The limitations of hiding limitations: a striped case study
This GitHub repo, created just 5 hours before this post, shot to the top of Hacker News quite fast (see the thread). Its content is a readme containing a demonstration of the limitations of current artificial intelligence applications, specifically, the algorithms employed in Amazon product search, Google image search and Bing image search, by showing that searching for “shirt without stripes” does, in fact, bring up shirts, both with stripes and without.
At the time of writing, the brief but clever document can be seen as a mocking criticism of these systems, as it links to the pages where the three companies boast about their “broadest and deepest set” of “cutting-edge” “responsible” AI. I took these words from their pages, and of course you can’t tell which came from where, adding to the fun.
Some of the comment threads on the Hacker News submission caught my attention. For example, this comment thread points out the possible discrimination or bias apparently present in those systems, as doing a Google image search for “person” showed mostly white men to that user. This other thread discusses whether we should even apply natural language processing to a search query. In my opinion, both threads boil down to the same problem: how to manage user expectations about a computer system.
Tools like Google and Bing have been with us for so long, and have been improved to such a point, that even people who work in IT, and have a comparatively deep understanding of how they work, often forget how much of a hack they really are. We forget that, in many ways, Google is just an extremely advanced, web-scale successor to good old grep. And we end up wondering if there is ethnic or gender discrimination in our search results, which there probably is, but not because Google’s cyborgs are attracted to white men.
When web search was less perfect, when you needed to tinker with your search query multiple times to even get close to the results you wanted, it was very easy to see how imperfect those systems are, and we adjusted our expectations accordingly. Now, we still need to adjust our queries – perhaps even more often than before, as some Hacker News commenters have suggested – but the systems are much fuzzier, and what ends up working feels more random to us humans than it once did. Perhaps more interestingly, more users now believe that when we ask Google for something, it intrinsically understands the concepts of what we mentioned. While work is certainly being done to ensure that is the case, it is debatable whether that will even lead to better search results, and it’s also debatable whether those results should be “unbiased”.
Often, the best results are the biased ones. If you ask your AI “personal assistant” for the weather, you expect the answer to be biased… towards your current location. This is why Google et al. create a “bubble” for their users. It makes sense, it’s desirable even, that contextual information is taken into account as an additional, invisible argument to each search. Programmers are looking for something very specific when they search the web on how to kill children.
Of course, this only makes the “shirt without stripes” example more ridiculous: all the information on whether to include striped shirts in the results is right there, in the query! It does not need any sort of context or user profiling to answer this search query “correctly”, leading to the impression that indeed these systems should be better at processing our natural language… to the detriment of people who like to treat Google as if it was grep and who would use something more akin to “shirt -stripes”, which, by the way, does a very good job at not returning shirts with stripes, at least on a private browsing window opened by me!
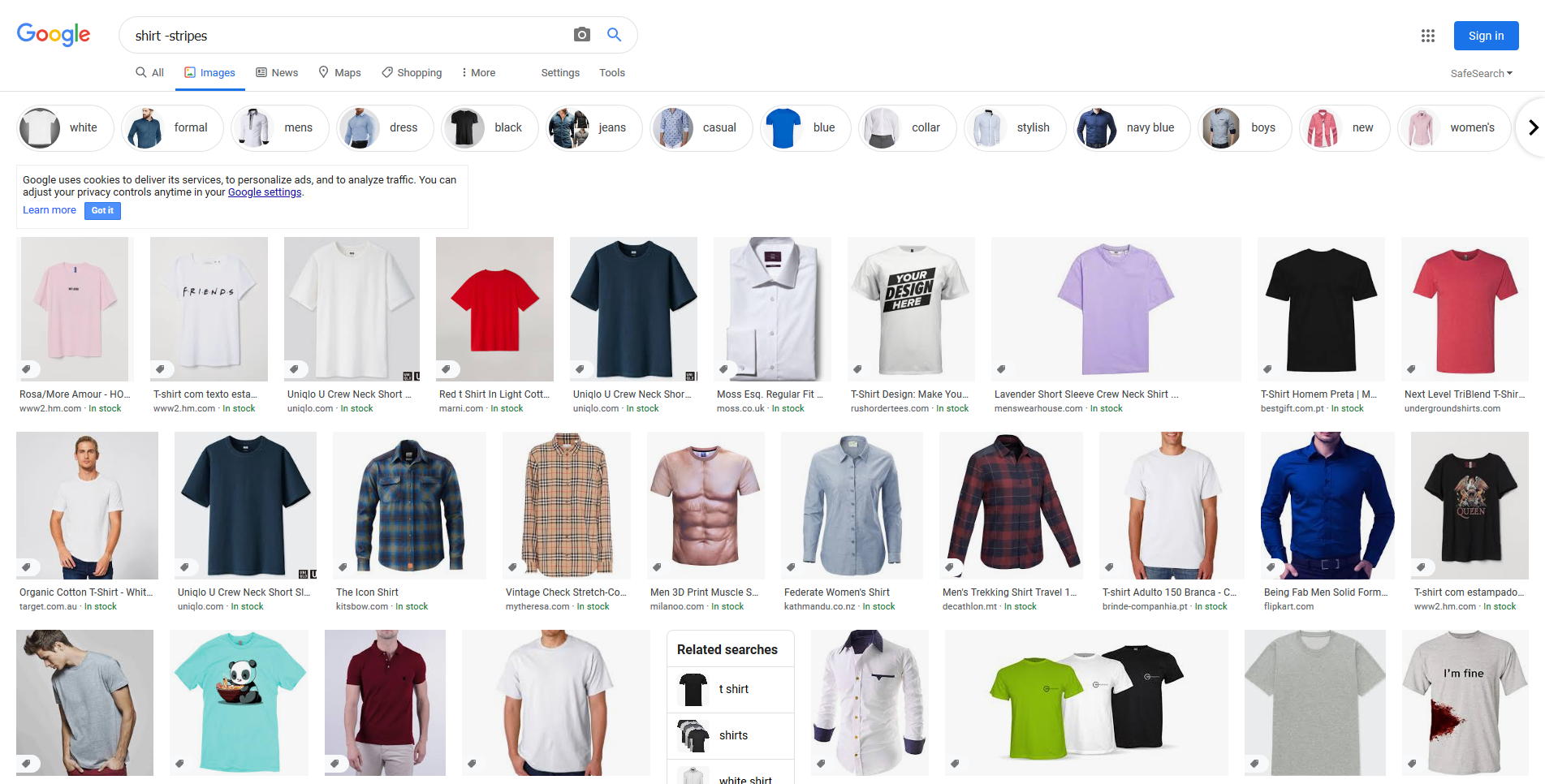
Google image search results for “shirt -stripes”. I only see models with skin colors on the lighter side… hmm 🤔
Yes, I used “shirt -stripes” because I “read the documentation” and I am aware of the limitations of this particular system. Of course, I’m sure Google is working towards overcoming these limitations. But in the meantime, what they offer is an imperfect system that seems to understand our language sometimes – just go ahead and Google something like “what is the president of France” – but fails unexpectedly at other times.
And this is the current state of lots of user interfaces, “artificial intelligence”, and computer systems in general. They work well enough to mask their limitations, we have grown accustomed to their quirks, and in their masking, we ultimately perceive them to be better than they actually are. Creating “personal assistants” which are ultimately just a glorified front-end to web search has certainly helped us perceive these tools as more advanced than they actually are, at least until you actually try to use them for anything moderately complex, of course.
Their fakery is just good enough to be a limitation, a vulnerability: we end up thinking that something more is going on, that these systems conspire in their quirks, that some hidden agenda is being pushed by having Trump or Gretta appear more often in search results. Most likely, there are way more pictures of white people on the internet than of any other skin color1, and I’m also sure that Greta has a better modern-day-equivalent-of-PageRank than me or even the Portuguese president, even taking into account the frequency with which he makes headlines. Blame that on our society, not the tools we use to navigate this mess we created.
1 Quite the bold statement to leave without a reference, I know. Of course, it boils down to a gut feeling, a bias, if you will. Whether computer systems somehow are more human by also being biased, is something that could be discussed… I guess I’ll try to explore this in a future blog post I’ll never get to actually write.