March 27, 2019 / gbl08ma / 6 Comments
Many are aware that some YouTubers are unhappy with how YouTube operates. But are you aware that Android app developers go through similar struggles with Google Play? Let me try and explain everything that’s wrong with Android in a single 20 minutes read.
Android was once considered the better choice of mobile platform for those looking for customizability, powerful features such as true multitasking, support for less common use cases, and higher developer freedom. It was the platform of choice in research and education, because not only are the development tools free and cross-platform, Android was also a very flexible operating system that did not get in the way of experimenting with innovative concepts or messing with the hardware we own. This is changing at an increasingly faster pace.
While major new Android versions used to bring features that got both users and developers excited, since a few versions ago, I dread the moment a new Android version is announced and I find myself looking for courage (heh) to look at the changelogs and developer guidelines for it. And new Android versions are not the only things that make my heart beat faster for the wrong reasons: changes to Google Play Store policies are always a fun moment, too.
Before we dive in any further, a bit of context: Android was not the first mobile OS I used; references to my experiences and experiments with Windows Mobile 6.x are probably scattered around this blog. I started using Android at a time when 4.2 was the latest version, I remember 4.4 being announced shortly after, and that was the version my first Android phone ran until the end of its useful life. Android was the first, and so far only, mobile operating system for which I got seriously invested in app development.
I started messing with Android app development shortly before 6.0 Marshmallow was released, so I am definitely not an old timer who can say he has seen Android evolve from the beginning, and certainly not from the perspective of a developer. Still, I feel like I have witnessed a decade of changes – in big part, because even during my “Windows Mobile experiments” era, I was paying attention to what was happening on the Android side, with phones I couldn’t yet afford to buy (my Windows Mobile “Pocket PCs” were hand-me-downs). I am fully aware of how bad Android was for both users and developers in the 4.x and earlier eras, in part because I still had the opportunity to use these versions, and in part because my apps had to support some of them.
API deprecation and loss of backwards compatibility
With every Android version, Google makes changes to the Android APIs. These APIs are how apps interact with the operating system, and simplifying things a bit, they pretty much define what apps can and can’t do. On top of this, some APIs require permissions, which you agree to when you install apps that use them, and some of these permissions can be allowed or denied by the user as he runs the app (of course, the app can refuse to run if the permissions are denied, but the idea is that it will degrade gracefully and provide at least some functionality without them). This is the case for the APIs that access your contact list or your location.
New Android versions include new APIs and, in the past, barely any changes were made to APIs introduced in previous versions. This meant that applications designed with an older version in mind would still work fine, and developers did not need to immediately redesign their apps with new versions in mind.
In the past two to three years, new Android versions have also began removing APIs and changing how the existing ones work. For example, applications wishing to stay active in the background now have to display a permanent notification, an idea which sounds good in theory, but the end result is having a handful of permanent notifications in your drawer, one for each application that may need to stay active. For example, I have two in my phone: one for the call recorder, and another for the equalizer system. One of my own apps also needs to have a similar notification in Android 8/Oreo and newer, in order to reliably perform Wi-Fi scans to locate the user in specific locations.
In the upcoming Android version 10/Q, Google intends to restrict even more what apps can do. They are removing the ability for apps to access the clipboard, killing an entire category of clipboard management apps (so that you can have a history of what you copied, so that you can sync the clipboard with your other phones and computers, etc.). Currently, all apps can access the clipboard without special permissions, but the correct way to solve this is to add a permission prompt, not to get rid of the API entirely. Applications can no longer turn the Wi-Fi on or off, which prevents automation apps from e.g. turning off the Wi-Fi when you’re driving. They are thinking of entirely preventing apps from accessing arbitrary files in “external storage” (SD cards and the area of internal memory on your phone where screenshots and camera pictures go, and where you put your MP3s, game ROMs for emulation, etc.).
Note that all of these things that they are removing for “security”, could simply be gated around a permission prompt you’d have to accept, as with the contact list, or location. Instead, they decided to remove the abilities entirely – even if users want these features, apps won’t be able to implement them. Existing apps will probably be review-bombed by users who don’t understand why things no longer work after updating to the shiny new Android version.
These changes to existing APIs mean more for users and developers. Applications that worked fine until now may stop working. Developers will need to update their apps to reflect this, implement less user-friendly workarounds, explanation messages, and so on. This takes time, effort, money etc. which would be better spent actually fixing other issues of the apps, or developing new features. For small teams or solo developers, especially those doing app development as a hobby or as a second job, catching up with Google’s latest “trends” can be insurmountable. For example, the change to disallow background services meant that I spent most of my free time during one summer redesigning the architecture of one of my apps, which in turn introduced new bugs, which had to be diagnosed, corrected, etc., and, in the end, said app still needs to show a notification to work properly in recent Android versions.
There are other ways Google can effectively deprecate APIs and thus limit what applications can do, without releasing new Android versions or having to update phones to them. Google can decide that apps that require certain permissions will no longer be allowed on the Play Store. Most notably, Google recently disallowed the SMS and Call Log permissions, which means that apps that look at the user’s call log or messaging history will no longer be allowed on the store.
Apps using these permissions can still be installed by downloading their APKs directly or by using alternative app stores, but they will no longer be allowed on the Play Store. This effectively means that for many apps, the version on the Play Store no longer contains important functionality. For example, call recorders are no longer able to associate numbers with the recordings, and automation apps can no longer use SMS messages as a trigger for actions. Because Google Play is where 99% of people get their apps, this effectively means functionality requiring these permissions is now disallowed, and won’t be available except to a extremely small minority of users who know how to work around these limitations.
The Google Play Store is the YouTube of app developers
Being on the Play Store is starting to feel much like producing content for YouTube, where policy changes can be sudden and announced without much time in advance. On YouTube, producers always have to be on the lookout for what might get a video demonetized, on top of dealing with content claims, both actions promoted by entirely automated, opaque systems. On the Play Store, we need to be constantly looking out for other things that might suddenly get our app pulled or our developer account banned – together with the accounts of everyone who Google decides has anything to do with us:
And this is just a tiny sample, not even the “best of”, of the horrifying stories that are posted to r/androiddev, every other day. For each of these, there are dozens in the respective “categories”. Sometimes the same stories, or similar ones, also make the rounds in Hacker News. It seems Google is treating Play Store bans and app removals with the same or worse flippancy that online games ban players suspected of cheating. Playing online games isn’t the career of most people who do it, but Android app development is, which leads to the obvious question, what do people do when they are banned?
After writing this, I realize my YouTube analogy is terrible. You see, on YouTube generally one receives strikes, instead of waking up one day to suddenly see their account banned. YouTubers also have the opportunity to profit from the drama caused by the policy changes by “reacting” to them, for example. And while YouTubers typically have the sympathy of their viewers, app developers have to deal with user outrage – because users have no idea, or don’t care, about why we’re being forced to massively degrade the performance and features of our apps. For example, the developer of ACR, a popular call recorder, had to deal with bad app reviews, abuse and profanity among thousands of emails from outraged users after removing the call log permission, and this was after an extensive campaign warning users of the upcoming changes (as a user of ACR, I uninstalled the Play Store version and installed the “unchained” version, which keeps the call log features, through XDA Labs).
As a freelance developer or as a small company, developing for Android is riskier than ever. I can start working on an app idea today and it’s possible that in six months, when it is ready for the initial release, changes to the store policy will have rendered my app unpublishable or have severely affected its functionality… in addition to the aforementioned point about APIs deprecating and changing semantics, requiring constant upkeep of the code to keep up with the latest versions.
If you opened the links above, by now you have probably realized another thing: user support with actual humans is non-existent, and if only their bots were as responsive as Google Assistant… And, if they are not bots, then they are humans which only spit out canned responses, which is just as bad. It is widely known that the best method for getting problems solved with regards to Google Play listings, is to catch the attention of a Google employee on social media.
It seems the level of support Google gives you is correlated to how many people will read your rants about your problems with their platforms. And it’s an exponential correlation, because being big isn’t enough to get a moderate level of support; you must be giant. This is a recurring problem with most Google services, especially if you are not using G Suite (apparently, app developers do not count as “paying customers” when it comes to support). Of all the things I’d like the EU to regulate (and especially, to not regulate, but that’s a story for a different time), the obligation for these mega-corporations to provide actual user support is definitely one of them.
Going back to the probably flawed YouTube analogy, there’s one more parallel to draw: many people believe that in recent years, YouTube has been making changes to both policies, business models and the “algorithm”, that heavily favor the big, already-established creators and make it hard for smaller ones to ever be successful. I believe we are seeing a similar trend on the Google Play Store – just keep in mind you must not analyze an app’s popularity or “level of establishment” by the number of downloads or active users, but by how much profit it generates in ad revenue and IAP cuts.
“Android is open source”
“Android is open source” is the joke of the year – for the fifth consecutive year. While it is true that the Android Open Source Project (AOSP) is still a thing, many of the components that make Android recognizable and usable, both from an end user and developer’s perspective, are increasingly closed source.
Apps made by Google are able to do things third-party apps have trouble replicating, no doubt due to the tight-knit interaction between them and the proprietary behemoth that is Google Play Services. This is especially noticeable in the “Google” app itself, Google Assistant, and the Google launcher.
If you install an AOSP build, many things will be missing and many apps – my own ones included – will have trouble running. Projects looking to provide “de-googlified” versions of Android have developed extensive open source replacements for many of the functions provided by Google Play Services. The fact that these replacements had to be community-developed, and the fact that they are very much necessary to run the majority of the popular applications, show that nowadays, Android can be considered open source as much as in the sense that it can be considered a Linux distro.
AOSP, on its own, is effectively controlled by Google. The existence of AOSP is important, if nothing else, to define common APIs that the different “OEM flavors” of Android must support – ensuring, with minor caveats, that we can develop for Android and not for “Samsung’s Android” or “Nokia’s Android”. But what APIs come and what APIs go is completely decided by Google, and the same is true for the overall system architecture, security model, etc. This means Google can bend AOSP to their will, stripe it of features and move things into proprietary components as much as they want.
Speaking of OEMs and inter-device compatibility, it’s obvious that this push towards implementing important functionality in Google Play Services and making the whole operating system operate around Google’s components has to do with keeping the “OEM flavors” under control. A positive effect for users and developers is that features and security patches become available even on devices that don’t receive OEM updates, or only receive updates for the major Android version they came with, and therefore would never receive the new features in the latest major release. A negative effect is that said changes can affect even old Android versions overnight and completely at Google’s discretion, much like restrictions on what APIs and permissions apps on the Play Store are allowed to use.
Google’s guiding light when it comes to Android openness seems to gravitate towards only opening the Android source as much as necessary for OEMs to make it run on their devices. We are not at that extreme point – mainly because the biggest OEMs have enough leverage to prevent that from happening. I feel that at this point, if Google were able to make Android entirely closed source, they would do it. I wonder what future Fuschia holds for us in this regard.
So secure you can’t use it
The justifications for many of the changes in later Android versions and Google Play policies usually fall into one of two types: “security” and “user experience”, with the latter including “battery life”. I’m not sure for whom Google is designing their “user experience” in recent years, but it certainly isn’t for “proficient users” like me. Let’s, however, talk about security first.
Security should be proportionally strong to what it is protecting. With each major Android version, we see a bigger focus on security; for example, it’s becoming harder and harder to root a phone, short of installing a custom ROM that includes superuser functionality from the start. One might argue this is desirable, but then you notice security and privacy have also been used as the excuse to disallow the use of certain permissions like the call log and messaging access, or to remove APIs including the external storage one.
This increase in security strength makes sense: security is now stronger because we are also storing more valuable information in our phones, from “old-fashioned” personal information about us and our acquaintances, to biometric information like fingerprint, facial and retinal scans. Of course, and this is probably the part Google et al. are most worried about, we’re also storing entire payment systems, the keys for DRM castles, and so on.
Before finishing my point about security, let’s talk a bit about user experience. User experience is another popular excuse for making changes while limiting or altogether removing certain features. If something has to be particularly complicated (or even “insecure”) in order to support the use cases of 1% of the users, it often gets simplified… while the “particularly complicated” or “insecure” system is stripped entirely, leaving the aforementioned 1% with a system that no longer supports their use cases. This doesn’t sound too bad, right? However, if you repeat the process enough times, as Google is bound to do in order to keep releasing new versions of their software (so that their employees can get their bonuses), tying the hands of 1% of the users at a time, you are probably going to be left with something that lets you watch ads only… and probably Google ads at that, I guess. You didn’t need to make phone calls, right? After all, the person on the other side might be pulling a social engineering scheme on you, or something…
Strong security and good user experience are hard to combine together. It seems that permission prompts do not provide sufficient security nor acceptable user experience, because apparently it’s easier to remove the permissions altogether than to let users have a choice.
User choice is what all of this boils down to, really. Android used to give me the choice of being slightly insecure in exchange for having more powerful and innovative features in the apps I install, than in the competing mobile platforms. It used to give me the choice of running 10 apps in the background and having my battery last half a day as a result, but now, if I want to do so, I must deal with 10 ongoing notifications. I used to be able to share files among apps as I do on my desktop, but apparently that is an affront to good security too. I used to be able to log the Wi-Fi networks in my vicinity every minute, but in Android 9 even that was limited to a handful of scans per hour, killing some legitimate use cases including my master’s thesis project in the process. Fortunately, in academia we can just pretend the latest Android version is 8.
Smart cards, including SIM cards, were invented to containerize the secure portion of systems. Authentication, attestation, all that was meant to be done there, such that the bigger system could be less secure and more flexible. Some time in the last two decades, multiple entities decided it was best (maybe it provided “better user experience”?) that important security operations be moved into the application processor, including entire contactless payment systems. Things like SafetyNet were created. My argument in this section goes way beyond rooting, but if my phone is rooted and one of the apps to which I granted root permission steals my banking details, … apparently the banking app shouldn’t have been allowed to run in the first place? Imagine if the online banking of my bank refused to open on my desktop because it knows I know the password for the administrator account.
Still on the topic of security, by limiting what apps distributed on the Play Store are allowed to do and ending support for legitimate use cases, Google ends up encouraging side-loading (direct APK download and installation). This is undesirable from a security point of view, and I don’t think I need to explain why.
Our phones are definitely more secure now, but so much “security” is crippling the use cases of people who do more than binge-watch YouTube and their social network feeds. We should also keep in mind that many people are growing up with smartphones and tablets alone, and “just use your desktop for those advanced tasks” is therefore not an answer. It’s time for my retarded proposal of the week, but what about not storing so much security-sensitive stuff in our phones, so that we don’t need so much security, and thus can actually get back the flexibility and “security pitfalls” we had before? Android, please let me shoot myself in the foot like you used to.
Lack of realistic alternatives
This evolution of Android towards appealing to the masses (or appealing to Google’s definition of what the general public should be allowed to do) would not worry me so much if, as a user, I had a viable mobile OS alternative. On the Apple side, we have iOS, whose appeal from the start was to provide a “it just works”, secure platform, with limited flexibility but equally limited margin for error. Such a platform is actually a godsend for many people, who certainly make up the majority of users, I don’t doubt. Such a platform doesn’t work for me, because as I said, I need to be able to shoot myself in the foot if I want to: let me have 2 hours of battery life if I want, let my own apps spy on my location if I want.
This was fine for many years, because we had Android, which let us do this kind of stuff. It just so happens that because of AOSP, and because there were no other open source or licensable platforms with traction, Android ended up being the de-facto standard for every smartphone that isn’t an Apple one. On the low-end, Android is effectively the only option. Of course, this led to Android having the larger market share. Since “everyone” uses it now, there’s pressure to copy the iOS model of “it just works” and “safe for people with self-harm tendencies” – you can’t hurt yourself even if you wanted.
Efforts to introduce an Android competitor have been laughable, at best. Windows Phone/Windows Mobile failed in part because of a weak and possibly too late entry, combined with a dubious “vision” and bad management decisions on Microsoft’s part. In the end, what Microsoft had was actually good – if there weren’t the case, there wouldn’t be still plenty of die-hard WP/WM fans – but getting there so late (and with so many mixed signals about the future of the platform) means developers were never sufficiently captivated, and without the top 100 apps in there, users won’t find the platform any good, no matter how excellent it is from a technical standpoint. Obviously, it does not help that a significant number of those “top 100 apps” are Google properties; in fact, the only reason Google has their apps on iOS is because, well, iOS was there already when they arrived on the scene.
If even a big player with stupid deep pockets like Microsoft can’t introduce a third mobile platform, the result of smaller-scale attempts like Firefox OS is quite predictable. These smaller attempts have an additional problem, which is finding hardware to run on. It doesn’t help that you can’t change the OS on a phone the same way you can on a PC. In fact, in the long gone year of 2015, I was already ranting about the lack of standardization in smartphone hardware. It’s actually fun to go back at that post, made when Android 4.4 was the latest version, and see how my perception of Android has changed.
I should also note that if a successful Android alternative appears, it will definitely run Android apps, probably through a compatibility layer. In a way, Android set the standard for apps much in the same way that 15 years ago, IE6 was setting web standards in the worst way possible. Did someone say antitrust?
Final thoughts
Android, and therefore Google, set the standard – and the implementation – for what we can and can’t do with a smartphone, except when Apple introduces a major innovation that OEMs and Google are compelled to quickly implement in Android. These days, it seems Apple is stalling a bit in innovation in the smartphone front, so Google is taking the opportunity to “innovate” by making Android more similar to iOS, turning it into a cushioned, limited, kid-safe operating system that ties the hands of developers and proficient users.
Simultaneously, Google is solving the problem of excessive shovelware and even a bit of malware on the Play Store, by adding more automation, being even less open about their actions, and being as deaf as ever. Because it’s hard to understand whether apps are using certain permissions legitimately or not – and because no user shall be trusted to decide that by themselves – useful applications, from call recording tools, to automation, to literally any app that might want to open arbitrary files in the user storage, are being “made impossible” by the deprecation and removal of said permissions and APIs.
We desperately need an Android alternative, but the question of who will develop, use and target said alternative remains unanswered. What I know, is that I no longer feel happy as an Android developer, I no longer feel happy as an Android user, and I’m not likely at all to recommend Android to my friends and family.
Edited at 2:56 March 28th UTC to add clarification about Android clipboard access.
See the discussion for this article on Hacker News, r/AndroidDev, r/Android
August 23, 2015 / gbl08ma / 1 Comment
Go to the bottom, “Summing it up”, for the TL;DR.
The day I turn this website into a portfolio/CV-like thing will come sooner or later, and arguably that’s a better use for the domain gbl08ma.com than this blog with posts nobody cares about – except when I rant about new operating systems from Microsoft. But if you really care about such posts, do not worry: the blog will still exist, it just won’t be as prominent.
Meanwhile, and off-topic intro aside, the content usually seen on such presentation websites everyone-and-their-cat seems to have these days, will have to wait. In anticipation for that kind of stuff, let’s go in a kind of depressing journey through my eight years programming experience.
The start
The beginning was what many people would consider a horror movie: programming in Visual Basic for Applications in Excel spreadsheets, or VBA for short. This is (or was, at the time; I have no idea how it is now) more or less a stripped down version of VB 6 that runs inside Microsoft Office and does not produce stand-alone executables. Everything lives inside Office documents.
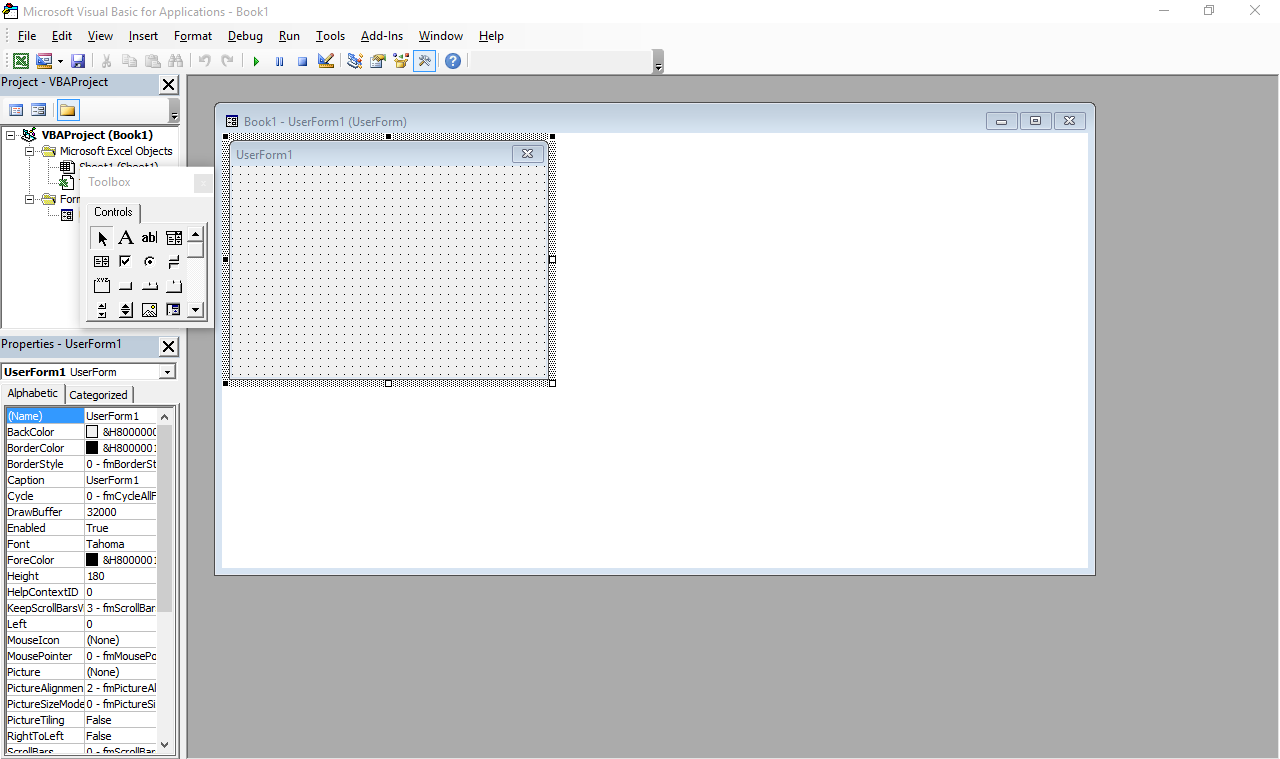
It still exists – just press Alt+F11 in any Office window. Also, the designer has Windows 7 Basic window styles… on Windows 10, which supposedly ditched all that?
I was introduced to it by my father, who knows his way around Excel pretty well (much better than I will probably ever will, especially as I have little interest). My temporal memory is quite fuzzy and I don’t have file timestamps with me for checking, so I was either 9, 10 or 11 years old at the time, but I’m more inclined to think 9-10. I actually went quite far with it, developing a Excel-backed POS system with support for costumer- and operator-facing character LCD screens and, if I remember correctly, support for discounts and loyalty cards (or at least the beginnings of it).
Some of my favorite things I did with VBA, consisted in making it do things it was not really designed for, such as messing with random ActiveX controls and making it draw strange-looking windows (forms) and controls through convoluted Win32 API calls I’d have copied from some website. I did not have administrator rights to my computer at the time, so I couldn’t just install something better. And I doubt my Pentium III-powered computer, already ancient at the time (but which still works today), would keep up with a better IDE.
I shall try to read these backup CDs and DVDs one day, for a big trip down the memory lane.
Programming newb v2
When I was 11 or 12 I was given a new computer. Dual core Intel woo! This and 2GB RAM meant I could finally run virtual machines and so I was put on probation: I administered the virtual computers, and soon the real hardware followed (the fact that people were tired of answering Vista’s UAC prompts also helped, I think). My first encounter with Linux (and a bunch other more obscure OS I tried for fun) was around this time. (But it would take some years for me to stop using Windows primarily.)
Around this time, Microsoft released the Express (free) editions of VS 2008. I finally “upgraded” to VB.NET, woo! So many new things to learn! Much of my VBA code needed changes. VB.Net really is a better VB, and thank Microsoft for that, otherwise the VB trauma would be much worse and I would not be the programmer I am today. I learned much about the .NET framework and Visual Studio with VB.NET, knowledge that would be useful years later, as my more skilled self did more serious stuff in C#.
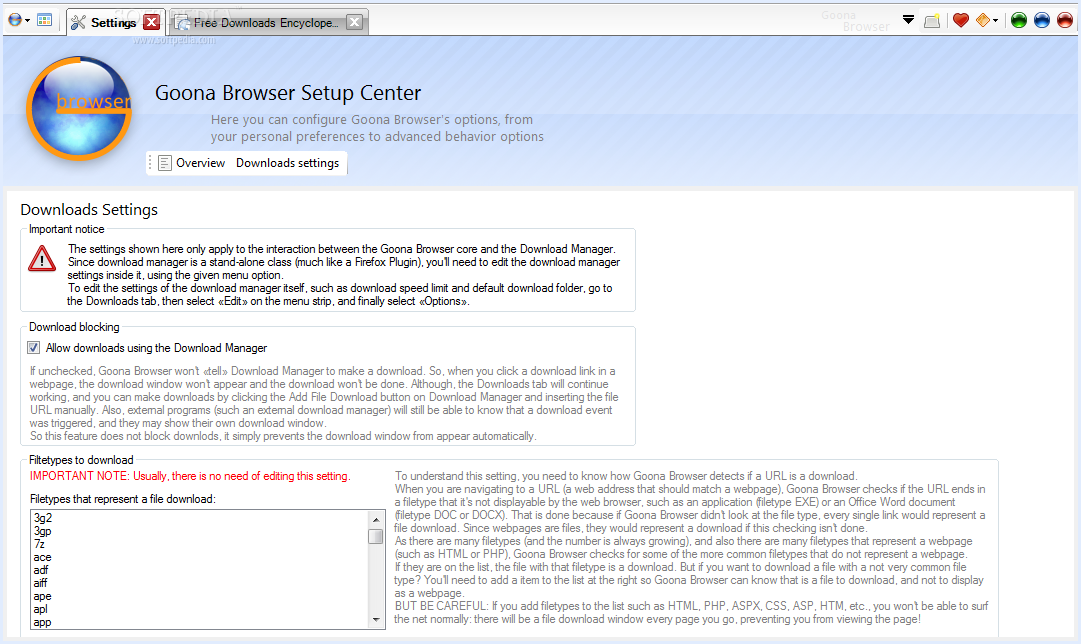
In VB.NET, I wrote many lines of mostly shoddy code. Much of that never saw the light of day, but there are some exceptions: multiple versions of Goona Browser made their way to the public. This was a dual-engine web browser with advanced UI, and futuristic concepts some major players copied, years later.
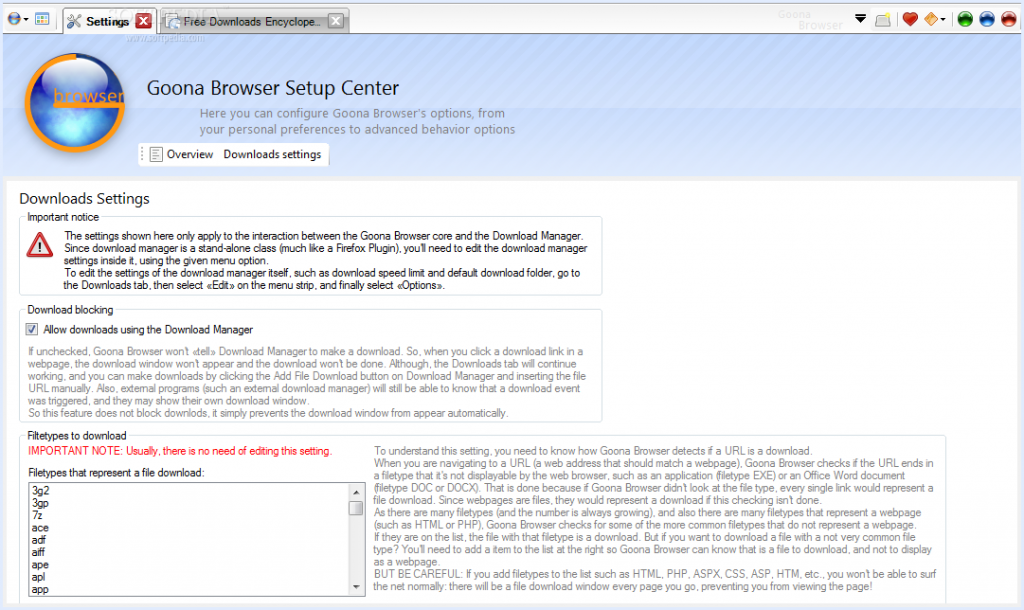
How things looked like, in good days (i.e. when it didn’t crash). Note the giant walls of broken English. I felt like “explain ALL the things”! And in case you noticed the watermark: yes, it was actually published to Softpedia.
If you search for it now, you can still find it, along with its website which I made mostly from scratch. All of this accompanied by my hilariously broken English, making the trip to the past worth its weight in laughs. Obviously I do not recommend installing the extremely buggy software, which, I found out recently, crashes on every launch but the first one.
Towards the later part of my VB.NET era, I also played a bit with C#. I had convinced myself I wanted to write an operating system, and at the time there was a project called COSMOS that allowed for writing (pretty limited) OS with C#… of course my “operating” systems were not much beyond a fancy command line prompt and help command. All of that is, too, stored in optical media, somewhere… and perhaps in the disk of said dual-core computer. I also studied and modified open source programs made in C# (such as the file downloader described in the Goona Browser screenshot) for my own amusement.
All this happened while I developed some static websites using Visual Web Developer Express as editor. You definitely don’t want to see those (mostly never published) websites, but they were detrimental to learning a fair bit of HTML and CSS. Before Web Developer I had also experimented with Dreamweaver 8 (yes, it was already old back then) and tried my hand at animation with Flash 8 (actually I had much more fun using it to disassemble existing SWFs).
Penguin programmer
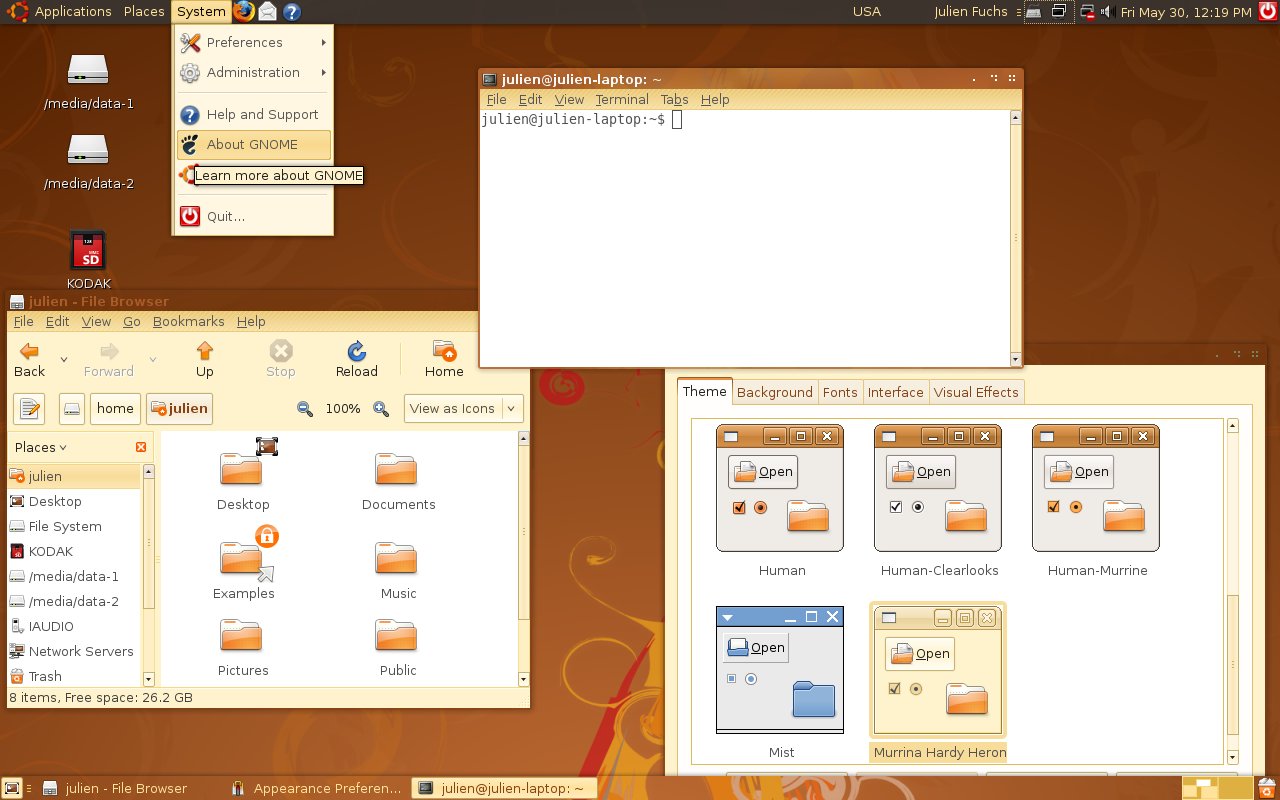
At this point I was 13 or so, had my first contact with Linux more than done, through VMs and Live CDs, aaand it happened: Ubuntu became my main OS. Microsoft “jail” no more (if only I knew what a real jailed platform was at the time…). No more clunky .NET! I was fed up with the high RAM usage of Goona Browser, and bugs I was having a hard time debugging, due to the general code clumsiness.
How Ubuntu looked like when I first tried it. Good times. Canonical, what did you do?
For a couple of years, in terms of desktop development, I only made some Python scripts for my own amusement and played a very small bit with MonoDevelop every time I missed .NET. I also made a couple Lua scripts for Rockbox. I learned much about Linux usage and system maintenance as I used it more and more on my own computers and on my first Virtual Private Servers, which I got after much drama in the free web hosting communities. Ugh, how I hate CPanel.
It was around this time that g.ro.lt and n.irc.su appeared. g.ro.lt was a URL shortener that would later evolve into 4.l.to and later tny.im. n.irc.su was a social network built on Elgg, which obviously failed. I also made some smaller websites, like one that would take you to random image hosting websites, URL shorteners and pastebins, so you would not use the same service every time you urgently needed one. These represented my first experiences with PHP programming.
I have no pictures to show. The websites are long gone, not on the Internet Archive, and if I took screenshots, I have no idea where I put them. Ditto for the logos. I believe I still have the source code for the random-web-service website somewhere, at least the front page layout.
All this working on top of free stuff: free (and crappy) subdomains, free (and crappy) web hosting, free (and less crappy) virtual servers. It would take me some time until I finally convinced myself I needed to spend some money for better reliability, a gist of support and less community drama. And even then I would spend Bitcoin, which I earned back when it was really cheap, making the rounds of silly faucets and pulling money out of CPAlead-like offers through the use of multiple proxies (oh, the joy of having multiple VPS…). To this day I still don’t have a PayPal account.
This time, and when I actively developed tny.im (as opposed to just helping maintain it), was the peak of my gbl08ma-as-web-developer phase. As I entered and went through high school, I would get more and more away from HTML and friends (but not server maintenance), to embrace something completely different…
Low level, little resources: embedded systems
For high school math everyone had to use a graphing calculator. My math teacher recommended (out of any interest) Casio calculators because of their ease of use (and even excitedly mentioned, Casio leaflet in hand, the existence of a new and awesome color screen model that “did everything and some more”). And some days later I had said model in my hands, a Casio fx-CG 20, or Prizm, which had been released about a year before. The price difference from the earlier dot-matrix screen Casio calcs was too small to let the color screen go.
I was turning 15, or had just turned 15. I remember setting up the calculator and thinking, not much after, “I want to code for this thing”. Casio’s built-in Basic dialect is way too limited (and after having coded in “real” languages, Basic was silly). This was in September 2011; in March next year I would be releasing my first Prizm add-in, CGlock, a calculator PIN-locking software.


Minimalist look, yay! So much you don’t even notice it’s a color screen.
This was my first experience with C; I remember struggling with pointers, and getting lots of compilation warnings and errors, and run-time errors. Then at some point everything just “clicked in” and C soon became my main language. Alas, for developing native software for the Prizm, this is the only option (besides using C++ without most of its features, not even the “new” keyword).
The Prizm is a horrible platform, especially for newbie C programmers. You can’t use a debugger, nor look at memory contents, the OS malloc/free implementation has bugs (and the heap is incredibly small, compared to the stack) and there’s always that small chance some program damages your calculator, or at least corrupts your estimated files and notes. To this day, using valgrind and gdb on the desktop feels to me as science fiction made true. The use of alloca (stack allocation) ends up being preferred in relation to dynamic allocation, leading to awkward design decisions.

Example of all the information you can get about an error in a Prizm add-in. It’s up to you to go through your binary (and in some cases, disassemble the OS) to find out what these mean. Oh, the bug only manifests itself when compiling with optimizations and without symbols? Good luck…
There is a proprietary emulator, but it wasn’t designed for software development and can’t emulate certain things. At least it’s better than risking damage to expensive hardware. The SuperH-4 CPU runs at 58 MHz and add-ins have access to about 600 KiB of memory, which is definitely better than with classic z80-powered Texas Instruments calculators, but one still can’t afford memory- or CPU-intensive stuff. But what you gain in performance and screen resolution, you lose in control over the hardware and the OS, which still have lots of unknowns.
Programming for the Prizm taught me how it’s like to work without the help of the C standard libraries (or better, with the help of incomplete and buggy standard libraries), what a stack overflow looks like (when there’s no stack protection), how flash memories work, what DMA is, what MMUs do and how systems can be bricked when their only bootloader is not read-only. It taught me how compilers work from an end-user perspective, what kind of problems and advantages optimizations introduce, and what it’s like to develop parts of the C standard library.
It also taught me Casio support in Portugal (Ename) is pretty incompetent at fixing calculators, turning my CG 20 into a CG 10 and leaving two big capacitors out of a replacement main board. In this hardware topic, I learned quite a bit about digital logic from Prizm hardware discussions at Cemetech. And I had some contact with SH4 assembly and a glimpse into how to use IDA Pro. Thank you Casio for developing a system that works so well and yet is so broken in so many under-the-hood ways, and thank you Cemetech for briefly holding the Prizm higher than TI calcs.
I developed other add-ins, some from scratch and others as ports of existing PC software (such as Eigenmath). I still develop for the Prizm from time to time, but I have less and less motivation as the homebrew community has stagnated and I use my Prizm much less, as I went to university. Experience in obscure calculator platforms does not make for a nice CV.
Yes, in three years or so I went from the likes of Visual Studio to a platform where the only way to debug is to write text to the screen. I still like embedded and real-time programming a lot and have moved to programming more generic and well-known things such as the ESP8266.
Getting in the elevator
During the later part of high school (which I started in the fall of 2011 and ended in the summer of 2014), I did more serious Python stuff, namely Mersit, later deprecated in favor of Picored, which is not written in Python but in Go. Yes, I began trying higher-level stuff again (higher level, getting in the elevator… sorry, I’m bad at jokes).
My first contact with Go was when I was 17, because I wanted to develop something that ran without external dependencies (i.e., unlike Java or .NET) and compiled to native code. I wanted to avoid C/C++, but I wasn’t looking for “a better C” either, so Rust was not it. Seeing so much stuff about Go at Hacker News, one day I decided to try my hand at it and I like it quite a lot – I’m still unsure if I like it because of the language itself or because of the great libraries one can use with it, but I think both play an important role.


This summer I decided to give C# another chance and I’m quite impressed – turns out I like it much more than I thought. It may have something to do with trying it after learning proper languages vs. trying it when one only knows VB. I guess my VB.NET scars are healed. I also tried a bit of Java, in my first contact with it ever, and it seems my .NET hate converted into Android API hate.
Programming with grades
University gave the opportunity (or better, the obligation) of having other people criticize my code. The general public could already see the open-source C code of my Casio Prizm add-ins, and even the ugly code of Goona Browser, but this time my code was getting graded. It went better than I initially thought – I guess the years of experience programming in different languages helped, especially as many of the people I’m being compared with have only started programming this year.
In the first semester we took an introductory programming course, which used Python, and while it was quite easy for me, I took the opportunity to learn Python to a greater depth than “language in which to write quick and dirty glue code”. You see, until then I had not used classes in my Python code, for example. (This only goes to show Python is a versatile language, even if slow.)
We also took an introductory computer architecture course where we learned how basic CPUs work (it was good for gluing all the separate knowledge I already had about it) and programmed in assembly for a course-specifc CISC-like architecture. My previous experience with reading SH4 assembly proved quite useful (and it seems that nowadays the line between RISC and CISC is more blurred than ever).
In the second semester, I had the opportunity to exercise my C knowledge, this time not limited to the Prizm platform. More interestingly, logic programming, a paradigm I had no intention of ever programming in, was presented to us. So Prolog it was. It went much better than I anticipated, but as most other people who (are forced to) learn it, I have no real use for it. So the knowledge is there, waiting for The Right Problems(tm). I am afraid I’ll forget much of it before it becomes useful, but if there’s something picking C# up again taught me, is that I can pick up pretty fast skills learned and abandoned long ago.
The second year is about to begin and there’s some object-oriented programming coming, I hope I do well.
Summing it up
I have written non-trivial amounts of code in at least 8 languages: Visual Basic, PHP, C#, Python, Lua, C, Go, Java and Prolog. I have contacted with two assembly dialects and designed web pages with HTML, CSS and Javascript, and of course automated some tasks with bash or plain shell scripting. As can be seen, I’m yet to do any kind of functional programming.
I do not like “years of experience” as a way to measure language proficiency, especially when such languages are learned for use in short-lived side projects, so here’s a list with an approximate number of lines of code I have written in each language.
- C: anywhere between 40K lines and 50K lines. Call it three years experience if you will. Most of these were for Prizm add-ins, and have since been rewritten or heavily optimized. This is changing as I develop less and less for the Prizm.
- PHP: over 15K lines, two years if you want to think that way. The biggest chunk of these were for developing the additions to YOURLS used in tny.im, but every other small project takes its own 200-500 lines of code. Unfortunately, most of this is “bad” code, far from idiomatic. The usual PHP mess, you know.
- Python: at least 5K lines over what amounts to about six months. Of these, most of the “clean” lines (25-35%) were for university projects.
- Go: around 7K lines, six months. Not exactly idiomatic code, but it’s clean and works well.
- VBA: uh, perhaps 3 or 4K lines, all bad code 🙂
- VB.NET: 10K lines or so, most of it shoddy code with lots of Try…Catch to “fix” the problems. Call it two years experience.
- C#: 10K lines of mostly clean and documented code. One month or so 🙂
- Lua: mostly small glue scripts for my own amusement, plus some more lines for use in games such as Minetest, I estimate 3-4 K lines of varying quality.
- Java: I just started, and mostly ported C# code… uh, one week and 1.5K lines?
- HTML, CSS and JS: my experience with JS doesn’t go much beyond what’s needed to modify DOM elements and make simple AJAX requests. I’ve made the frontend for over 5 websites, using the Bootstrap and INK frameworks.
- Prolog: a single university assignment, ~250 lines or one month. A++ impression, would repeat – I just don’t see what for.
In addition to all this, I have some experience launching the programs and services I make – designing logos/branding, versioning, keeping changelogs, update instructions, publishing, advertising, user support. Note that I didn’t say I’m good at any of these things, only that I have experience doing them, for better or worse…
Things I’d like to have more experience with:
- Continuous integration / testing in general;
- Debugging code outside of .NET/Visual Studio and printing debug lines in C;
- Using Git and other VCS in big repos/repos with more people (I want to see those merge conflicts and commits to the wrong branch coming);
- Server-side web development on something other than PHP and Go. And learning to use MVC frameworks, independently of the language;
- C++ (and Java, out of necessity. Damned Android);
- Game development. Actually, this is how many people start, but I’m so cool that I started by developing POS software 🙂
February 2, 2015 / gbl08ma / 0 Comments
Just two days ago, I mentioned in this blog the Windows port Microsoft made for the ARM architecture:
Microsoft, for things like the (abandoned) Windows RT and Windows Phone, besides porting some of the upper layers of the Windows stack and developing new ones, also had to do additional work to get the NT kernel to run on such hardware. It’s worth mentioning that despite that effort, Windows Phone 8+ has hardware requirements higher than those of Android (comparing versions released in the same time span, please correct me if I’m wrong).
Today, as I open the web browser I’m greeted by multiple related news: a quad-core ARMv7 / 1 GB RAM version of the popular Raspberry Pi board, named “Raspberry Pi 2”, was released, will run Ubuntu Snappy Core, and, mind you, Windows 10.
Now that Windows RT is pretty much dead in the water, it looks like Microsoft found at least one use for their port besides Windows Phone: a strategically introduced “Windows 10 for makers”, which is free – something that would come out as impossible some years ago, in the license-angry Microsoft phase. (Yes, just like they also offered the Windows 8.1 license to OEMs of tablets with screen >= 7 inches, and apparently will offer Windows 10 to Windows 7 and 8.1 users for one year after its release). Of course, there’s no news of this Windows version being the slightest open-source – that is something that in the beginning of 2015, is still thought as “impossible” – but Microsoft is making promising steps, after having open-sourced the .NET framework.
Now, let me explain: while this is a nice move from Microsoft, is not something that leaves me particularly happy (in fact, it leaves me somewhat worried, and it’s not because “OMG OMG Linux is going to lose market share”). For starters, there’s the fact that there have been way more powerful ARMv7 devices around for a long time, for a similar or equal price ($35 USD) – take a look, for example, at the ODROID-C1, so why didn’t Microsoft decide to offer Windows for those too?
The answer, in my opinion, is very simple: Microsoft wants to “look cool”, and benefit from the free advertising and consequent increase of popularity a partnership with the Raspberry Pi Foundation has. Releasing Windows 10 for ARM in a more flexible setup (one that would support different boards besides the new Raspberry Pi) would be even more interesting to the community and probably more flexible for wearable, IoT, etc. projects, but that’s not the path they chose.
Supporting only the Raspberry Pi is also the easiest option, partly due to the lack of standards in the ARM world, which I complained about in the aforementioned blog post. Supporting other boards would lead to a lot of work supporting the different SoC, different peripherals, different boot methods and imaging formats (nothing that Microsoft couldn’t abstract away with a generic second-stage bootloader for WIM files), etc. In other words, it would leave them with as much work as the Linux community has in order to support different embedded systems and CPU architectures (heh).
Something that’s still unclear to me is the licensing part. This Windows version, while free, certainly comes with caveats. I’m sure Microsoft won’t allow using it on consumer products based on the Raspberry Pi (for example, using the upcoming version 2 of the Compute Module), as otherwise it would constitute a free alternative to licensing Windows Embedded. I also expect this version to come severely crippled as not to be able to act as a server; otherwise, expect some cheap Windows servers coming up soon. Even if it’s not crippled, the EULA rules it all, which means that even if a port of this Windows to other ARM boards and devices was possible, or if someone starts selling RPi-based Windows ARM servers, it most likely would not have Microsoft’s blessing.
I’m also a bit worried that the Raspberry Pi Foundation might start to push for Windows instead of Linux, especially since I bet the Windows port will be much more popular than the Linux distros. Doing so would kill half of the purpose of the whole Raspberry Pi thing, in my opinion. Most kids, given the opportunity to use the same user interface and some of the programs they are already used to, will never try to learn new things, much less tinker with them. Having them use a different GUI, or perhaps no GUI at all, by booting directly to a shell (try that, Windows! The closer you can get is the command line on a Windows Recovery Environment! heh) allows for an experience that is, from the start, much different from what they would get with a typical off-the-shelf computer.
By making people move out of their “comfort zone”, the Raspberry Pi Linux distros encouraged people to learn their way around a different system. I’m afraid people who buy a Raspberry Pi and promptly install Windows on it will keep without knowing what a command line is, and will keep doing the same things they did on their full computers. Text-based UIs are definitely not the best option for many/most things, but there are many things they’re better at than GUIs, and more importantly, some people find them out to discover they like them much more than GUIs. But if these people are never given the opportunity, they will never find it out.
Now I must admit, it would be super awesome if Microsoft came up with something like FX!32 but for running x86 binaries on ARM. That would probably require an even more restrictive EULA and/or more crippling for this Raspberry Pi version, as then people would be able to run, for example, all sorts of existing server software that currently requires a paid Windows Server license.
To conclude, I don’t think Microsoft is actually interested in making Windows available for more devices or actually making it a viable choice for low-cost embedded hobby projects and consumer products. They are just trying to gain popularity among not only the general public, but also among the developer and hobbyist community. Unfortunately, I’m not sure if this movement of “embracing OSS and open-sourcing ALL THE THINGS!” is going to last when/if Microsoft reaches their market share goals.
We can look into how the competition did: Android, initially pretty much completely open source, was made more closed as its market share increased. Google keeps on moving more and more things to closed-source blobs under their control, which has upsides (it’s easier to update many parts of the OS) and many downsides (lower user control, etc.). I wonder and worry if Microsoft will do something similar as their popularity endeavors are successful, turning their back on users, developers and all this “freedom hype” once again.
September 29, 2014 / gbl08ma / 1 Comment
My previous post on this blog was published by the end of the long-gone month of June. Many things have changed since then, for example, I entered university and was pressed into creating a Facebook account (more or less separate from the rest of my online presence, so don’t look for me, I won’t add you). On that post, I rambled about the recovery from a big server outage that costed 42 hours of tny.im downtime, and over one week of server downtime. I learned my lessons (I doubt BlueVM learned theirs, but that’s a whole other story), and I went forward with what I said I would do: “setting up a new advanced and redundant system” for ensuring tny.im is always up.
That system has been up and running for over two months now, with varying amounts of servers making the redundancy and load balancing, and a plethora of occasional hiccups. Right now it’s composed of three virtual servers (all from different providers…), but there were times when it was composed of five servers. These three servers are paid, and while they aren’t exactly expensive (but not the cheapest, either), you can imagine the bill, so let’s not talk about tny.im profitability now, OK? (I have kind of given up).
In the spirit of the great statisticians of our time, here’s a graph without title, labels or axis.
However, having three servers serving the same website, with all three of them being almost a clone of each other (which means, all have the same files and database contents, synced), in a DNS round-robin setup doesn’t directly lead to greater uptime. In fact, I have found out it can lead to more outages, since now the total downtime is approximately the sum of the downtime of each server. Of course, most of these outages are partial (as in, only users unlucky enough to have their DNS request resolved to the IP of a server that is down, will actually perceive the site as down), except for when the MariaDB replication freaks out and basically grinds all database operations, on all servers, to a halt, requiring a complicated manual restart of all MariaDB instances, in a specific order (yes, I have spent many hours searching for an alternative database system, and couldn’t find any that met my requirements).
In order to actually achieve greater uptime, one must have a system that automatically manages the DNS records so that the domain(s) of the website in question never have any records pointing to servers that are down. In other words, the “sheep” must be “hidden from sight” as soon as they go “bad”, and should be put back “in stage” once they become “good”. Being DNS something that was definitely not made for real-time record edits, with many systems caching DNS request results well beyond the specified TTL, this system obviously doesn’t ensure that the “bad sheep” are not invisible to everyone watching the show. But if it manages to do it for even a small percentage of the public, it’s already better than not hiding from anyone (and especially, if it successfully hides the problem from the uptime monitor, that’s even better 🙂 ). This explains why the DNS records for tny.im are set with TTLs of five minutes.
The development of such a DNS record management system was also more or less contemplated in my previous post, when I say:
I’ll take this downtime and new server acquisition as the motivation for setting up a new advanced and redundant system, so that if one server goes down, tny.im (and possibly this blog too) will continue to operate as normal.
And in the end, in a later edit:
On related news, Mirasm – the Tiny Server Redundancy Manager – is mostly finished, only needs some more testing to be put on production servers, managing the new tny.im redundancy system.
“Mostly finished”, as we all know, really means “It’s 99% ready, I only need to figure out the remaining 1% that consists on… everything that is tricky and I’m not sure how it’s done”. This is specially true in this case, as I had high requirements for my manager: it couldn’t use any resources other than the servers I had already (it would’ve been easy to have a separate server just for monitoring and editing DNS as needed, but I didn’t want to pay for yet another server on yet another provider), and it couldn’t fail more than tny.im itself. In fact, the time when the manager has to do more important work, is when it is not working, i.e. when a server goes down and so goes the manager. I finally finished the project, and it works as planned. I only got the name wrong…
Introducing mersit, a Tiny Server Redundancy Manager
Pronounced “m-eh-rs-ee-t”, with the first “e” being like the one in “explain”, mersit is a simple Python script (Python 2.7, because I wasn’t sure what libraries were available for 3.x nor if my servers would run it well) hacked together with some sections that definitely look like spaghetti code. The good news is, it works fine, and has been well tested, so if you study it in the “black box” way, there are no big problems with it.
The purpose of the script is to manage the DNS records of the website served by the group of synced servers, in this case, tny.im. It runs on each server, in a peer-to-peer fashion. The peers select a single master, that will monitor all the peers and manage the DNS as they go up and down, “deciding who’s on stage”, and all peers will check whether the master is up, and select a new one that will edit the DNS to “hide the master from the public” when it goes down.
I definitely want to open-source mersit at some point, but not now because it’s not ready for prime-time (see “spaghetti code”, above), and I want to change some things that will make it more general-purpose. mersit has been managing the live records for tny.im for the past week (it’s been peaceful).

Continuing our journey through the world of meaningful graphs, here’s another.
I have gone so far as to write a read-me for mersit (mainly for me to read, as I know I’ll forget how it works within six months). I think it’s best if I put the start of the read-me here, instead of trying to explain it all, once again:
mersit - Tiny Redundant Server Manager
Copyright 2014 tny. internet media
This version is customized for tny.im
This is a Python 2 script that manages a group of computers/servers/thin clients/machines in a network (local- or wide-area), by automatically executing actions when something relevant happens to one of the machines.
We'll call the "machines" "peers". mersit assumes all peers and the network are trusted.
The script is meant to be run directly on the peers that are to be controlled, in a setup where there is not a single point of failure. It is not of much use when run in a single peer; in the context of this script, a "group" only starts to make sense when it has over one element.
We'll refer to this script as "controller software" or simply "controller", and to the other software that runs on a peer and which is to be monitored as "application". The controller is made to run unattended, even though it accepts commands (issued by an "operator") to trigger certain behavior manually.
The "something relevant" mentioned in the first paragraph consists on one of these "events of interest":
- A peer goes "online", that is, it is reachable by other peers and reports the status of its controller software as "OK" or "ready";
- A peer goes "offline", that is, it is either not reachable by at least some peers, or the controller is reporting its state as "not good" or "not ready";
- A peer becomes good-for-work (GFW), which means, that the application is functioning properly and performing its function (such as listening for incoming connections, data to process, etc.);
- A peer becomes not-good-for-work (NFW), in which case the application is not functioning properly, is too busy to perform its function (over capacity), or is otherwise unavailable.
Each peer works in a given "domain", which is the group the peer belongs to. The domain is specified by a name and secret which act basically like a username and password pair. Peers will only communicate with other peers of the same domain, that is, peers where the domain name and secret are the ones the controller is configured to use. The domain acts as the authentication element; an external party can not join, communicate or perform actions in a domain unless it knows the name and password used by the peers of the domain.
(Please note, that communication between peers is not encrypted by the controller - it goes completely plain-text over the network. It is possible to secure the communication between peers using external tools; such secure functionality goes beyond the scope of this software. The "domain" is simply a basic authentication system, implemented using HTTP authentication, to ensure that peers of a certain group don't start talking with peers from other groups. The basic authentication system is enough to protect against the casual script-kiddie, but by no means adequate for protection from a malicious party in an untrusted/open network)
The controller on each peer must know _a priori_ (i.e. before it starts) about where to find at least some of the controllers on other peers. Peer discovery doesn't happen automatically, however, once a peer's controller can communicate with another controller, it will add every controller in the "contact list" of the latter to its "contact list".
Imagine the following situation: you have peers A, B and C (and their controller software). The controller in A only knows about peer B. The controller in B only knows about peer C. If you start the controller on peer A, then start the controller on peer B, peer A will tell peer B about its existence, and peer B will tell peer A about the existence of a peer C (independently of peer C being running/reachable). However, if the controller in A knew about no peer (other than itself), it would never find peer B or C even if their domain settings all matched. Even though a big domain can be bootstrapped from just two peers, to ensure good operation, all controllers should know about all peers. This way, if the controller on a peer resets for some reason, it will have a greater chance of reaching another peer.
The "contact list" is the list of "known" peers. The controller keeps three lists of peers in memory: the "known" peers, the "reachable" peers, and the "GFW" (good-for-work) peers. The list of known peers is initialized from the source code's configuration section when the controller starts. It then proceeds to see which peers are "reachable", that is, can be reached through the network, are in the same domain (not being in the same domain gives the same effect as not being reachable over the network) and have their controller software report its state as "OK".
This initial status checking includes the exchange of some other information about the controller. Once this initial peer identification is done, the controller enters a monitoring loop where it will keep the contents of the three lists up-to-date. The controller keeps running this infinite loop throughout most of its lifetime. How the lists are kept up-to-date and what happens when their contents change is something that depends on the current controller mode.
There are two possible modes for controller operation: master and non-master. There is exactly one controller in master mode per domain, and this controller is usually called "the master" (the master peer has the controller in master mode). The differences between the modes are mostly related to what happens in the monitoring loop, but before going into those differences, it is important to understand how the controllers decide which peer is the master peer.
When a controller starts and there are no reachable peers, it promotes itself to master, since there must be exactly one master per domain. Later, when another controller joins the domain (either because it started or because it went online after e.g. a period without connections or power), it checks which peers are reachable from its "known" list and "asks" them which is the master peer. Every peer should reply with the same peer, in which case the new controller assumes that peer is the master, and informs the master about its existence, to account for the fact that the new peer may not be in the master's "known" list.
However, and especially on domains where not all peers initially know about every other peer, it's possible that a "head split" occurs and there are two masters in the same domain. Imagine a domain where there are four peers D, E, F and G. D only knows about E, which in turn only knows about D. F doesn't know about any peer, and we'll leave G aside for now. All peers are offline.
The D controller starts up, sees it can't reach the only peer it knows (E), so calls itself master. The E controller starts up and reaches D, D says it is the master, E assumes D is master, all is fine.
The F controller starts up, sees it can't reach any peer because its "known" list is empty, so calls itself master and sits quietly waiting for someone to contact it, which in turn would let it know about more peers.
We now have the following situation ([M] represents a controller in master mode, --- represents the knowledge peers have of each other):
-DOMAIN------------------
| |
| D[M]-----E F[M] |
| |
-------------------------
Things could be like this forever, and no conflicts would occur - however, this is probably not a domain you want to have, since F doesn't know about any "event of interest" related to D or E, and these two don't know about any events related to F. In this situation, D--E and F act like separate domains.
Assume that G is a peer which knows about D, E and F, and that its controller starts up, contacting D, E and F. The first two will agree that D is the current master, but F will disagree and say it is the master. At this point we have a conflict. There are many ways to solve this, including some form of "voting" (e.g. the peer the largest amount of the peers say is the master effectively becomes it), but mersit solves this in a simpler way.
The controller checks that everyone in the domain agrees on what peer is the master on every iteration of the monitoring loop. It does this by "asking" each peer in the list of known peers who is the master. The first peer asked is free to reply with any peer. The ones that are asked next must agree with the first one. If not, the controller that was doing the loop tells each disagreeing peer that the actual master, is the one from the first peer's reply. It is possible that a minority is asked first, and thus everyone is forced to "change its opinion" to that of the minority. This is not a problem - mersit assumes all peers are trusted. Note that it can sometimes take some iterations of the monitoring loop for all peers to settle on a single master, because two (or more) peers may be trying to "change the opinion" of the other peers to different masters. This is not a problem either, because even if this kind of concurrency conflict happens once or twice in a row, it will stop happening as soon as one peer is faster than the other to tell everyone (including the other peer(s) that are trying to "change opinions"). What matters is that in the end, every peer knows about all others, and there is a single master. In this case, it could be D:
-DOMAIN--------------------
| |
| D[M]-----E-----F-----G |
| |
---------------------------
If the master becomes unreachable, or its controller stops working, the other peers will also find themselves a new master, by sorting the list of reachable peers alphabetically and choosing the first peer in the sorted list. Of course, if for some reason the list is not consistent across peers, the peers will try to "convince" others to settle on who they "think" is the master as previously explained, until everyone is set to the same master.
Being the master essentially changes what happens in the monitoring loop. When a controller is in master mode, it is responsible for updating the list of "reachable" and "GFW" peers, by checking which peers are reachable (both in terms of network and in terms of functioning controller) and which have the application in a working condition. If there are changes in the lists that indicate an event of interest, it runs the appropriate handler. If, for example, a peer becomes NFW due to a problem in the application, it will stop being in the GFW list, and the handler function for when a peer leaves that list will be run with the peer in question as the argument. If the master becomes unreachable (network error, controller error, etc.), a new master will be found, as explained in the previous paragraph, and the new master is responsible for running the handler with the previous master as argument.
When a peer is not master, it won't run any handlers for events of interest, and it is not responsible for updating the "reachable" and "GFW" lists - it will retrieve these from the master. The controllers on all peers need to keep their lists up-to-date, sharing a "vision of the domain" similar to that of the master, so that any peer can become a master instantly in case of necessity, without having to spend time performing checks on all peers and ensuring it has the best-and-latest list of "known" peers.
The operator can manually tell a controller to become the domain's master. When the appropriate command is issued, the controller will send a command to every other controller instructing them to switch to the new master. This command may not always have an effect in some controllers, because while the first controller is sending the commands, other controllers are seeing if everyone agrees on who's the master, and issuing the same commands with another master in mind. This is a sequence of events picturing the situation, in a domain where there are three peers H, I and J, and H is the initial master:
0. ...
1. Peer H checks that every controller agrees it is the master (all agree);
2. Peer I checks that every controller agrees H is the master (all agree);
3. Peer J checks that every controller agrees H is the master (all agree);
4. Operator issues command for peer I to become master;
5. Controller on I assumes it is master, starts sending commands to other peers;
6. Peer H checks that every controller agrees it is the master, before the message from I that I is the new master can get to H;
7. Peer H finds out I (and possibly others) don't agree, sends them commands to change the master back to H;
8. Peer I changes master back to H;
9. Peer I checks that every controller agrees H is the master (all agree);
10. Peer J checks that every controller agrees H is the master (all agree);
11. ...
If the master doesn't change when the manual command is issued, it's a matter of trying again. Most often, this kind of concurrency problem does not occur, and even when it does, it does no damage. While it is true that mersit could detect this situation and keep issuing commands automatically until the decision takes effect, we chose to not make it this way to allow the human operator finer control.
The primary focus of mersit is to monitor a distributed application. The master checks if the application, or part of the application, running on a certain peer is in working condition by asking that peer's controller about the state of the application it is monitoring. In turn, this controller runs a function, defined by the mersit user in the mersit source code, that should check the application and return True (if application OK) or False (if not). This can involve, for example, making a HTTP request to a HTTP server in that peer to verify it is working. The controller then communicates the status of the application to the master (which may be itself). All this shouldn't take too long, especially when the domain has many servers, as only one peer is asked at a time. If checking the status of the application typically takes over one second, it is best to store the last known status in a variable, and update that state periodically in an asynchronous manner that may be external to the mersit script.
The part related to DNS records is not explained on the read-me, because it is related to the handlers (which each mersit user would customize to the specific needs of the system – as I said, I tried to make it a general-purpose script). Sounds interesting? Feel free to ask questions, or point out problems, in the comments.
November 26, 2013 / gbl08ma / 0 Comments
Note to self:
By default, Linux Mint brings OpenDNS (which I hate, if not for anything else, for the NXDOMAIN response it gives) as the resolvconf fallback. Deleting /etc/resolvconf/resolv.conf.d/tail as root and then restarting the resolvconf will (re)solve it. Do not waste time trying to figure out where the DNS is being hijacked on your network: the thing is right on your machine, even if you have overridden the DHCP DNS configuration on the network configuration dialogues – out of the box, it will always use OpenDNS if the DNS servers you or DHCP specified, are not available/don’t answer fast enough.
By the way: http://myresolver.info/ helps with debugging DNS issues.
This post brings to an end months of trouble, and me thinking my ISP, to add to the fact that even though my plan is unlimited, severe speed limiting starts at 15 GB of data usage, was also hijacking DNS queries to their own system. Fortunately, looks like it is not the case. At the same time, I’m disappointed with the choice of DNS fallback by the people behind Linux Mint.
September 4, 2013 / gbl08ma / 0 Comments
Every news piece I see about Microsoft buying Nokia, seems to focus on the business side of the things – “was this a good move for Microsoft?”, “was this a good deal for Nokia?”; on the future of Windows (Phone), and on the patent portfolio Microsoft just licensed for 10 years (to me, in practical terms this equates to buying…). But I think everyone is forgetting what Nokia did before the Microsoft partnership involving Windows Phone, more precisely the software that runs on their older phones. What will happen to these pieces of software, some abandoned and others not?
I am not a Nokia user and I haven’t had extensive contact with their hardware or software. I do have some friends with modern Nokia feature-phones and non-WP smartphones, and I know a bit about their experience with them. I have also tested some of Nokia’s experimental/in-development Linux based systems on emulators (yes, Nokia wasn’t just Symbian and WP). That said, I apologize for any wrong facts on this post. I will be using Wikipedia as a (improper) “source” for some things.
Nokia developed, or supported the development, of several embedded operating systems. These ran and run mostly on feature-phones, despite some of them supporting third-party software and having other features that make me label them as a “smartphone with alphanumerical keyboard”. S40 is an example of this, having debuted in 1999 and being used until 2012 (it powers the recent Nokia Asha phones). (source)
Recently, Nokia has also developed Symbian-based systems that run on touchscreen smartphones.


The Nokia 7110 (1999) and the 6300 (2007) are both powered by S40
Then there’s Symbian, which was born not just as a Nokia venture. Symbian, a proper smartphone OS, was born as “a partnership between Ericsson, Nokia, Motorola, and Psion” (source). Nokia used Symbian on most of their earlier smartphones, being the responsible for Symbian’s really high market share, which lasted until the end of 2010.

Nokia N80 (2010), running S60
The S60 platform, first released in 2002, was based on Symbian and during the course of its life, it powered phones with and without touch screens (yet again, cases of smartphones with alphanumerical keyboards). Later in 2010, Symbian^3 was released, to power the Nokia N8. More or less by the same time, Symbian, once made open-source, turned into a licensing-model only.
In February 2011, Nokia announced they were dropping Symbian-based systems in favor of Windows Phone. Later that month, the Nokia 808 PureView, with a 41 (forty one) megapixel camera (just like this newer one), was announced, to officially become the last Symbian smartphone.
Nokia Anna and Symbian/Nokia Belle were released later in 2011 as updates to Symbian^3. Some time between Anna and Belle, Nokia outsourced Symbian support and software development to Accenture, a situation that will stay until 2016. The second feature pack of the Belle update is the latest version of Symbian as of now. Will it be the last? I would say so.

Screenshot of Nokia Belle
Nokia also developed apps and internet services for the later Symbian updates (these included an app store, the Ovi Store). Ovi was the brand for many of these apps and services. Among the Ovi apps, there was Ovi Maps, later renamed to Nokia Maps in 2011 and now called Here. Here runs on many mobile operating systems, not limited to those developed by Nokia, and provides map and traffic services to Windows Phone 8. (source)
From Belle on, it’s what you probably already know – more and more Lumia smartphones powered by Windows Phone. For feature-phones like the 2012 Asha models, Nokia seems to have reverted to S40, not Symbian-based.
And this is the story of Nokia’s moderately successful operating systems more or less known by the common user. But Nokia invested in other projects not so widely known to the general public, but which developers know well. It is the case of the Qt framework, which was developed by Nokia after they bought Trolltech, the original developer. Qt was used in Symbian; a bit after Nokia dropped Symbian, they sold the licensing stuff to Digia, that now owns the Qt trademark and the Qt Project.
Nokia also invested in other OS projects besides S40 and Symbian-based systems. Maemo, an open source software platform intended for smartphones and tablets, was based on Debian Linux. It made its first big appearance in 2009, with version 5, as it powered the Nokia N900. From my point of view, this device had some flaws and ended up being only loved by Linux geeks. But this is my personal opinion, of course. I know I would have liked to own one of these 🙂

Nokia N900 (2009) running Maemo 5 / Fremantle
By February 2010, it was announced Maemo would merge with Moblin, to create MeeGo. Finding the story complicated already? The best (or worst) is yet to come… In September 2011, roughly a year and a half after that merge, the Linux Foundation, which hosted MeeGo at the time, announced it would be terminated in favor of yet another project, Tizen. By the same time, Mer appeared as a fork of MeeGo. A company called Jolla, from Finland, then started cooperating with the Mer project to create the Sailfish OS. Confusing enough?
Basically, from the initial two development efforts (Maemo by Nokia and Moblin by Intel) we walked towards six (and counting) different mobile-oriented Linux-based operating systems, some dead, some dying and others just starting. There doesn’t seem to be much app compatibility between these – other than good old Linux binaries (but that applies to Android too and I’m not talking about that kind of apps), and maybe some HTML5 apps (and of course, all the web pages).
In case you didn’t notice, Nokia (now Microsoft) is obviously not involved in any of the current projects (Tizen, Mer or Sailfish) – it’s just not part of their new strategy (and if for some reason anything Linux was involved in the current strategy, I’m sure Microsoft would dump it ASAP, or at least hide it from the public).
Obviously, as of now, one can’t even speak about the market share of these six mobile OS, without having to use scientific notation with negative exponents and a big amount of small-number guessing. To my eyes, Maemo, despite being old and officially unsupported, seems to have a bigger community (and, I guess, a bigger market share) than any of the other small projects that were born from it and forcibly declared as its successors. Or perhaps, I should say that a big part of the community is still centered around Maemo – even though most of the development actually occurs on the new projects.
Add the six I mentioned, to the count of other newborn mobile OS (Firefox OS, Ubuntu for phones…) and make your bets on which one (or whether any of them) will get a market share we can measure, with a percentage above 1%. Maybe if they all got together and united their efforts… oh wait, refer to “MeeGo” for the expected result. But, I’m getting off-topic…
…or perhaps not so off-topic. Nokia, before Microsoft, and during the course of its handset making history, also developed a bunch of different platforms – S40, Symbian and everything that ran on top of it: S60, Symbian^3, Belle and I may be forgetting some. Not all of these were compatible with one another and they had different user experiences. Now compare this to Apple’s iOS since the first iPhone, or Android since the first phones that ran it. Sure, there were lots of updates to each of these systems, and sometimes the user experience changed a lot, but they never changed names and there was always some kind of data and app compatibility.
Applications one developed for Android 1.6 most likely still work fine in 4.3, even if sporting an outdated user experience. The user experience has changed but progressively, and much of the practice an user gets from using earlier versions is still valid on the latest. On the Nokia side, from S60 onwards, there was some app compatibility (but from what I see, not as good as Android’s or iOS’s), but the constantly changing names and looks confuse consumers.

MeeGo also ran on netbooks, in-vehicle infotainment devices and other embedded systems.
Since the Linux-based Maemo and successors had nothing to do with Symbian, Symbian-based and Linux-based systems always lived in different universes, despite being both made by Nokia for similar devices. And now Windows Phone has nothing to do with either Symbian or Maemo/MeeGo – it’s yet another “ecosystem”. Talk about fragmentation in Android, and I’ll show you all the systems created by Nokia.
Nokia managed to start more mobile OS projects than companies like Microsoft, Apple or Google, and yet didn’t manage to stick with any of them, except maybe Symbian… but even on the Symbian land, there were lots of changes to user experience over the time, and to the end user it definitely didn’t feel like it was the same OS when they bought a new phone.
And now that Nokia is basically Microsoft, users of the multiple platforms that reached the mainstream consumer before Nokia made Windows Phones, are pretty much screwed. Nokia/Microsoft no longer cares about their non-WP phones except for what I call “traditional support” (phone breaks, gets replaced or repaired; security bug is found, gets fixed) – but users expect other types of support for smartphone OS, namely updates (to fix non-critical bugs, for example). And maybe even the traditional support is compromised.
I see a lot of wasted work and money on the Nokia side, investing on things that eventually never went forward because at some point they lost support from Nokia. I even think much of the recent waste over the past two/three years was purposeful (*cough* Stephen Elop *cough*). At the same time, I can see the old Nokia strategy as “not putting all the eggs in the same basket” – they weren’t just committed to Symbian, but also S40 and Maemo/MeeGo, and later Windows Phone. Then they decided to drop all the eggs but S40 and Windows Phone. And now that Microsoft bought Nokia, I believe they are going to drop the S40 egg too.
Ultimately, I believe this isn’t good for the consumer. It loses yet some more mobile OS choice, even if these choices weren’t so popular – at least, they were something different. The choice is more and more between Android, iOS and Windows Phone, and if the currently in-development projects don’t hurry to get on the market to earn some users, they may suffer the same fate as all the other ones that got killed or merged, eventually turning them into abandonware.
March 3, 2013 / gbl08ma / 0 Comments
Seeing that I’m getting a lot of hits on this blog from people searching about the SliTaz servers being down right now, probably because I have a blog post with the words “SliTaz” and “dead” on the title, which was published over a year ago, I’d like to inform that I know nothing about the server situation other than the fact that the website is unavailable for me too.
(talking about SliTaz, I kinda stopped following the project, even though I find it interesting… note to self: pay more attention to it from now on)
August 27, 2012 / gbl08ma / 0 Comments
I was playing around with my cheap Flytouch Android tablet, using dd to create images of the different partitions of the internal storage (which is, in fact, just a microSD card).
Turns out I discovered that there is a 256MB FAT partition living on /dev/block/mmcblk2p6. By this time, geek users already know what to do: with root privileges, mount the partition in some directory..
So, open a terminal on your rooted Flytouch 3 (P041 and DK1031 models should have this partition). Type:
~# mkdir /mnt/sdcard/256MBfat
~# mount -t vfat /dev/block/mmcblk2p6 /mnt/sdcard/256MBfat
This should result in a new folder in your sdcard directory. This folder is a filesystem node, like the sdcard1, udisk1 and udisk2 folders.
This FAT partition is empty and should have about 256MB space. If it isn’t, or if the mount command returned an error, then that’s interesting 🙂
Why is this partition in these tablets? Well, I have a theory. These tablets support having a recovery partition, even though most firmware updates provide no recovery image files. The fact that this is a 256MB partition may indicate that it is meant to hold contents similar to the system partition, and in this case, it should be formatted as EXT3 and not FAT.
As most firmware versions for this tablet available on the internet don’t include a recovery image, this partition just gets formatted as FAT by the updater kernel at update time.
But what if the updater never touches this partition? This would be pretty good news. You could use this more or less hidden partition to store the owner information, so if your tablet ever gets stolen you’d always have a way to recover it.
If that was the case, you could also use this partition to store essential APK files and configuration so it would be easier to recover from a firmware update or factory reset.
As a last and kind of unrelated statement, I’d like to point out that the bootloader of InfoTM tablets is much more complex than it may appear at first.
Through a serial line that I believe to be the A-A USB connection used by IUW to burn updates, the bootloader can provide a serial console, that can be used to change the boot parameters for Android and maybe even boot other operating systems from the external SD card.
This thing of the bootloader is something I’m figuring out slowly by analysing the uBoot update file I have, u-boot-nand.bin.
If you have one of these InfoTMIC tablets, feel free to comment below with any important additional information.
NOTE: this post was written months ago but was sitting on a text file on my desktop for months, waiting to be posted. So this isn’t a recent discovery, but still an interesting one.
April 13, 2012 / gbl08ma / 3 Comments
Looks like my servers and websites have all decided to take some holidays and go offline, fortunately not at the same time. Some weeks ago, it was 4.l.to/l.f.nu that decided that some days sleeping would be good, after its domain went down (causing the change to a new one and the whole service rebranding). And more recently, the VPS where I was (yes, was) hosting this blog, which by its turn was hosted in a friend’s dedicated server, went down the trash too: the guys at the provider my friend uses decided to play around with the hard drive of the dedicated server, and we ended up without any of data that was in it.
Unlike what’s usual, this time I had backups (yepeee!). But as always, they were outdated (from January!) and consisted of a WordPress export file. So, I didn’t have any backup of the server configuration or the other scripts and data I had in the server. Conclusion: I had to set up everything from scratch – but wait, first, I need to explain: my friend offered to install WordPress for me, (as I’m very busy with real life, I’ll explain later), but he used CentOS, and since I really don’t like CentOS and there were some tiny “wrong” details in the WordPress config (just a matter of personal choice: I do not like to use “admin” as the admin username, even for security reasons), I reloaded the VPS with Ubuntu.
*Ubuntu: I would have used Debian, if it weren’t for the fact the software in its repos is, although stable, far from being the latest version. And my idea of “stable-recent” ratio for software is not quite the same as Debian’s idea.
As I was saying, I had to setup everything from scratch on a new VPS, on another dedicated server that’s not from the same provider (but the dedi is from the same friend). That means some hours around the shell installing and configuring nginx, PHP and MySQL, as well as configuring WordPress-specific rewrite rules and other server settings – and I’m not finished yet, the current settings are not how I’d like them to be.
I said above I was very busy with real life: yes I am, I’m busy with lots of school work, and I’m also a bit tired of the online world for now (the part of the internet I use/follow has no news lately, things are pretty boring currently). But today I had a school trip for the whole day that got me really tired, and when I got home, I felt like I wouldn’t be able to study anything for the school tests I’m taking in the next weeks. I had a server to configure and a blog to restore, and thought I could use the free time… and here I am, blogging when it’s almost midnight on my clock.
Despite the hours spent, I’d say my work has been done without major problems. I’m getting either too used to installing nginx+php+mysql, or it’s because it is/was Friday 13th.
Yeah, is/was. It’s four past midnight.
EDIT: this server is now much faster, its host was suffering from some misconfiguration – again, my friends are awesome and fixed it 🙂
February 21, 2012 / gbl08ma / 1 Comment
My last blog post has been about the fact that ReactOS is not a dead open source project, and that in fact they had just released a new alpha version. So to keep with my line of open-source-projects-journalism, today I talk about another open source project, this time a GNU/Linux distro: SliTaz.
You may have heard about this project before: SliTaz has been around since 2007, when the first “cooking” version of the distro was released. But what is SliTaz? As it says on the official website, it is “a free operating system providing a fully featured desktop or server in less than 30 MB”. And indeed, you download an ISO file that weights at about 30MB, which you can burn to a USB stick, CD or DVD, or run on a virtual machine. From there, SliTaz boots to a complete desktop with various utilities and office applications, server-side software and, of course, a web browser. A nice control panel lets you configure the system and install more applications.
The whole system runs in a small amount RAM, meaning you don’t need to install it to a hard disk to be able to use it; when you turn off the computer, the changes made are lost. So, this is not more nor less than a LiveCD that has a size of ~30MB. It is very fast, even on older computers.
Is this news? No, there have been tiny Linux distros around before, and SliTaz itself has been around for a lot of time, as I told. Damn Small Linux, Puppy Linux and TinyCore are some examples of other GNU/Linux distros that have the goal of being small in size. I particularly like SliTaz because of its uniqueness: a unique packaging system (tazpkg), unique utilities, and a unique look too. DSL and Puppy Linux are already too “big” for me, and TinyCore is too small to be useful to me. So SliTaz just got it right for my concept of “tiny Linux distro”.
I don’t use SliTaz every day – it’s not my daily use distro – but I still like it very much and it’s been useful to me a few times. I use to keep around a USB pendrive with a copy of SliTaz installed – one never knows when it may be useful, specially after you’ve installed office tools like Abiword and Gnumeric. Of course, your idea of usefulness certainly varies from mine, and that’s why I like open source: just change it so it works the way it’s useful to you.
There have been no cooking or stable releases of SliTaz recently, and there was a lack of word from the developers. I started to think that the project was slowly becoming abandoned. Fortunately, today I checked their website, and this is what I see: news! Well, not really in the news section, but a blog post: Lack of news but work never stops.
So, in conclusion, it seems the project is still active, the only problem is that everyone is too busy to release cooking versions and write press-releases. And it looks like the team is working to get a cooking version out soon, which is great news, since the latest cooking was in May of last year and it’s out of date when compared to the work that’s been done on the repositories since that time.
To the SliTaz developers: Keep up the great work! 🙂
Edit 23rd February 2012: Slitaz 4.0 RC1 is out! Check how the new version looks like.