easy” platform to develop for. Either way, here are a few reasons why:
- Prizm add-ins are written in C or very limited C++ (that might as well be considered C). By today’s standards, these are very low-level languages that require manual memory management and a very good awareness of the machine. They also provide very little protection from programmer mistakes. While some people had C as their first programming language, it is by no means a beginner-friendly language.
- Even if you already know C well, or if you learn it from any common book, tutorial or course, you’ll be disappointed to find out that much of the standard library is not present, or is insufficiently implemented, in the Prizm calculators.
- Add-in development for the Prizm was made possible through reverse-engineering and educated guesses based on what was known about previous models like the fx-9860G. While we now understand the essential things about the OS on these calculators, many things are yet to be known.
- Documentation is lacking and the community is not very large. This essentially means that you won’t be able to just google your way through many problems.
- Reverse-engineering/documentation and development efforts for the Prizm have basically stalled. You’ll also find many materials that mention the fx-CG 10/20, but since the fx-CG 50 is basically just a faster version of these with a mostly compatible OS (although some things like memory addresses have changed), almost everything you’ll ever need will still apply.
Now, I’m sorry if I came across as dismissive or as discouraging, I’m just trying to make sure you know what’s in front of you.
For Casio Prizm development specifically, this is where I can point you:
Prizm forums at Cemetech
Use these to ask any questions you might have and try to find solutions to any problems you encounter. There are also some guides there, mainly on how to set up the development environment (compiler and such), but I’m afraid they might be a bit out of date. However, as I said, development efforts have mostly stalled, so consider anything from 2014 or early 2015 as up-to-date. Specifically, do not follow the “[HOWTO] Prizm C Development” in there, as it is out of date.
Prizm wiki
This wiki contains much information on the calculator, the reverse-engineered OS functions (“syscalls”) that can be used from add-ins, etc. It also contains more up-to-date instructions on how to set up a development environment.
Personally, I have mostly moved on from Prizm development about three years ago, as I began pursuing a degree in Information Systems and Computer Engineering. Every year or so, I make a short comeback to fix urgent issues with my add-ins and eventually make them compatible with new OS versions and calculator models, as is the case of the fx-CG 50, as long as that does not require too much time/effort. As time passes and I work with other technologies, the more I realize more how “hard” of a platform the Prizm is, and the less motivated I am to build stuff for it again; the fact that I no longer use my fx-CG 20 nearly as much since high school, also doesn’t help.
I’m afraid I can’t help you much more, as I’ve forgotten much of what I knew about the Prizm, both the “theoretical” and “practical” knowledge, and I no longer have practical access to a development environment for it. I tried to put as much of my knowledge as I could into the Prizm wiki before I left, and I believe that the people that now frequent the Cemetech forums will be able to help you much better than I can.
I think that one day I might find some interesting in working on the Prizm again, but perhaps more from a reverse-engineering angle. As for the fun in developing for a constrained, embedded system, there are much more appealing constrained systems out there, like the ESP8266.
September 2, 2017 / gbl08ma / 0 Comments
I neglect this blog very much. I write a non-negligible amount of stuff on the internet, but it’s usually on forums, Reddit, Hacker News and similar, and this blog ends up forgotten. I just wrote a 2000 words post on at CodeWalrus, about the current state of Clouttery, but since it also contains a personal-life-log part, I thought it would be the perfect thing to cross-post here. It’s not the first time I paste forum posts here, and it’s something I should probably do more often, as it helps keep this blog alive while at the same time preserving posts that, while usually made as replies to a forum topic, are general enough to stand on their own.
Hello everyone again. I figured it was time for an update, even though this is not exactly a “happy” update, at least as far as Clouttery is concerned. This is a long post, bring it to bed so you can fall asleep to it if you wish, but trust me, it’s worth reading. I hope you can learn a thing or two about managing your side projects, from reading about my mistakes.
Last school year was the last year of my undergrad course (and I’m starting a second cycle course in a couple weeks) and this required some more effort, so I had less time for side projects. As often happens when one works on something for an extended period of time, I too gradually lost interest in this project.
To make things more… interesting, in mid-March I launched a small website that was meant to be kind of a practical joke about the unreliability of the Lisbon subway (for those who haven’t yet figured it out, I’m Portuguese). You’ll be able to understand what it is about by checking out its repo on GitHub.
I started that project mostly to have something different to work on that was not Clouttery, and the original plan was for it to be something I’d build in a few weeks, publish and then forget, for it to be yet-another-small-thing in my portfolio. But to my surprise, after minimal “marketing” on the SkyscraperCity Portuguese community, that has a section dedicated to railways and subways, my website received a lot more attention than I was expecting, especially for something so simple and tongue-in-cheek.
I then understood there was a real interest in a service that would let people work-around the problems in the Lisbon subway, while at the same time denouncing the problems with the service (for example, by collecting independent statistics). Long story short, a small community assembled around this project, which ended up evolving into an Android app called UnderLX that’s even published on Google Play. And there’s still a lot of work to do for it to become the product I envisioned.
This obviously took most of my summer.
Yes, it’s true that, unlike Clouttery (for which I had even written a complete billing system from scratch!), I’ll never be able to monetize UnderLX effectively. However, it is way more satisfying to work on, at least until I get saturated of it too. With Clouttery, it often took a while to realize what it was about, and let’s be honest: the final reaction of many people was just “meh”. However, with UnderLX, people tend to pay a bit more attention, and those who understand the whole potential of the project usually become much more involved in it. “Unfortunately” for me, the technical side of it is more complex than Clouttery.
It also has an “advantage” to my eyes: both the client (Android app) and the server are open-source from the first day. I regret not going this route with Clouttery; now I have lots of closed-source code which I can’t easily show to anyone because, well, it’s in private repos. I’ll go back to this point, later.
Finally, to add to the school work, the gradual loss of interest, this happy accident that was UnderLX, there’s a fourth factor in all this. Because of multiple reasons including the astronomical rise of the price of Bitcoin, it made economical sense to fulfill a long-time desire of mine: to build a desktop, so I could have a powerful machine, more powerful than my six-years-old laptop. Picking parts and putting it together was very enjoyable, and now I have a proper workstation like I had been dreaming of for the past couple years. If you are interested I might even post a thread about it here. I wasn’t much into PC gaming before (in part, because the hardware didn’t really allow for it), but… you see… to sum things up, many hours were spent chilling to some great triple-A titles (thanks Steam summer sales!…). 
That’s all really nice, but I thought this topic was about Clouttery?
Work on Clouttery gradually slowed down through the last months of 2016, subject to how busy I was with school, and pretty much completely halted in March this year, as I got more and more tired of working on it, so I decided to do that “small” subway thing. It also didn’t help that I was going through a complex phase with Clouttery, more specifically regarding the Windows and Linux clients.
- I couldn’t get the Linux client to work right, despite trying to develop it from scratch multiple times using different languages and technologies. No matter what I tried, there were always major roadblocks to getting it to the point I wanted. I did not want to write it in C or C++; I hate Python but decided to try using it anyway – didn’t end well; UI framework bindings for Golang are apparently all terrible, or don’t have a suitable license. Mono would have been a viable choice, but the gtksharp bindings were tricky to get to work, they apparently had to be recompiled for each GTK version (meaning I couldn’t simply distribute a single binary), and the bindings for GTK3 aren’t/weren’t exactly ready for prime-time. Ugh, I don’t even know what all the problems were anymore. I do remember that I just wanted to write code, but problems with libraries and bindings and whatever were always getting in the way.
- The UI of the Windows client suffers from major lag and other problems, so I decided to switch from WinForms, which is no longer supported, to the supported and way more modern and flexible alternative: WPF. But this was taking a lot of time, certain things were much harder to get to work than I expected, it didn’t help that I only had time to work on it like one hour at a time (school work, etc.), and I lost more and more interest.
For you to get an idea of how inactive this project has been, these are the dates of the latest commits to Clouttery repos:
- Server: 2017-07-10 (and this was only to fix a bug with notification filtering; previous “real” work on it had been on the 23rd of March)
- Windows client: 2017-03-26
- Android client: 2016-12-29
- Chrome client: 2016-09-08
- Linux client: 2017-03-09
Earlier, I mentioned I regret not open-sourcing Clouttery from the beginning. I decided to work on it privately, because it was supposed to become a commercial service, and I feared that if I made it possible for people to host their own Clouttery servers and recompile the clients to talk to it, then nobody would pay for the service. This is obviously a stupid way of thinking, especially when the project in question is a personal project of a student that doesn’t have much time to work on it, and likely would never be able to get it to a commercially-viable state. If the service was worth it, I guess most people would happily pay for it, just to not have the hassle to figure out how to make the server and clients work for themselves; this is especially true since the target audience wasn’t exactly software developers nor sysadmins, i.e. it was people who wouldn’t have a clue how to do that nor would bother even if they were given clear and easy instructions.
Right now I have 30K lines of code, possibly more, that’s closed-source, but for no good reason. To aggravate things, Clouttery shows more of my abilities in software development and engineering than any of my open source projects, because it contains code in more languages, for more platforms, than any other of my projects; it includes web design, API design, use of cryptography, etc. It is not the most beautiful code (for example, the UnderLX Android app has much cleaner and organized code than the Clouttery client, and even then it’s not exactly stellar), but it works, and definitely shows what I’m capable of.
This whole situation is even more ridiculous, because right now there’s very little to no code in Clouttery that’s “novel” to the point of requiring intellectual property protection.  At this point, Clouttery is extremely dumb, as I never got to work on the “intelligence” that would involve machine learning, pattern matching and the like. And in the end, if I wanted to make my super-awesome-and-courageous battery level prediction and damage identifying algorithms secret, I could always have added them as a closed source module while keeping the “infrastructure” open source.
At this point, Clouttery is extremely dumb, as I never got to work on the “intelligence” that would involve machine learning, pattern matching and the like. And in the end, if I wanted to make my super-awesome-and-courageous battery level prediction and damage identifying algorithms secret, I could always have added them as a closed source module while keeping the “infrastructure” open source.
Finally, I always told people that if I were to stop working on Clouttery, I would release its source code. I don’t know what you think, but if I half-close my eyes and look from far away… yeah… like that… yep, I definitely stopped working on it. 
Then why don’t you open source Clouttery?
I definitely want to open source Clouttery, so I can show its code to more people, and so that others may eventually try to pick up on the project. I intend to keep running the official Clouttery server – if for no one else, for me, as my family finds Clouttery useful. I think I would be a little sad if someone took the project and simply changed its name and started running their own “official” service, available to the masses and possibly profiting from it, so I’ll see what kind of licensing restrictions I can add to prevent that. Without the help of a lawyer, it’s a bit hard to add clauses to existing software licenses or write new ones from scratch; even with legal help, it’s easy to get to a controversial result – for example, Facebook has that famous problem with the “patents” file on their open source projects, like React.
…so why didn’t you do it already?
Because ideally, I’d like to publish the source code with the complete commit history. The problem is that, in the past, secrets (API keys and the like) have been committed to the repos. If I remember correctly, the latest server code no longer has that problem – keys are read from a separate, uncommitted file and no longer stored in the source code, but going back in history the secrets are still there. Some of these secrets are hard to revoke and replace, and I’ll need to go on an individual basis to see what can be done about them. Furthermore, the clients also contain secrets in their repos, but this is just one secret per client that’s used to authenticate the client before the server, and since it’s relatively easy to get these secrets from the binaries anyway, I might just go and make them public anyway – their only purpose is to stop people from using the official server with unofficial clients, but if the whole thing is going to be open source, that doesn’t make much sense. These secrets are not involved in securing the pairings between clients and user accounts, so in terms of user account security, there’s no problem with publishing them.
I also need to write a bit of documentation explaining essential things about each repo, and ideally also explaining how to run the server, what needs to be in the database, etc. Or I could not care about any of that, and just have people figure it out by themselves – at that point, I make it hard for people to contribute, but at least people can already look at the code, which is much better than the current situation.
As you can imagine, all this takes time and effort, and I’ve been busy with all those things I mentioned in the first section. But with classes starting very soon, I’d like to get this going ASAP, or it’s not going to be done for some more months.
Did I “give up” on Clouttery too soon?
Is it a good idea to open source it, even if in the distant future I decide to turn it into a proper commercial service?
Do you agree it would have been better if it were open source from the beginning?
What license do you think would be most adequate? – don’t forget the server and each client can have different licenses.
Would you be interested in submitting pull requests for this project, perhaps even taking over one of the sub-projects or the whole thing?
Share your thoughts.
February 19, 2017 / gbl08ma / 0 Comments
I spent the past week, the last one of my winter break, redesigning how the Clouttery server stores data.
The Clouttery server, which is written in Go, was using a simple key-value store (Bolt). I slowly came to the realization that some of the features on the roadmap would be kind of hard to implement using Bolt; that the nested buckets structure used with Bolt was too limiting, by forcing a hierarchy on the data, when sometimes it could be useful to interpret it in other ways. For example, sometimes it could be useful to look at all the battery log entries from all users; with the database structure I had, that required looking into each user’s bucket separately, and within those, into each device separately.
The databases course I took last semester forced me to get my hands very dirty with SQL, and after seeing the benefits, I decided to move to a relational database.
Another reason for moving was that Bolt can’t scale (no replication, it’s meant for use by a single app, like SQLite), and while the server software is not yet ready to be clustered, moving away from Bolt (and, in general, uncoupling the server from the database) is a giant step towards the goal of being able to scale the server to multiple nodes. I had known for long that I had to use something other than Bolt if I wanted to make the server distributed, I just wasn’t sure whether to move to a relational database, another barebones key-value store, or some amalgamation of solutions involving specialized time series databases or what-have-you.
The database can now be accessed transparently by multiple applications, which means that, for example, in case I want to do some complex analysis on the battery histories, I no longer have to stuff that code into the server. I can even use a language other than Go, like Python, which I really don’t like, but has many libraries for data analysis.
I tried to use CockroachDB (and I can’t stress the terribleness of that name enough). At some point, the server was mostly ready to work with it, and it was time to import the data from the Bolt database. My code migrated all data in a single transaction, that was rolled back in the case of errors – that way, as I stumbled upon problems and general incompleteness in my migration code, I did not have to be constantly dropping and recreating the database, as with every failure the database would be always supposedly in a pristine state, with all the empty tables waiting for data.
Let’s just say things were not as smooth as I was hoping. On my laptop with an aging but still plenty fast i7, 8 GB of RAM and a SSD, data would get into CockroachDB relatively fast… but no matter if the transaction was committed or rolled back, once I tried to perform any query – basically any query, even if just counting the amount of users (about 40), would make CockroachDB’s RAM usage skyrocket, to the point where the whole system just hanged for seconds at a time, due to how much swapping was going on.
So I decided to scrap CockroachDB and go with plain old PostgreSQL. Given that the SQL supported by the former is relatively similar to what PostgreSQL supports, changing the queries to work with Postgres was not too hard. The most annoying part is the lack of support of PostgreSQL for the UPSERT command, which in CockroachDB and other databases, behaves like a INSERT when there’s no uniqueness conflict, and like a UPDATE when there’s a conflict (in which case it will update all the other columns). I had about ten UPSERTs that had to be rewritten as INSERT … ON CONFLICT (…) DO UPDATE SET – followed by all the columns to update. Ugh.
Importing data into Postgres was noticeably faster than into CockroachDB, and most importantly everything kept working fine after about a million entries were in the battery history table. And yes, everything was still inserted in a single transaction.
I took the opportunity to perform some long-needed changes to the data types used by the server. Making sure Clouttery clients kept receiving data with the formats and semantics they were expecting was a bit of a challenge, but very easy in the grand scheme of things.
As a very nice bonus, the server now does transactions properly. Previously, for a single API or website request, multiple Bolt transactions could be made. If something went wrong with one of the latter transactions, that one would be rolled back and no more transactions would be performed, but the changes done by previous ones would stay – like most databases, Bolt doesn’t let you rollback a committed transaction. Obviously, this could result in an inconsistent state.
Now, and after changing most functions in the server code to accept what can be described as a “transaction node”, each API request, web console request, or admin command works in a single transaction. Either there’s no error and everything goes through, or everything is rolled back. No more inconsistent data. sqalx was the library used to implement this.
The changes were pushed to production about two hours ago – after extensive testing on the staging environment, which unfortunately didn’t catch all the bugs. To identify problems, there’s nothing like dozens of devices running different clients and submitting different data to your server…
A few hotfixes later, everything appears to be working fine, but I’ll be keeping a close eye on the logs where, hopefully, all errors are logged. I say “hopefully”, because during testing I found out that the error return values (in Go, errors are values) from some of my own functions were not being logged, and some were completely ignored…
It would be great if over the next few days users could pay a bit more attention to the behavior of Clouttery, namely making sure that battery histories are updating as they should, and that notifications are generated when they should, according to their settings.
I’m probably a bit too much proud of this – at least, until I find a horrendous bug. This is how things should have been from the start, but at the same time, when I started this project, I did not know enough about relational database design to even do a mediocre job. So I went the easy, “no SQL” route and just used Bolt, which allowed me to get to something that worked, relatively quickly. And now I’m glad I could turn it into something better after about 60 hours of work…
I barely have time to work on Clouttery, and it becomes less and less of a commercially viable project as time goes by. It’s one of those projects that seems to never leave Beta status, and not for good reasons. But oh boy, the things I learn…
December 19, 2016 / gbl08ma / 0 Comments
I was casually going through my GitHub repos and came across PicoRed, a server redundancy manager I developed, with the immediate goal of managing the DNS records for the tny.im domain. The tny.im shortener used to be hosted by multiple servers in a Round-robin DNS configuration. The idea was that as servers went online and offline (or underwent maintenance, etc.), the DNS records would be automatically updated to reflect which servers are currently serving a service, in this case tny.im.
PicoRed is the successor to mersit, which served the same purpose but was written in very unidiomatic Python and was much clunkier than PicoRed (which is written in very unidiomatic Go, but used fewer resources and was somehow more stable). PicoRed and mersit were completely peer-to-peer, and this is because I couldn’t afford to have a “master” server that was stable enough and which I could be sure would have three nines of uptime.
The idea behind those tools is everything but novel; container orchestration, for example, requires similar tools to be deployed. For some reason, perhaps ignorance, back then I decided to write my own. (For an example of mersit/PicoRed done right, see Serf). I don’t regret it, of course: I learned a lot about distributed systems, and while my terrible consensus “algorithms” (a complete joke) worked, they taught me why things like Paxos and Raft had to be invented. The main takeaway was, “it’s complicated”. So for PicoRed I decided to use a library by Hashicorp that handled the hard parts for me (and that’s how my unidiomatic Go program was “somehow more stable”).
Three paragraphs into this post, and I’m still writing the introduction… these three paragraphs about distributed systems are just warming up for what’s coming, which is me saying that none of those homemade tools are in use anymore, and it’s not even because I switched to something better: tny.im, and some other services of the TNY network, are now served by a single server.
How did we get here? Back in 2014, I was a huge proponent of distributing every single service across many cheap servers, instead of buying a proper, rock-solid, big and expensive server from a reliable company. In theory, horizontally scaling would let one handle big amounts of traffic and improve availability at the same price, or even less – sounds great, right? These strong opinions were backed by the issues I was having with my BlueVM server. But now, we’re back to zero redundancy… what changed?
Well, my opinion is still the same: I’ll take horizontal scaling over vertical scaling any day, and the more redundancy that’s fit to pay, the better. The problem is when horizontally scaling begins to hurt performance and reliability instead of helping it, and that’s exactly what was happening in our case.
tny.im, dotAccount, PrizmID and my WordPress websites (this blog and the TNY network website) are powered by an extremely uninteresting LEMP stack. A LEMP stack is one composed by Linux, Nginx, MariaDB and PHP, or in other words, a LAMP stack but with Nginx instead of Apache. Until a few weeks ago, the “M” in this stack had the peculiarity of actually being MariaDB configured in master-master replication mode. What this means is that MariaDB was running on multiple servers, managing the same databases, and whenever a change was made, it was propagated to all of the other servers in the cluster (up to a few weeks ago, two servers; at some point in the distant past, up to five servers were used).
That’s how tny.im was served by multiple servers: simply by running the same PHP code in all servers, and having that code talk to the same database, replicated across all the servers. Of course, MariaDB master-master replication has its disadvantages. For one, performance is worse, because all database writes involve communication between the different MariaDB servers. This began to show on more database-intensive applications like dotAccount.
Perhaps more surprisingly, reliability is also worse. Perhaps I didn’t have MariaDB replication properly configured (after many attempts and hours spent, trust me), but it would sometimes break in wonderful states such as “WSREP has not yet prepared node for application use” whenever there was some network hiccup. This could happen as often as once a day, or once every two months (yes, networks are unpredictable like that). Whenever it broke, it would need to be manually restarted, and it would sometimes take multiple attempts until all the servers had their MariaDB running. In other words, exactly the opposite you want for a reliable system that requires minimum amounts of human supervision.
Perhaps PicoRed could have expanded into taking care of restarting the cluster, but since I couldn’t even get to a sequence of commands that, when executed on all servers at the right times, would reliably restart the MariaDB cluster, I kind of gave up. Lack of time and more interesting projects to develop, like Clouttery, meant that some stuff would inevitably get left behind, and my horrible mess of code called PicoRed ended up forgotten and eternally unfinished. Moving to proper solutions like Serf also required time that I didn’t have.
A few months ago I was notified that the provider of one of my VPS was closing, and all servers would be shut down by December 4th. I bought a new server, moved the stuff that wasn’t hosted anywhere else to it, but I really didn’t feel like reconfiguring the MariaDB cluster and PicoRed for the new server. PicoRed, in fact, stopped working in one of my servers (the one that wasn’t getting shut down) with some binary incompatibility error, a year or so ago. So I kind of gave up… reconfigured MariaDB so it stopped being a cluster, got rid of PicoRed, and said goodbye to one of the servers.
The new server is PHP and MariaDB/MySQL-free, and this probably won’t change. I would really like to move on from PHP and MariaDB to better languages and DBMSs. My main conclusion from the whole replication story is that MariaDB is not really prepared to scale horizontally, at least not without a lot of effort and “baby-sitting”.
I certainly have not given up on horizontal scaling, but I think that from on now, it’s best that I manage scaling at the application level instead of the database level, or alternatively, use a DBMS that was designed with horizontal scaling in mind, from the start. For the second option, it’s unfortunate that both CockroachDB and TiDB are still in a very premature state for production use.
I would rather not give up on relational databases; while it’s true that other types of database also cover some of the use cases of relational ones, I’m yet to know of any problem other than document storing that can’t be effectively solved with relational databases. (And for document storing, may I interest you in a relational database coupled with this strange thing called a filesystem?) Commercial solutions are obviously out of reach for me: it’s not like Segvault is a money-making machine; tny.im isn’t even profitable, despite all the ads!
I have grown to hate the mess of PHP and SQL that is tny.im so much, that shutting down the service (or at least getting it into a “read-only” mode) was once a topic for discussion at one of the TNY network meetings – all three of them. By the way, Segvault/TNY network is “hiring”, i.e. looking for new members with exciting project ideas, and if you had the patience to read this post this far, you may be a good candidate – contact me somehow.
Ads at tny.im earn me pocket change, that is used to offset the cost of the servers and domain names, and this shall be enough motivation to keep maintaining tny.im and supporting its users for some more years, updating MariaDB one version at a time.
December 13, 2016 / gbl08ma / 0 Comments
Today, 500 days have passed since the initial release of Windows 10. I quickly and unscientifically reviewed it right after it was released, in two blog posts: one mostly complaining, and another mostly praising it (as if I was seeking some sort of redemption). The former one was a huge success, if we take into account the readership numbers for this blog. That post accumulated over 30 thousand views in the few hours after its publication – and a month later, we were back to our usual readership stats of approximately zero views per hour.
But don’t get fooled by these yuge numbers; I’ve probably spent more hours of my life using Linux than Windows, which probably means my opinion on the latter actually isn’t worth shit – but don’t worry, as I’ve got this covered: studies show that this valuation falls in range with that of most people writing on popular tech news websites! The difference is that these usually spend their days looking at press releases and lesser-known tech news websites and blogs written by even-lesser-known people (totally not the case here) to repost find sources for their original pieces, while I usually spend my days going through computer engineering courses, building useless shit like Clouttery and answering tny.im support requests.
Since my 500-day-old posts have published, a lot of things have changed in the way I use Windows. Most importantly, my main Windows machine is no longer a Chinese Crapstore 7-inch tablet, but a proper Surface Pro 3 which I bought with a relatively good discount in October of 2015 right as the Pro 4 was being released. This means any problems I experience with Windows, I can no longer blame them on anyone other than me (the luser) and Microsoft (since the software is theirs, and the hardware is chosen, assembled and shipped by them). Oh, and drivers. On Windows, it’s always drivers.
After getting the Surface I started to use Windows much more, and in the last few months there have been many days during which I didn’t touch my more powerful Linux desktop [1]. I mostly use the desktop for coding, compiling big code trees and running heavier programs, but I do all of my note-taking (OneNote!), light web browsing (redditting and hackernewsing, for instance) and ssh-ing into Linux servers using the SP3, which means that when there isn’t more than this to my day, I don’t even turn on the desktop. I bought the Type Cover 4 a few months after buying the SP3, which certainly contributes to how much I use it.
Still, and after these major changes to the way I use Windows and how often I use it, I thought it would be interesting to go through all of the complaints in my extremely popular post from 31st July 2015, the day Windows 10 was released to the general public as it (supposedly) went out of beta, and check what was done about each of them. In a completely unscientific way, obviously, matching the standards this publication has accustomed you to.
As with my older posts, I will focus on the desktop edition (i.e. x86, i.e. the version that can run Win32 apps, i.e. the version that is actual “Windows” and not Windows Phone or Mobile or whatever they call it this month). It was announced in September 2014, skipping Windows 9 for reasons that, after many theories, may be best described as “yes” [2]. After multiple “preview” releases, it was made available “for real” on July 29, 2015 (this was version 1507, build 10.0.10240). Two days later, I published my “Windows 10 is unfinished” post, completely written and produced with my Windows 10-powered 7 inch tablet, sans-physical-keyboard. For this post, however, I’m not a masochist anymore – some parts have been written in my Linux desktop and others on the Surface with the type cover.
On November 12, 2015, the “November Update” was released (version 1511, build 10.0.10586), and I didn’t write a blog post because… well, I had more interesting things to do than I have right now (or rather, I was not procrastinating in writing). For the purposes of this post all you need to know is that this fixed a big number of stability and UI problems, but nothing too revolutionary. More recently, on August 2, 2016, the “Anniversary Update” was pushed to the production ring (version 1511, build 10.0.14393). This one was a bit more “revolutionary”, especially in terms of UI and feature changes, but as you’ll find out later… deep down, the important issues are yet to be solved.
There’s an upcoming “Creators Update”, but we are going to pretend that doesn’t exist and instead focus on the Anniversary Update, released about four months ago. Also, I can’t compare resource usage, as I’m no longer using the same hardware (even though I still own the smaller tablet and use it from time to time, it’s much, much less frequent now). Let’s begin.
The touch experience is still possibly worse than on Windows 8.1, but by now I’ve gotten used to it (also, with the Type Cover 4, I can use the excellent trackpad, so I no longer have the touchscreen as the only input device…). Annoyingly, the touch keyboard still doesn’t dock “properly”. This means that docking it doesn’t resize the whole desktop (forcing all windows to fit above the keyboard) like it did back in Windows 8.1. In many legacy apps which haven’t been adapted to “run away” from the touch keyboard, the cursor will still often be below the keyboard. Even on many parts of the Windows UI, this happens, and on parts which clearly have been adapted to avoid getting their inputs obscured by the keyboard, it’s still buggy as hell.
Funnily enough, some apps (like OneNote) can do this “desktop resizing” trick. So some months ago, I looked up the necessary APIs and in a few hours had a .NET proof-of-concept application that could resize the desktop, too. So it’s not a matter of missing APIs or compatibility problems – it’s certainly a deliberate design decision, and one I can’t understand. Perhaps it’s to encourage moving to UWP? I don’t even know anymore. If I still had to use the touch keyboard as my only keyboard for extended periods of time, you can be pretty sure that by now I’d have written my own “desktop resizing” helper that does its magic when the keyboard is docked.
The “void” between good old Win32 “classic” apps and the “modern” UWP (and that Windows 8 and 8.1 framework they don’t like to talk about anymore, but was the pre-UWP that powered Windows 8 apps) is even more reduced, with some bugs (for example, small details in behavior and looks between the “modern” and “classic” windows) getting fixed and more parts of the OS getting refreshed with a modern look (that, don’t let your eyes fool you, are often not actually built with UWP; it’s all just a matter of design language, the tech is still the same).
One can still find remnants of the multiple design languages used by the OS throughout its decades of history. Paying off this kind of technical debt, which I call “UX debt”, would surely go a long way towards giving Windows that polish it is often criticized for not having. You can still find icons from the Windows 98 and earlier era, from the XP era, from the Vista and 7 era, and even though it’s less noticeable (since it’s all “flat design”) you can also find some stuff that was designed back in the Zune and 8/8.1 days and was forgotten since then (now that I think of it, though, that happens mostly with Microsoft software other than what’s bundled with Windows). But pictures are so much better than text for this, so let’s mimic the iconic “two control panels” screenshot:
Not much left to comment here… oh wait, this is still a thing:
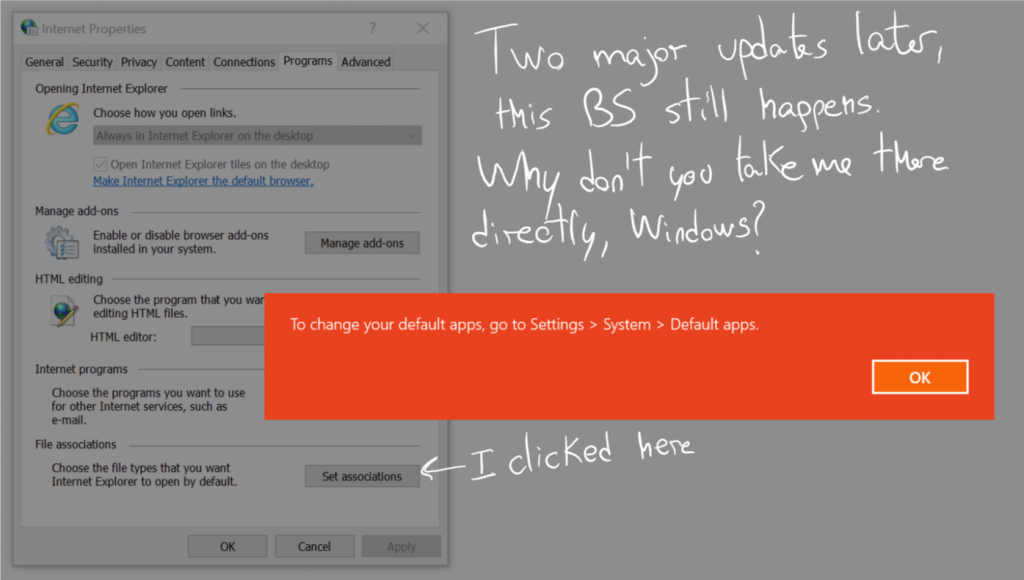
Sure, you may argue this is a fairly minor thing, doesn’t hurt anyone, doesn’t decrease system stability, and realistically doesn’t hurt anyone’s productivity. But, Microsoft, if you keep pushing your main product through deadlines without ever slowing down to fix “lower priority” stuff, the “UX debt” will keep increasing… damn, at some point you’ll lose even to “unpolished” Linux environments, if nothing else because some of these tend to throw everything away every three years and so have no “UX debt” to speak of (only bad UX, but no debt – it’s like being poor, but at least you don’t owe anyone money).
Now, the part which I personally find the funniest, and is an actual annoyance which certainly hurts productivity. To their credit, this had a major improvement with the Anniversary Update:
Left out of this image is the even wider assortment of context menu styles used by Microsoft’s own apps, like Office and Visual Studio. There are still different styles but the differences are now mostly between light and dark menu themes (which makes sense: dark elements produce dark menus). There’s also that giant menus situation, which supposedly should only occur when you use your fingers to open them. Problem: they sometimes show up when you use the mouse or a pen…
Don’t let me begin on the clusterfuck that are the network settings… I find myself constantly switching between the wireless networks popup in the taskbar, the “Network and Sharing Center” (old control panel page) and the Settings page to find the things I need. A particularly fun exercise I recommend to all readers, is getting to the dialog where you can retrieve the password for the Wi-Fi network to which you are currently connected. It’s especially fun if you have seen it before, and have a vague idea of where it is and how it looks like… and yet I always find it hard. Do you?
So, in terms of UI, it’s still far from perfect – but getting better. At this rate, I expect everything to be migrated to the “Windows 10 look and feel” in four or five years. Not a big problem, except for the fact that Microsoft, too, likes throwing out much of their work every three or four years (except they can’t throw much away, because of backwards compatibility and user training; things never get fully updated, and then you get “UX debt”). Let’s see how this works out.
There’s also the whole privacy concerns/telemetry topic, which I have skipped in this post. Not that it’s not important, but there’s so much to talk about that, it’d be better suited for whole another post on the privacy policies of most software-as-a-service (as some friends will be keen to point out, my own privacy policies – or the lack of them – included!). And the phenomenon of software that needlessly becomes software-as-a-service is vast enough to warrant another post, too… posts which I’ll most likely never write. But hey, just use your favorite search engine to find people with skeptical opinions on these topics. If you want a head-start and eventually some laughs, you can start with this or this. Guaranteed hours of endless fun and/or fumbling!
I also masterfully skipped over the “Windows updates are still stupid and require lengthy reboots 90% of the time! Why? Because it’s 2016 and Windows locks that way since the 90’s, that’s why!” subject, as well as the “Windows ate my settings and brought back Candy Crush!” one. Phew.
Now for the praising bit. Some of the stuff Microsoft is doing with Windows is particularly exciting. The Windows Subsystem for Linux, for instance: if it doesn’t appeal to you from an ethical/moral/religious perspective (and yes, I feel uncomfortable too), you have to agree it’s pretty interesting technically. And very recently they showed what appears to be a comeback of Windows RT, except this time it’s done right: x86 binaries running on ARM processors thanks to ISA translation. It’s not the fastest, and I suppose it only became usable (at least for “heavier” software like office suites and image editors) with the current generations of ARM processors (and perhaps more specifically, Snapdragon SoCs only). However, had they implemented this back in the Surface RT, perhaps not even as a marketing item but as a “nice to have” thing power users would find out about (just to find out it was dog slow), and the fate of that line could have been slightly better.
The Creators Update will bring more “nice to have” improvements and hopefully fix more of the still present UX issues, and add major features (but I’m not sure I care that much about these anymore, I would rather have more polished versions of what we have now). I bet: getting to the dialog where you “unhide” the wireless password will still be hard.
[1] This “desktop” is actually a Toshiba A660 laptop with a 1st-gen i7, 8 GB of RAM and a SSD upgrade, but the battery’s dead – it was never good to begin with. A machine that’s at least five years old and still rocking – unlike some would put it, it’s not ‘sad’ to be using it. Fortunately, I often can’t hear these people over the sounds travelling through the headphone jacks of my machines. I’m using Arch Linux, KDE and headphones and I’m quite happy with this setup, thank you.
[2] “Yes” is also the reason that’s more in line with the official reasoning, which, to quote Terry Myerson (an important guy at Microsoft), goes like this: “based on the product that’s coming, and just how different our approach will be overall, it wouldn’t be right to call it Windows 9”. Or to put it simply, “yes”.
The more base-2 oriented readers may be wondering, why post this 500 days after the release of Windows 10, missing the opportunity to post it 512 days after? The reason is that Windows 10 will turn 512 days old on the 24th of December, and you’ll probably have more interesting things to do that day than caring about this silly post – not that anyone cares on the other days of the year, anyway…