January 15, 2018 / gbl08ma / 0 Comments
If I haven’t posted much here, it’s in part because the masters degree I’m pursuing is quite demanding, and in part because my “creative writing” time is often spent replying to interviews for Portuguese national media (and dealing with the exposure, which sadly is not expo$ure) about my UnderLX project, over the last few months:
http://www.sabado.pt/portugal/detalhe/as-perturbacoes-no-metro-de-lisboa-sao-tantas-que-inspiraram-uma-app
https://www.noticiasaominuto.com/pais/937964/linha-mais-problematica-horarios-pico-de-falhas-app-poe-o-metro-a-nu
…and with more to probably come 😉
September 2, 2017 / gbl08ma / 0 Comments
I neglect this blog very much. I write a non-negligible amount of stuff on the internet, but it’s usually on forums, Reddit, Hacker News and similar, and this blog ends up forgotten. I just wrote a 2000 words post on at CodeWalrus, about the current state of Clouttery, but since it also contains a personal-life-log part, I thought it would be the perfect thing to cross-post here. It’s not the first time I paste forum posts here, and it’s something I should probably do more often, as it helps keep this blog alive while at the same time preserving posts that, while usually made as replies to a forum topic, are general enough to stand on their own.
Hello everyone again. I figured it was time for an update, even though this is not exactly a “happy” update, at least as far as Clouttery is concerned. This is a long post, bring it to bed so you can fall asleep to it if you wish, but trust me, it’s worth reading. I hope you can learn a thing or two about managing your side projects, from reading about my mistakes.
Last school year was the last year of my undergrad course (and I’m starting a second cycle course in a couple weeks) and this required some more effort, so I had less time for side projects. As often happens when one works on something for an extended period of time, I too gradually lost interest in this project.
To make things more… interesting, in mid-March I launched a small website that was meant to be kind of a practical joke about the unreliability of the Lisbon subway (for those who haven’t yet figured it out, I’m Portuguese). You’ll be able to understand what it is about by checking out its repo on GitHub.
I started that project mostly to have something different to work on that was not Clouttery, and the original plan was for it to be something I’d build in a few weeks, publish and then forget, for it to be yet-another-small-thing in my portfolio. But to my surprise, after minimal “marketing” on the SkyscraperCity Portuguese community, that has a section dedicated to railways and subways, my website received a lot more attention than I was expecting, especially for something so simple and tongue-in-cheek.
I then understood there was a real interest in a service that would let people work-around the problems in the Lisbon subway, while at the same time denouncing the problems with the service (for example, by collecting independent statistics). Long story short, a small community assembled around this project, which ended up evolving into an Android app called UnderLX that’s even published on Google Play. And there’s still a lot of work to do for it to become the product I envisioned.
This obviously took most of my summer.
Yes, it’s true that, unlike Clouttery (for which I had even written a complete billing system from scratch!), I’ll never be able to monetize UnderLX effectively. However, it is way more satisfying to work on, at least until I get saturated of it too. With Clouttery, it often took a while to realize what it was about, and let’s be honest: the final reaction of many people was just “meh”. However, with UnderLX, people tend to pay a bit more attention, and those who understand the whole potential of the project usually become much more involved in it. “Unfortunately” for me, the technical side of it is more complex than Clouttery.
It also has an “advantage” to my eyes: both the client (Android app) and the server are open-source from the first day. I regret not going this route with Clouttery; now I have lots of closed-source code which I can’t easily show to anyone because, well, it’s in private repos. I’ll go back to this point, later.
Finally, to add to the school work, the gradual loss of interest, this happy accident that was UnderLX, there’s a fourth factor in all this. Because of multiple reasons including the astronomical rise of the price of Bitcoin, it made economical sense to fulfill a long-time desire of mine: to build a desktop, so I could have a powerful machine, more powerful than my six-years-old laptop. Picking parts and putting it together was very enjoyable, and now I have a proper workstation like I had been dreaming of for the past couple years. If you are interested I might even post a thread about it here. I wasn’t much into PC gaming before (in part, because the hardware didn’t really allow for it), but… you see… to sum things up, many hours were spent chilling to some great triple-A titles (thanks Steam summer sales!…). 
That’s all really nice, but I thought this topic was about Clouttery?
Work on Clouttery gradually slowed down through the last months of 2016, subject to how busy I was with school, and pretty much completely halted in March this year, as I got more and more tired of working on it, so I decided to do that “small” subway thing. It also didn’t help that I was going through a complex phase with Clouttery, more specifically regarding the Windows and Linux clients.
- I couldn’t get the Linux client to work right, despite trying to develop it from scratch multiple times using different languages and technologies. No matter what I tried, there were always major roadblocks to getting it to the point I wanted. I did not want to write it in C or C++; I hate Python but decided to try using it anyway – didn’t end well; UI framework bindings for Golang are apparently all terrible, or don’t have a suitable license. Mono would have been a viable choice, but the gtksharp bindings were tricky to get to work, they apparently had to be recompiled for each GTK version (meaning I couldn’t simply distribute a single binary), and the bindings for GTK3 aren’t/weren’t exactly ready for prime-time. Ugh, I don’t even know what all the problems were anymore. I do remember that I just wanted to write code, but problems with libraries and bindings and whatever were always getting in the way.
- The UI of the Windows client suffers from major lag and other problems, so I decided to switch from WinForms, which is no longer supported, to the supported and way more modern and flexible alternative: WPF. But this was taking a lot of time, certain things were much harder to get to work than I expected, it didn’t help that I only had time to work on it like one hour at a time (school work, etc.), and I lost more and more interest.
For you to get an idea of how inactive this project has been, these are the dates of the latest commits to Clouttery repos:
- Server: 2017-07-10 (and this was only to fix a bug with notification filtering; previous “real” work on it had been on the 23rd of March)
- Windows client: 2017-03-26
- Android client: 2016-12-29
- Chrome client: 2016-09-08
- Linux client: 2017-03-09
Earlier, I mentioned I regret not open-sourcing Clouttery from the beginning. I decided to work on it privately, because it was supposed to become a commercial service, and I feared that if I made it possible for people to host their own Clouttery servers and recompile the clients to talk to it, then nobody would pay for the service. This is obviously a stupid way of thinking, especially when the project in question is a personal project of a student that doesn’t have much time to work on it, and likely would never be able to get it to a commercially-viable state. If the service was worth it, I guess most people would happily pay for it, just to not have the hassle to figure out how to make the server and clients work for themselves; this is especially true since the target audience wasn’t exactly software developers nor sysadmins, i.e. it was people who wouldn’t have a clue how to do that nor would bother even if they were given clear and easy instructions.
Right now I have 30K lines of code, possibly more, that’s closed-source, but for no good reason. To aggravate things, Clouttery shows more of my abilities in software development and engineering than any of my open source projects, because it contains code in more languages, for more platforms, than any other of my projects; it includes web design, API design, use of cryptography, etc. It is not the most beautiful code (for example, the UnderLX Android app has much cleaner and organized code than the Clouttery client, and even then it’s not exactly stellar), but it works, and definitely shows what I’m capable of.
This whole situation is even more ridiculous, because right now there’s very little to no code in Clouttery that’s “novel” to the point of requiring intellectual property protection.  At this point, Clouttery is extremely dumb, as I never got to work on the “intelligence” that would involve machine learning, pattern matching and the like. And in the end, if I wanted to make my super-awesome-and-courageous battery level prediction and damage identifying algorithms secret, I could always have added them as a closed source module while keeping the “infrastructure” open source.
At this point, Clouttery is extremely dumb, as I never got to work on the “intelligence” that would involve machine learning, pattern matching and the like. And in the end, if I wanted to make my super-awesome-and-courageous battery level prediction and damage identifying algorithms secret, I could always have added them as a closed source module while keeping the “infrastructure” open source.
Finally, I always told people that if I were to stop working on Clouttery, I would release its source code. I don’t know what you think, but if I half-close my eyes and look from far away… yeah… like that… yep, I definitely stopped working on it. 
Then why don’t you open source Clouttery?
I definitely want to open source Clouttery, so I can show its code to more people, and so that others may eventually try to pick up on the project. I intend to keep running the official Clouttery server – if for no one else, for me, as my family finds Clouttery useful. I think I would be a little sad if someone took the project and simply changed its name and started running their own “official” service, available to the masses and possibly profiting from it, so I’ll see what kind of licensing restrictions I can add to prevent that. Without the help of a lawyer, it’s a bit hard to add clauses to existing software licenses or write new ones from scratch; even with legal help, it’s easy to get to a controversial result – for example, Facebook has that famous problem with the “patents” file on their open source projects, like React.
…so why didn’t you do it already?
Because ideally, I’d like to publish the source code with the complete commit history. The problem is that, in the past, secrets (API keys and the like) have been committed to the repos. If I remember correctly, the latest server code no longer has that problem – keys are read from a separate, uncommitted file and no longer stored in the source code, but going back in history the secrets are still there. Some of these secrets are hard to revoke and replace, and I’ll need to go on an individual basis to see what can be done about them. Furthermore, the clients also contain secrets in their repos, but this is just one secret per client that’s used to authenticate the client before the server, and since it’s relatively easy to get these secrets from the binaries anyway, I might just go and make them public anyway – their only purpose is to stop people from using the official server with unofficial clients, but if the whole thing is going to be open source, that doesn’t make much sense. These secrets are not involved in securing the pairings between clients and user accounts, so in terms of user account security, there’s no problem with publishing them.
I also need to write a bit of documentation explaining essential things about each repo, and ideally also explaining how to run the server, what needs to be in the database, etc. Or I could not care about any of that, and just have people figure it out by themselves – at that point, I make it hard for people to contribute, but at least people can already look at the code, which is much better than the current situation.
As you can imagine, all this takes time and effort, and I’ve been busy with all those things I mentioned in the first section. But with classes starting very soon, I’d like to get this going ASAP, or it’s not going to be done for some more months.
Did I “give up” on Clouttery too soon?
Is it a good idea to open source it, even if in the distant future I decide to turn it into a proper commercial service?
Do you agree it would have been better if it were open source from the beginning?
What license do you think would be most adequate? – don’t forget the server and each client can have different licenses.
Would you be interested in submitting pull requests for this project, perhaps even taking over one of the sub-projects or the whole thing?
Share your thoughts.
February 19, 2017 / gbl08ma / 0 Comments
I spent the past week, the last one of my winter break, redesigning how the Clouttery server stores data.
The Clouttery server, which is written in Go, was using a simple key-value store (Bolt). I slowly came to the realization that some of the features on the roadmap would be kind of hard to implement using Bolt; that the nested buckets structure used with Bolt was too limiting, by forcing a hierarchy on the data, when sometimes it could be useful to interpret it in other ways. For example, sometimes it could be useful to look at all the battery log entries from all users; with the database structure I had, that required looking into each user’s bucket separately, and within those, into each device separately.
The databases course I took last semester forced me to get my hands very dirty with SQL, and after seeing the benefits, I decided to move to a relational database.
Another reason for moving was that Bolt can’t scale (no replication, it’s meant for use by a single app, like SQLite), and while the server software is not yet ready to be clustered, moving away from Bolt (and, in general, uncoupling the server from the database) is a giant step towards the goal of being able to scale the server to multiple nodes. I had known for long that I had to use something other than Bolt if I wanted to make the server distributed, I just wasn’t sure whether to move to a relational database, another barebones key-value store, or some amalgamation of solutions involving specialized time series databases or what-have-you.
The database can now be accessed transparently by multiple applications, which means that, for example, in case I want to do some complex analysis on the battery histories, I no longer have to stuff that code into the server. I can even use a language other than Go, like Python, which I really don’t like, but has many libraries for data analysis.
I tried to use CockroachDB (and I can’t stress the terribleness of that name enough). At some point, the server was mostly ready to work with it, and it was time to import the data from the Bolt database. My code migrated all data in a single transaction, that was rolled back in the case of errors – that way, as I stumbled upon problems and general incompleteness in my migration code, I did not have to be constantly dropping and recreating the database, as with every failure the database would be always supposedly in a pristine state, with all the empty tables waiting for data.
Let’s just say things were not as smooth as I was hoping. On my laptop with an aging but still plenty fast i7, 8 GB of RAM and a SSD, data would get into CockroachDB relatively fast… but no matter if the transaction was committed or rolled back, once I tried to perform any query – basically any query, even if just counting the amount of users (about 40), would make CockroachDB’s RAM usage skyrocket, to the point where the whole system just hanged for seconds at a time, due to how much swapping was going on.
So I decided to scrap CockroachDB and go with plain old PostgreSQL. Given that the SQL supported by the former is relatively similar to what PostgreSQL supports, changing the queries to work with Postgres was not too hard. The most annoying part is the lack of support of PostgreSQL for the UPSERT command, which in CockroachDB and other databases, behaves like a INSERT when there’s no uniqueness conflict, and like a UPDATE when there’s a conflict (in which case it will update all the other columns). I had about ten UPSERTs that had to be rewritten as INSERT … ON CONFLICT (…) DO UPDATE SET – followed by all the columns to update. Ugh.
Importing data into Postgres was noticeably faster than into CockroachDB, and most importantly everything kept working fine after about a million entries were in the battery history table. And yes, everything was still inserted in a single transaction.
I took the opportunity to perform some long-needed changes to the data types used by the server. Making sure Clouttery clients kept receiving data with the formats and semantics they were expecting was a bit of a challenge, but very easy in the grand scheme of things.
As a very nice bonus, the server now does transactions properly. Previously, for a single API or website request, multiple Bolt transactions could be made. If something went wrong with one of the latter transactions, that one would be rolled back and no more transactions would be performed, but the changes done by previous ones would stay – like most databases, Bolt doesn’t let you rollback a committed transaction. Obviously, this could result in an inconsistent state.
Now, and after changing most functions in the server code to accept what can be described as a “transaction node”, each API request, web console request, or admin command works in a single transaction. Either there’s no error and everything goes through, or everything is rolled back. No more inconsistent data. sqalx was the library used to implement this.
The changes were pushed to production about two hours ago – after extensive testing on the staging environment, which unfortunately didn’t catch all the bugs. To identify problems, there’s nothing like dozens of devices running different clients and submitting different data to your server…
A few hotfixes later, everything appears to be working fine, but I’ll be keeping a close eye on the logs where, hopefully, all errors are logged. I say “hopefully”, because during testing I found out that the error return values (in Go, errors are values) from some of my own functions were not being logged, and some were completely ignored…
It would be great if over the next few days users could pay a bit more attention to the behavior of Clouttery, namely making sure that battery histories are updating as they should, and that notifications are generated when they should, according to their settings.
I’m probably a bit too much proud of this – at least, until I find a horrendous bug. This is how things should have been from the start, but at the same time, when I started this project, I did not know enough about relational database design to even do a mediocre job. So I went the easy, “no SQL” route and just used Bolt, which allowed me to get to something that worked, relatively quickly. And now I’m glad I could turn it into something better after about 60 hours of work…
I barely have time to work on Clouttery, and it becomes less and less of a commercially viable project as time goes by. It’s one of those projects that seems to never leave Beta status, and not for good reasons. But oh boy, the things I learn…
December 19, 2016 / gbl08ma / 0 Comments
I was casually going through my GitHub repos and came across PicoRed, a server redundancy manager I developed, with the immediate goal of managing the DNS records for the tny.im domain. The tny.im shortener used to be hosted by multiple servers in a Round-robin DNS configuration. The idea was that as servers went online and offline (or underwent maintenance, etc.), the DNS records would be automatically updated to reflect which servers are currently serving a service, in this case tny.im.
PicoRed is the successor to mersit, which served the same purpose but was written in very unidiomatic Python and was much clunkier than PicoRed (which is written in very unidiomatic Go, but used fewer resources and was somehow more stable). PicoRed and mersit were completely peer-to-peer, and this is because I couldn’t afford to have a “master” server that was stable enough and which I could be sure would have three nines of uptime.
The idea behind those tools is everything but novel; container orchestration, for example, requires similar tools to be deployed. For some reason, perhaps ignorance, back then I decided to write my own. (For an example of mersit/PicoRed done right, see Serf). I don’t regret it, of course: I learned a lot about distributed systems, and while my terrible consensus “algorithms” (a complete joke) worked, they taught me why things like Paxos and Raft had to be invented. The main takeaway was, “it’s complicated”. So for PicoRed I decided to use a library by Hashicorp that handled the hard parts for me (and that’s how my unidiomatic Go program was “somehow more stable”).
Three paragraphs into this post, and I’m still writing the introduction… these three paragraphs about distributed systems are just warming up for what’s coming, which is me saying that none of those homemade tools are in use anymore, and it’s not even because I switched to something better: tny.im, and some other services of the TNY network, are now served by a single server.
How did we get here? Back in 2014, I was a huge proponent of distributing every single service across many cheap servers, instead of buying a proper, rock-solid, big and expensive server from a reliable company. In theory, horizontally scaling would let one handle big amounts of traffic and improve availability at the same price, or even less – sounds great, right? These strong opinions were backed by the issues I was having with my BlueVM server. But now, we’re back to zero redundancy… what changed?
Well, my opinion is still the same: I’ll take horizontal scaling over vertical scaling any day, and the more redundancy that’s fit to pay, the better. The problem is when horizontally scaling begins to hurt performance and reliability instead of helping it, and that’s exactly what was happening in our case.
tny.im, dotAccount, PrizmID and my WordPress websites (this blog and the TNY network website) are powered by an extremely uninteresting LEMP stack. A LEMP stack is one composed by Linux, Nginx, MariaDB and PHP, or in other words, a LAMP stack but with Nginx instead of Apache. Until a few weeks ago, the “M” in this stack had the peculiarity of actually being MariaDB configured in master-master replication mode. What this means is that MariaDB was running on multiple servers, managing the same databases, and whenever a change was made, it was propagated to all of the other servers in the cluster (up to a few weeks ago, two servers; at some point in the distant past, up to five servers were used).
That’s how tny.im was served by multiple servers: simply by running the same PHP code in all servers, and having that code talk to the same database, replicated across all the servers. Of course, MariaDB master-master replication has its disadvantages. For one, performance is worse, because all database writes involve communication between the different MariaDB servers. This began to show on more database-intensive applications like dotAccount.
Perhaps more surprisingly, reliability is also worse. Perhaps I didn’t have MariaDB replication properly configured (after many attempts and hours spent, trust me), but it would sometimes break in wonderful states such as “WSREP has not yet prepared node for application use” whenever there was some network hiccup. This could happen as often as once a day, or once every two months (yes, networks are unpredictable like that). Whenever it broke, it would need to be manually restarted, and it would sometimes take multiple attempts until all the servers had their MariaDB running. In other words, exactly the opposite you want for a reliable system that requires minimum amounts of human supervision.
Perhaps PicoRed could have expanded into taking care of restarting the cluster, but since I couldn’t even get to a sequence of commands that, when executed on all servers at the right times, would reliably restart the MariaDB cluster, I kind of gave up. Lack of time and more interesting projects to develop, like Clouttery, meant that some stuff would inevitably get left behind, and my horrible mess of code called PicoRed ended up forgotten and eternally unfinished. Moving to proper solutions like Serf also required time that I didn’t have.
A few months ago I was notified that the provider of one of my VPS was closing, and all servers would be shut down by December 4th. I bought a new server, moved the stuff that wasn’t hosted anywhere else to it, but I really didn’t feel like reconfiguring the MariaDB cluster and PicoRed for the new server. PicoRed, in fact, stopped working in one of my servers (the one that wasn’t getting shut down) with some binary incompatibility error, a year or so ago. So I kind of gave up… reconfigured MariaDB so it stopped being a cluster, got rid of PicoRed, and said goodbye to one of the servers.
The new server is PHP and MariaDB/MySQL-free, and this probably won’t change. I would really like to move on from PHP and MariaDB to better languages and DBMSs. My main conclusion from the whole replication story is that MariaDB is not really prepared to scale horizontally, at least not without a lot of effort and “baby-sitting”.
I certainly have not given up on horizontal scaling, but I think that from on now, it’s best that I manage scaling at the application level instead of the database level, or alternatively, use a DBMS that was designed with horizontal scaling in mind, from the start. For the second option, it’s unfortunate that both CockroachDB and TiDB are still in a very premature state for production use.
I would rather not give up on relational databases; while it’s true that other types of database also cover some of the use cases of relational ones, I’m yet to know of any problem other than document storing that can’t be effectively solved with relational databases. (And for document storing, may I interest you in a relational database coupled with this strange thing called a filesystem?) Commercial solutions are obviously out of reach for me: it’s not like Segvault is a money-making machine; tny.im isn’t even profitable, despite all the ads!
I have grown to hate the mess of PHP and SQL that is tny.im so much, that shutting down the service (or at least getting it into a “read-only” mode) was once a topic for discussion at one of the TNY network meetings – all three of them. By the way, Segvault/TNY network is “hiring”, i.e. looking for new members with exciting project ideas, and if you had the patience to read this post this far, you may be a good candidate – contact me somehow.
Ads at tny.im earn me pocket change, that is used to offset the cost of the servers and domain names, and this shall be enough motivation to keep maintaining tny.im and supporting its users for some more years, updating MariaDB one version at a time.
June 28, 2016 / gbl08ma / 0 Comments
Because, why not? Let’s Encrypt makes it so easy…
Let’s Encrypt certificates are now used on all the websites maintained by Segvault, but not all of the websites of the TNY Network – the CPUVInf website, for example, seems to be using CloudFlare-provided TLS.
August 23, 2015 / gbl08ma / 1 Comment
Go to the bottom, “Summing it up”, for the TL;DR.
The day I turn this website into a portfolio/CV-like thing will come sooner or later, and arguably that’s a better use for the domain gbl08ma.com than this blog with posts nobody cares about – except when I rant about new operating systems from Microsoft. But if you really care about such posts, do not worry: the blog will still exist, it just won’t be as prominent.
Meanwhile, and off-topic intro aside, the content usually seen on such presentation websites everyone-and-their-cat seems to have these days, will have to wait. In anticipation for that kind of stuff, let’s go in a kind of depressing journey through my eight years programming experience.
The start
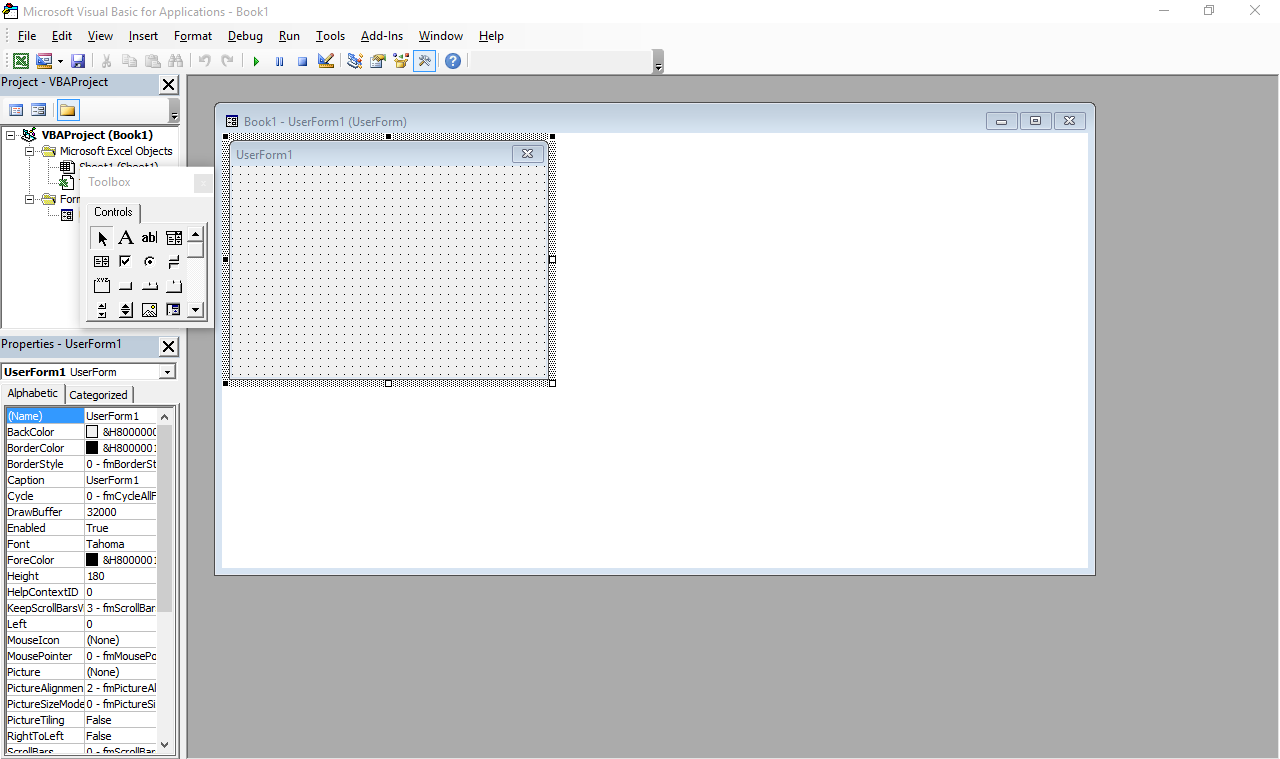
The beginning was what many people would consider a horror movie: programming in Visual Basic for Applications in Excel spreadsheets, or VBA for short. This is (or was, at the time; I have no idea how it is now) more or less a stripped down version of VB 6 that runs inside Microsoft Office and does not produce stand-alone executables. Everything lives inside Office documents.
It still exists – just press Alt+F11 in any Office window. Also, the designer has Windows 7 Basic window styles… on Windows 10, which supposedly ditched all that?
I was introduced to it by my father, who knows his way around Excel pretty well (much better than I will probably ever will, especially as I have little interest). My temporal memory is quite fuzzy and I don’t have file timestamps with me for checking, so I was either 9, 10 or 11 years old at the time, but I’m more inclined to think 9-10. I actually went quite far with it, developing a Excel-backed POS system with support for costumer- and operator-facing character LCD screens and, if I remember correctly, support for discounts and loyalty cards (or at least the beginnings of it).
Some of my favorite things I did with VBA, consisted in making it do things it was not really designed for, such as messing with random ActiveX controls and making it draw strange-looking windows (forms) and controls through convoluted Win32 API calls I’d have copied from some website. I did not have administrator rights to my computer at the time, so I couldn’t just install something better. And I doubt my Pentium III-powered computer, already ancient at the time (but which still works today), would keep up with a better IDE.
I shall try to read these backup CDs and DVDs one day, for a big trip down the memory lane.
Programming newb v2
When I was 11 or 12 I was given a new computer. Dual core Intel woo! This and 2GB RAM meant I could finally run virtual machines and so I was put on probation: I administered the virtual computers, and soon the real hardware followed (the fact that people were tired of answering Vista’s UAC prompts also helped, I think). My first encounter with Linux (and a bunch other more obscure OS I tried for fun) was around this time. (But it would take some years for me to stop using Windows primarily.)
Around this time, Microsoft released the Express (free) editions of VS 2008. I finally “upgraded” to VB.NET, woo! So many new things to learn! Much of my VBA code needed changes. VB.Net really is a better VB, and thank Microsoft for that, otherwise the VB trauma would be much worse and I would not be the programmer I am today. I learned much about the .NET framework and Visual Studio with VB.NET, knowledge that would be useful years later, as my more skilled self did more serious stuff in C#.
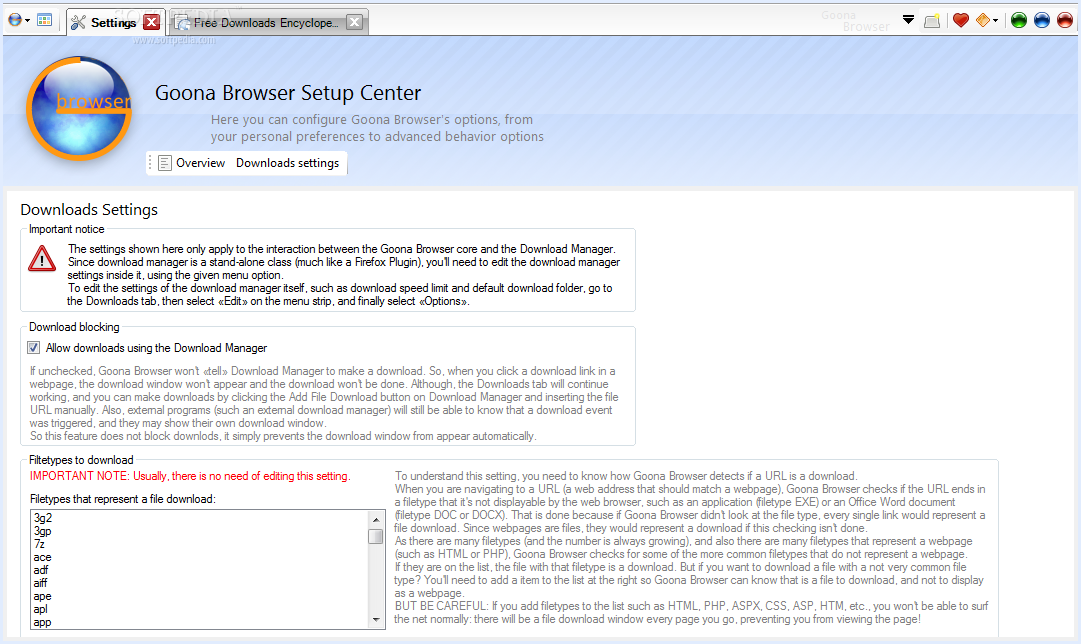
In VB.NET, I wrote many lines of mostly shoddy code. Much of that never saw the light of day, but there are some exceptions: multiple versions of Goona Browser made their way to the public. This was a dual-engine web browser with advanced UI, and futuristic concepts some major players copied, years later.
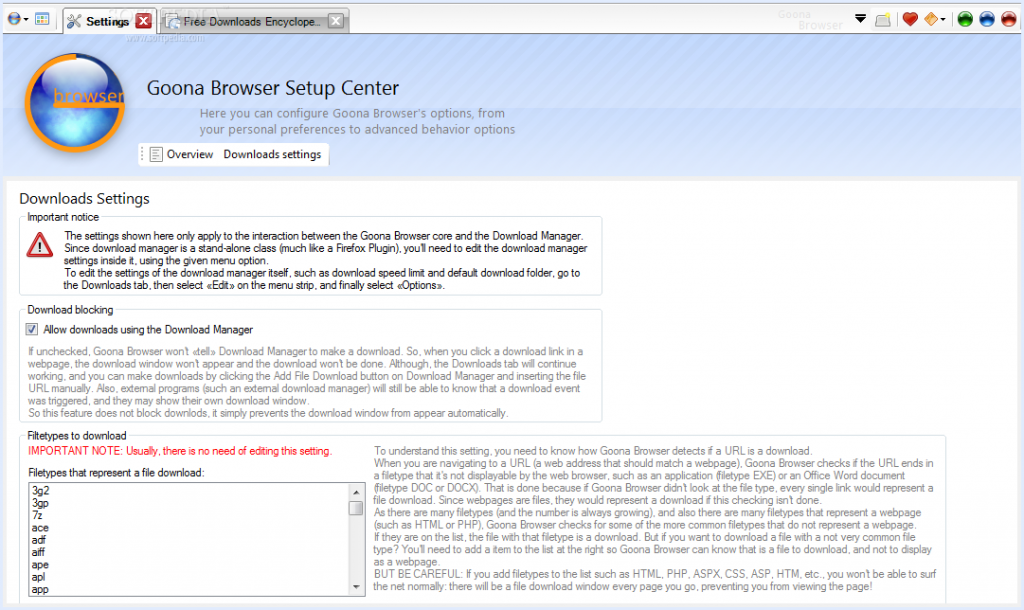
How things looked like, in good days (i.e. when it didn’t crash). Note the giant walls of broken English. I felt like “explain ALL the things”! And in case you noticed the watermark: yes, it was actually published to Softpedia.
If you search for it now, you can still find it, along with its website which I made mostly from scratch. All of this accompanied by my hilariously broken English, making the trip to the past worth its weight in laughs. Obviously I do not recommend installing the extremely buggy software, which, I found out recently, crashes on every launch but the first one.
Towards the later part of my VB.NET era, I also played a bit with C#. I had convinced myself I wanted to write an operating system, and at the time there was a project called COSMOS that allowed for writing (pretty limited) OS with C#… of course my “operating” systems were not much beyond a fancy command line prompt and help command. All of that is, too, stored in optical media, somewhere… and perhaps in the disk of said dual-core computer. I also studied and modified open source programs made in C# (such as the file downloader described in the Goona Browser screenshot) for my own amusement.
All this happened while I developed some static websites using Visual Web Developer Express as editor. You definitely don’t want to see those (mostly never published) websites, but they were detrimental to learning a fair bit of HTML and CSS. Before Web Developer I had also experimented with Dreamweaver 8 (yes, it was already old back then) and tried my hand at animation with Flash 8 (actually I had much more fun using it to disassemble existing SWFs).
Penguin programmer
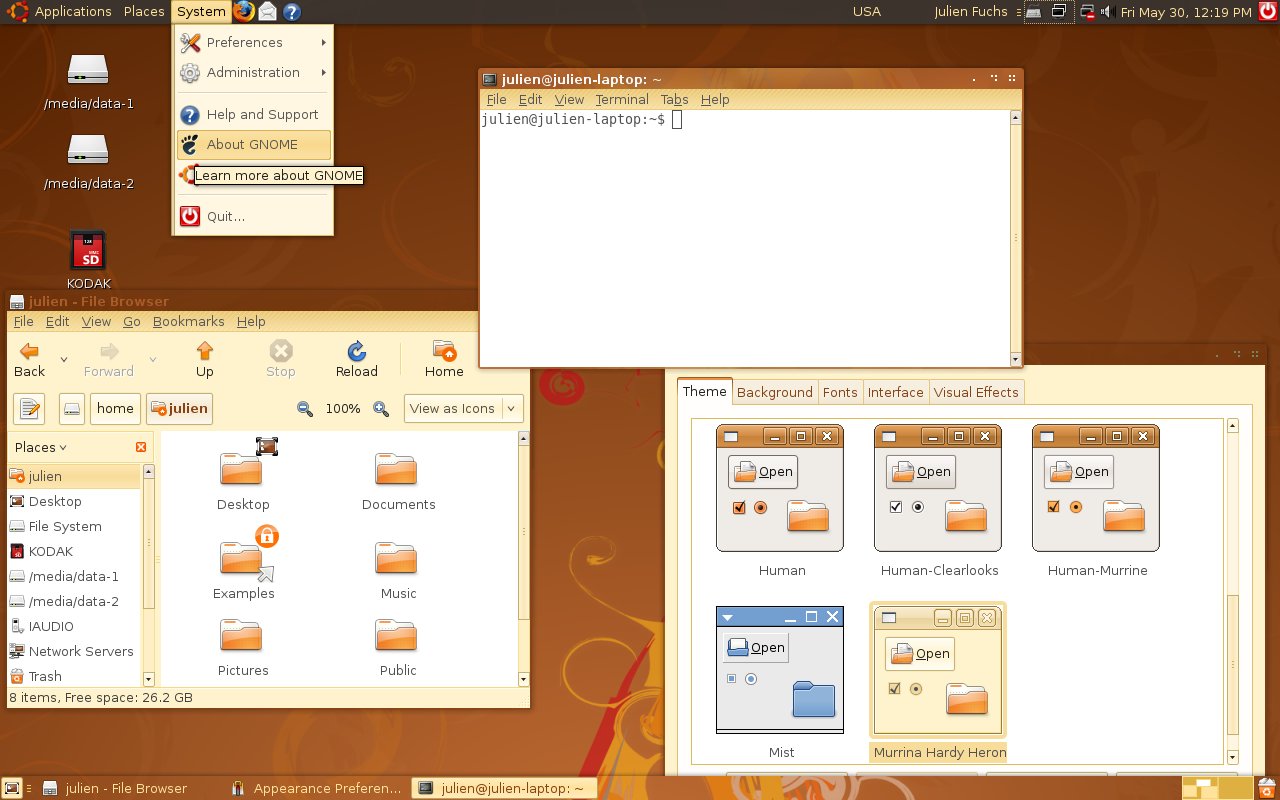
At this point I was 13 or so, had my first contact with Linux more than done, through VMs and Live CDs, aaand it happened: Ubuntu became my main OS. Microsoft “jail” no more (if only I knew what a real jailed platform was at the time…). No more clunky .NET! I was fed up with the high RAM usage of Goona Browser, and bugs I was having a hard time debugging, due to the general code clumsiness.
How Ubuntu looked like when I first tried it. Good times. Canonical, what did you do?
For a couple of years, in terms of desktop development, I only made some Python scripts for my own amusement and played a very small bit with MonoDevelop every time I missed .NET. I also made a couple Lua scripts for Rockbox. I learned much about Linux usage and system maintenance as I used it more and more on my own computers and on my first Virtual Private Servers, which I got after much drama in the free web hosting communities. Ugh, how I hate CPanel.
It was around this time that g.ro.lt and n.irc.su appeared. g.ro.lt was a URL shortener that would later evolve into 4.l.to and later tny.im. n.irc.su was a social network built on Elgg, which obviously failed. I also made some smaller websites, like one that would take you to random image hosting websites, URL shorteners and pastebins, so you would not use the same service every time you urgently needed one. These represented my first experiences with PHP programming.
I have no pictures to show. The websites are long gone, not on the Internet Archive, and if I took screenshots, I have no idea where I put them. Ditto for the logos. I believe I still have the source code for the random-web-service website somewhere, at least the front page layout.
All this working on top of free stuff: free (and crappy) subdomains, free (and crappy) web hosting, free (and less crappy) virtual servers. It would take me some time until I finally convinced myself I needed to spend some money for better reliability, a gist of support and less community drama. And even then I would spend Bitcoin, which I earned back when it was really cheap, making the rounds of silly faucets and pulling money out of CPAlead-like offers through the use of multiple proxies (oh, the joy of having multiple VPS…). To this day I still don’t have a PayPal account.
This time, and when I actively developed tny.im (as opposed to just helping maintain it), was the peak of my gbl08ma-as-web-developer phase. As I entered and went through high school, I would get more and more away from HTML and friends (but not server maintenance), to embrace something completely different…
Low level, little resources: embedded systems
For high school math everyone had to use a graphing calculator. My math teacher recommended (out of any interest) Casio calculators because of their ease of use (and even excitedly mentioned, Casio leaflet in hand, the existence of a new and awesome color screen model that “did everything and some more”). And some days later I had said model in my hands, a Casio fx-CG 20, or Prizm, which had been released about a year before. The price difference from the earlier dot-matrix screen Casio calcs was too small to let the color screen go.
I was turning 15, or had just turned 15. I remember setting up the calculator and thinking, not much after, “I want to code for this thing”. Casio’s built-in Basic dialect is way too limited (and after having coded in “real” languages, Basic was silly). This was in September 2011; in March next year I would be releasing my first Prizm add-in, CGlock, a calculator PIN-locking software.


Minimalist look, yay! So much you don’t even notice it’s a color screen.
This was my first experience with C; I remember struggling with pointers, and getting lots of compilation warnings and errors, and run-time errors. Then at some point everything just “clicked in” and C soon became my main language. Alas, for developing native software for the Prizm, this is the only option (besides using C++ without most of its features, not even the “new” keyword).
The Prizm is a horrible platform, especially for newbie C programmers. You can’t use a debugger, nor look at memory contents, the OS malloc/free implementation has bugs (and the heap is incredibly small, compared to the stack) and there’s always that small chance some program damages your calculator, or at least corrupts your estimated files and notes. To this day, using valgrind and gdb on the desktop feels to me as science fiction made true. The use of alloca (stack allocation) ends up being preferred in relation to dynamic allocation, leading to awkward design decisions.

Example of all the information you can get about an error in a Prizm add-in. It’s up to you to go through your binary (and in some cases, disassemble the OS) to find out what these mean. Oh, the bug only manifests itself when compiling with optimizations and without symbols? Good luck…
There is a proprietary emulator, but it wasn’t designed for software development and can’t emulate certain things. At least it’s better than risking damage to expensive hardware. The SuperH-4 CPU runs at 58 MHz and add-ins have access to about 600 KiB of memory, which is definitely better than with classic z80-powered Texas Instruments calculators, but one still can’t afford memory- or CPU-intensive stuff. But what you gain in performance and screen resolution, you lose in control over the hardware and the OS, which still have lots of unknowns.
Programming for the Prizm taught me how it’s like to work without the help of the C standard libraries (or better, with the help of incomplete and buggy standard libraries), what a stack overflow looks like (when there’s no stack protection), how flash memories work, what DMA is, what MMUs do and how systems can be bricked when their only bootloader is not read-only. It taught me how compilers work from an end-user perspective, what kind of problems and advantages optimizations introduce, and what it’s like to develop parts of the C standard library.
It also taught me Casio support in Portugal (Ename) is pretty incompetent at fixing calculators, turning my CG 20 into a CG 10 and leaving two big capacitors out of a replacement main board. In this hardware topic, I learned quite a bit about digital logic from Prizm hardware discussions at Cemetech. And I had some contact with SH4 assembly and a glimpse into how to use IDA Pro. Thank you Casio for developing a system that works so well and yet is so broken in so many under-the-hood ways, and thank you Cemetech for briefly holding the Prizm higher than TI calcs.
I developed other add-ins, some from scratch and others as ports of existing PC software (such as Eigenmath). I still develop for the Prizm from time to time, but I have less and less motivation as the homebrew community has stagnated and I use my Prizm much less, as I went to university. Experience in obscure calculator platforms does not make for a nice CV.
Yes, in three years or so I went from the likes of Visual Studio to a platform where the only way to debug is to write text to the screen. I still like embedded and real-time programming a lot and have moved to programming more generic and well-known things such as the ESP8266.
Getting in the elevator
During the later part of high school (which I started in the fall of 2011 and ended in the summer of 2014), I did more serious Python stuff, namely Mersit, later deprecated in favor of Picored, which is not written in Python but in Go. Yes, I began trying higher-level stuff again (higher level, getting in the elevator… sorry, I’m bad at jokes).
My first contact with Go was when I was 17, because I wanted to develop something that ran without external dependencies (i.e., unlike Java or .NET) and compiled to native code. I wanted to avoid C/C++, but I wasn’t looking for “a better C” either, so Rust was not it. Seeing so much stuff about Go at Hacker News, one day I decided to try my hand at it and I like it quite a lot – I’m still unsure if I like it because of the language itself or because of the great libraries one can use with it, but I think both play an important role.


This summer I decided to give C# another chance and I’m quite impressed – turns out I like it much more than I thought. It may have something to do with trying it after learning proper languages vs. trying it when one only knows VB. I guess my VB.NET scars are healed. I also tried a bit of Java, in my first contact with it ever, and it seems my .NET hate converted into Android API hate.
Programming with grades
University gave the opportunity (or better, the obligation) of having other people criticize my code. The general public could already see the open-source C code of my Casio Prizm add-ins, and even the ugly code of Goona Browser, but this time my code was getting graded. It went better than I initially thought – I guess the years of experience programming in different languages helped, especially as many of the people I’m being compared with have only started programming this year.
In the first semester we took an introductory programming course, which used Python, and while it was quite easy for me, I took the opportunity to learn Python to a greater depth than “language in which to write quick and dirty glue code”. You see, until then I had not used classes in my Python code, for example. (This only goes to show Python is a versatile language, even if slow.)
We also took an introductory computer architecture course where we learned how basic CPUs work (it was good for gluing all the separate knowledge I already had about it) and programmed in assembly for a course-specifc CISC-like architecture. My previous experience with reading SH4 assembly proved quite useful (and it seems that nowadays the line between RISC and CISC is more blurred than ever).
In the second semester, I had the opportunity to exercise my C knowledge, this time not limited to the Prizm platform. More interestingly, logic programming, a paradigm I had no intention of ever programming in, was presented to us. So Prolog it was. It went much better than I anticipated, but as most other people who (are forced to) learn it, I have no real use for it. So the knowledge is there, waiting for The Right Problems(tm). I am afraid I’ll forget much of it before it becomes useful, but if there’s something picking C# up again taught me, is that I can pick up pretty fast skills learned and abandoned long ago.
The second year is about to begin and there’s some object-oriented programming coming, I hope I do well.
Summing it up
I have written non-trivial amounts of code in at least 8 languages: Visual Basic, PHP, C#, Python, Lua, C, Go, Java and Prolog. I have contacted with two assembly dialects and designed web pages with HTML, CSS and Javascript, and of course automated some tasks with bash or plain shell scripting. As can be seen, I’m yet to do any kind of functional programming.
I do not like “years of experience” as a way to measure language proficiency, especially when such languages are learned for use in short-lived side projects, so here’s a list with an approximate number of lines of code I have written in each language.
- C: anywhere between 40K lines and 50K lines. Call it three years experience if you will. Most of these were for Prizm add-ins, and have since been rewritten or heavily optimized. This is changing as I develop less and less for the Prizm.
- PHP: over 15K lines, two years if you want to think that way. The biggest chunk of these were for developing the additions to YOURLS used in tny.im, but every other small project takes its own 200-500 lines of code. Unfortunately, most of this is “bad” code, far from idiomatic. The usual PHP mess, you know.
- Python: at least 5K lines over what amounts to about six months. Of these, most of the “clean” lines (25-35%) were for university projects.
- Go: around 7K lines, six months. Not exactly idiomatic code, but it’s clean and works well.
- VBA: uh, perhaps 3 or 4K lines, all bad code 🙂
- VB.NET: 10K lines or so, most of it shoddy code with lots of Try…Catch to “fix” the problems. Call it two years experience.
- C#: 10K lines of mostly clean and documented code. One month or so 🙂
- Lua: mostly small glue scripts for my own amusement, plus some more lines for use in games such as Minetest, I estimate 3-4 K lines of varying quality.
- Java: I just started, and mostly ported C# code… uh, one week and 1.5K lines?
- HTML, CSS and JS: my experience with JS doesn’t go much beyond what’s needed to modify DOM elements and make simple AJAX requests. I’ve made the frontend for over 5 websites, using the Bootstrap and INK frameworks.
- Prolog: a single university assignment, ~250 lines or one month. A++ impression, would repeat – I just don’t see what for.
In addition to all this, I have some experience launching the programs and services I make – designing logos/branding, versioning, keeping changelogs, update instructions, publishing, advertising, user support. Note that I didn’t say I’m good at any of these things, only that I have experience doing them, for better or worse…
Things I’d like to have more experience with:
- Continuous integration / testing in general;
- Debugging code outside of .NET/Visual Studio and printing debug lines in C;
- Using Git and other VCS in big repos/repos with more people (I want to see those merge conflicts and commits to the wrong branch coming);
- Server-side web development on something other than PHP and Go. And learning to use MVC frameworks, independently of the language;
- C++ (and Java, out of necessity. Damned Android);
- Game development. Actually, this is how many people start, but I’m so cool that I started by developing POS software 🙂
September 29, 2014 / gbl08ma / 1 Comment
My previous post on this blog was published by the end of the long-gone month of June. Many things have changed since then, for example, I entered university and was pressed into creating a Facebook account (more or less separate from the rest of my online presence, so don’t look for me, I won’t add you). On that post, I rambled about the recovery from a big server outage that costed 42 hours of tny.im downtime, and over one week of server downtime. I learned my lessons (I doubt BlueVM learned theirs, but that’s a whole other story), and I went forward with what I said I would do: “setting up a new advanced and redundant system” for ensuring tny.im is always up.
That system has been up and running for over two months now, with varying amounts of servers making the redundancy and load balancing, and a plethora of occasional hiccups. Right now it’s composed of three virtual servers (all from different providers…), but there were times when it was composed of five servers. These three servers are paid, and while they aren’t exactly expensive (but not the cheapest, either), you can imagine the bill, so let’s not talk about tny.im profitability now, OK? (I have kind of given up).
In the spirit of the great statisticians of our time, here’s a graph without title, labels or axis.
However, having three servers serving the same website, with all three of them being almost a clone of each other (which means, all have the same files and database contents, synced), in a DNS round-robin setup doesn’t directly lead to greater uptime. In fact, I have found out it can lead to more outages, since now the total downtime is approximately the sum of the downtime of each server. Of course, most of these outages are partial (as in, only users unlucky enough to have their DNS request resolved to the IP of a server that is down, will actually perceive the site as down), except for when the MariaDB replication freaks out and basically grinds all database operations, on all servers, to a halt, requiring a complicated manual restart of all MariaDB instances, in a specific order (yes, I have spent many hours searching for an alternative database system, and couldn’t find any that met my requirements).
In order to actually achieve greater uptime, one must have a system that automatically manages the DNS records so that the domain(s) of the website in question never have any records pointing to servers that are down. In other words, the “sheep” must be “hidden from sight” as soon as they go “bad”, and should be put back “in stage” once they become “good”. Being DNS something that was definitely not made for real-time record edits, with many systems caching DNS request results well beyond the specified TTL, this system obviously doesn’t ensure that the “bad sheep” are not invisible to everyone watching the show. But if it manages to do it for even a small percentage of the public, it’s already better than not hiding from anyone (and especially, if it successfully hides the problem from the uptime monitor, that’s even better 🙂 ). This explains why the DNS records for tny.im are set with TTLs of five minutes.
The development of such a DNS record management system was also more or less contemplated in my previous post, when I say:
I’ll take this downtime and new server acquisition as the motivation for setting up a new advanced and redundant system, so that if one server goes down, tny.im (and possibly this blog too) will continue to operate as normal.
And in the end, in a later edit:
On related news, Mirasm – the Tiny Server Redundancy Manager – is mostly finished, only needs some more testing to be put on production servers, managing the new tny.im redundancy system.
“Mostly finished”, as we all know, really means “It’s 99% ready, I only need to figure out the remaining 1% that consists on… everything that is tricky and I’m not sure how it’s done”. This is specially true in this case, as I had high requirements for my manager: it couldn’t use any resources other than the servers I had already (it would’ve been easy to have a separate server just for monitoring and editing DNS as needed, but I didn’t want to pay for yet another server on yet another provider), and it couldn’t fail more than tny.im itself. In fact, the time when the manager has to do more important work, is when it is not working, i.e. when a server goes down and so goes the manager. I finally finished the project, and it works as planned. I only got the name wrong…
Introducing mersit, a Tiny Server Redundancy Manager
Pronounced “m-eh-rs-ee-t”, with the first “e” being like the one in “explain”, mersit is a simple Python script (Python 2.7, because I wasn’t sure what libraries were available for 3.x nor if my servers would run it well) hacked together with some sections that definitely look like spaghetti code. The good news is, it works fine, and has been well tested, so if you study it in the “black box” way, there are no big problems with it.
The purpose of the script is to manage the DNS records of the website served by the group of synced servers, in this case, tny.im. It runs on each server, in a peer-to-peer fashion. The peers select a single master, that will monitor all the peers and manage the DNS as they go up and down, “deciding who’s on stage”, and all peers will check whether the master is up, and select a new one that will edit the DNS to “hide the master from the public” when it goes down.
I definitely want to open-source mersit at some point, but not now because it’s not ready for prime-time (see “spaghetti code”, above), and I want to change some things that will make it more general-purpose. mersit has been managing the live records for tny.im for the past week (it’s been peaceful).

Continuing our journey through the world of meaningful graphs, here’s another.
I have gone so far as to write a read-me for mersit (mainly for me to read, as I know I’ll forget how it works within six months). I think it’s best if I put the start of the read-me here, instead of trying to explain it all, once again:
mersit - Tiny Redundant Server Manager
Copyright 2014 tny. internet media
This version is customized for tny.im
This is a Python 2 script that manages a group of computers/servers/thin clients/machines in a network (local- or wide-area), by automatically executing actions when something relevant happens to one of the machines.
We'll call the "machines" "peers". mersit assumes all peers and the network are trusted.
The script is meant to be run directly on the peers that are to be controlled, in a setup where there is not a single point of failure. It is not of much use when run in a single peer; in the context of this script, a "group" only starts to make sense when it has over one element.
We'll refer to this script as "controller software" or simply "controller", and to the other software that runs on a peer and which is to be monitored as "application". The controller is made to run unattended, even though it accepts commands (issued by an "operator") to trigger certain behavior manually.
The "something relevant" mentioned in the first paragraph consists on one of these "events of interest":
- A peer goes "online", that is, it is reachable by other peers and reports the status of its controller software as "OK" or "ready";
- A peer goes "offline", that is, it is either not reachable by at least some peers, or the controller is reporting its state as "not good" or "not ready";
- A peer becomes good-for-work (GFW), which means, that the application is functioning properly and performing its function (such as listening for incoming connections, data to process, etc.);
- A peer becomes not-good-for-work (NFW), in which case the application is not functioning properly, is too busy to perform its function (over capacity), or is otherwise unavailable.
Each peer works in a given "domain", which is the group the peer belongs to. The domain is specified by a name and secret which act basically like a username and password pair. Peers will only communicate with other peers of the same domain, that is, peers where the domain name and secret are the ones the controller is configured to use. The domain acts as the authentication element; an external party can not join, communicate or perform actions in a domain unless it knows the name and password used by the peers of the domain.
(Please note, that communication between peers is not encrypted by the controller - it goes completely plain-text over the network. It is possible to secure the communication between peers using external tools; such secure functionality goes beyond the scope of this software. The "domain" is simply a basic authentication system, implemented using HTTP authentication, to ensure that peers of a certain group don't start talking with peers from other groups. The basic authentication system is enough to protect against the casual script-kiddie, but by no means adequate for protection from a malicious party in an untrusted/open network)
The controller on each peer must know _a priori_ (i.e. before it starts) about where to find at least some of the controllers on other peers. Peer discovery doesn't happen automatically, however, once a peer's controller can communicate with another controller, it will add every controller in the "contact list" of the latter to its "contact list".
Imagine the following situation: you have peers A, B and C (and their controller software). The controller in A only knows about peer B. The controller in B only knows about peer C. If you start the controller on peer A, then start the controller on peer B, peer A will tell peer B about its existence, and peer B will tell peer A about the existence of a peer C (independently of peer C being running/reachable). However, if the controller in A knew about no peer (other than itself), it would never find peer B or C even if their domain settings all matched. Even though a big domain can be bootstrapped from just two peers, to ensure good operation, all controllers should know about all peers. This way, if the controller on a peer resets for some reason, it will have a greater chance of reaching another peer.
The "contact list" is the list of "known" peers. The controller keeps three lists of peers in memory: the "known" peers, the "reachable" peers, and the "GFW" (good-for-work) peers. The list of known peers is initialized from the source code's configuration section when the controller starts. It then proceeds to see which peers are "reachable", that is, can be reached through the network, are in the same domain (not being in the same domain gives the same effect as not being reachable over the network) and have their controller software report its state as "OK".
This initial status checking includes the exchange of some other information about the controller. Once this initial peer identification is done, the controller enters a monitoring loop where it will keep the contents of the three lists up-to-date. The controller keeps running this infinite loop throughout most of its lifetime. How the lists are kept up-to-date and what happens when their contents change is something that depends on the current controller mode.
There are two possible modes for controller operation: master and non-master. There is exactly one controller in master mode per domain, and this controller is usually called "the master" (the master peer has the controller in master mode). The differences between the modes are mostly related to what happens in the monitoring loop, but before going into those differences, it is important to understand how the controllers decide which peer is the master peer.
When a controller starts and there are no reachable peers, it promotes itself to master, since there must be exactly one master per domain. Later, when another controller joins the domain (either because it started or because it went online after e.g. a period without connections or power), it checks which peers are reachable from its "known" list and "asks" them which is the master peer. Every peer should reply with the same peer, in which case the new controller assumes that peer is the master, and informs the master about its existence, to account for the fact that the new peer may not be in the master's "known" list.
However, and especially on domains where not all peers initially know about every other peer, it's possible that a "head split" occurs and there are two masters in the same domain. Imagine a domain where there are four peers D, E, F and G. D only knows about E, which in turn only knows about D. F doesn't know about any peer, and we'll leave G aside for now. All peers are offline.
The D controller starts up, sees it can't reach the only peer it knows (E), so calls itself master. The E controller starts up and reaches D, D says it is the master, E assumes D is master, all is fine.
The F controller starts up, sees it can't reach any peer because its "known" list is empty, so calls itself master and sits quietly waiting for someone to contact it, which in turn would let it know about more peers.
We now have the following situation ([M] represents a controller in master mode, --- represents the knowledge peers have of each other):
-DOMAIN------------------
| |
| D[M]-----E F[M] |
| |
-------------------------
Things could be like this forever, and no conflicts would occur - however, this is probably not a domain you want to have, since F doesn't know about any "event of interest" related to D or E, and these two don't know about any events related to F. In this situation, D--E and F act like separate domains.
Assume that G is a peer which knows about D, E and F, and that its controller starts up, contacting D, E and F. The first two will agree that D is the current master, but F will disagree and say it is the master. At this point we have a conflict. There are many ways to solve this, including some form of "voting" (e.g. the peer the largest amount of the peers say is the master effectively becomes it), but mersit solves this in a simpler way.
The controller checks that everyone in the domain agrees on what peer is the master on every iteration of the monitoring loop. It does this by "asking" each peer in the list of known peers who is the master. The first peer asked is free to reply with any peer. The ones that are asked next must agree with the first one. If not, the controller that was doing the loop tells each disagreeing peer that the actual master, is the one from the first peer's reply. It is possible that a minority is asked first, and thus everyone is forced to "change its opinion" to that of the minority. This is not a problem - mersit assumes all peers are trusted. Note that it can sometimes take some iterations of the monitoring loop for all peers to settle on a single master, because two (or more) peers may be trying to "change the opinion" of the other peers to different masters. This is not a problem either, because even if this kind of concurrency conflict happens once or twice in a row, it will stop happening as soon as one peer is faster than the other to tell everyone (including the other peer(s) that are trying to "change opinions"). What matters is that in the end, every peer knows about all others, and there is a single master. In this case, it could be D:
-DOMAIN--------------------
| |
| D[M]-----E-----F-----G |
| |
---------------------------
If the master becomes unreachable, or its controller stops working, the other peers will also find themselves a new master, by sorting the list of reachable peers alphabetically and choosing the first peer in the sorted list. Of course, if for some reason the list is not consistent across peers, the peers will try to "convince" others to settle on who they "think" is the master as previously explained, until everyone is set to the same master.
Being the master essentially changes what happens in the monitoring loop. When a controller is in master mode, it is responsible for updating the list of "reachable" and "GFW" peers, by checking which peers are reachable (both in terms of network and in terms of functioning controller) and which have the application in a working condition. If there are changes in the lists that indicate an event of interest, it runs the appropriate handler. If, for example, a peer becomes NFW due to a problem in the application, it will stop being in the GFW list, and the handler function for when a peer leaves that list will be run with the peer in question as the argument. If the master becomes unreachable (network error, controller error, etc.), a new master will be found, as explained in the previous paragraph, and the new master is responsible for running the handler with the previous master as argument.
When a peer is not master, it won't run any handlers for events of interest, and it is not responsible for updating the "reachable" and "GFW" lists - it will retrieve these from the master. The controllers on all peers need to keep their lists up-to-date, sharing a "vision of the domain" similar to that of the master, so that any peer can become a master instantly in case of necessity, without having to spend time performing checks on all peers and ensuring it has the best-and-latest list of "known" peers.
The operator can manually tell a controller to become the domain's master. When the appropriate command is issued, the controller will send a command to every other controller instructing them to switch to the new master. This command may not always have an effect in some controllers, because while the first controller is sending the commands, other controllers are seeing if everyone agrees on who's the master, and issuing the same commands with another master in mind. This is a sequence of events picturing the situation, in a domain where there are three peers H, I and J, and H is the initial master:
0. ...
1. Peer H checks that every controller agrees it is the master (all agree);
2. Peer I checks that every controller agrees H is the master (all agree);
3. Peer J checks that every controller agrees H is the master (all agree);
4. Operator issues command for peer I to become master;
5. Controller on I assumes it is master, starts sending commands to other peers;
6. Peer H checks that every controller agrees it is the master, before the message from I that I is the new master can get to H;
7. Peer H finds out I (and possibly others) don't agree, sends them commands to change the master back to H;
8. Peer I changes master back to H;
9. Peer I checks that every controller agrees H is the master (all agree);
10. Peer J checks that every controller agrees H is the master (all agree);
11. ...
If the master doesn't change when the manual command is issued, it's a matter of trying again. Most often, this kind of concurrency problem does not occur, and even when it does, it does no damage. While it is true that mersit could detect this situation and keep issuing commands automatically until the decision takes effect, we chose to not make it this way to allow the human operator finer control.
The primary focus of mersit is to monitor a distributed application. The master checks if the application, or part of the application, running on a certain peer is in working condition by asking that peer's controller about the state of the application it is monitoring. In turn, this controller runs a function, defined by the mersit user in the mersit source code, that should check the application and return True (if application OK) or False (if not). This can involve, for example, making a HTTP request to a HTTP server in that peer to verify it is working. The controller then communicates the status of the application to the master (which may be itself). All this shouldn't take too long, especially when the domain has many servers, as only one peer is asked at a time. If checking the status of the application typically takes over one second, it is best to store the last known status in a variable, and update that state periodically in an asynchronous manner that may be external to the mersit script.
The part related to DNS records is not explained on the read-me, because it is related to the handlers (which each mersit user would customize to the specific needs of the system – as I said, I tried to make it a general-purpose script). Sounds interesting? Feel free to ask questions, or point out problems, in the comments.
June 30, 2014 / gbl08ma / 1 Comment
tny.im and this website were down for about 42 hours, starting on June 29 at 03:16 UTC.
The problem? BlueVM’s S19-NY server went down, taking with it the server I have/had there (and which I paid for a full year!). Other than this outage, the service had worked fine for three months, – fast network, full resources availability – since I bought it.
S19-NY is still down, without any ETA for it to come back. There’s no information in what conditions it will come back, or *if* it will come back (with the previous contents, at least). BlueVM staff is pretty much unresponsive, other than a guy who sometimes hangs on IRC and says he can’t fix the KVM instance because he doesn’t have access to it.
Of course, I no longer recommend BlueVM and I don’t plan on renewing the server I have with them.
The “solution” to put an end to two days of downtime, was to buy the cheapest SecureDragon OpenVZ server, (OpenVZ! so hard to live without my beloved KVM, I can’t even use davfs2 because there’s no fuse module!) and restore the backups I had (from four hours before the BlueVM instance went down). This has been done, except for the HTTPS certificate of tny.im… that alone is another story:
As I tried to retrieve the existing cert from StartSSL (because, stupid me, automated backups were not copying everything SSL-related, and I didn’t save it locally), I found my authentication certificate had expired. This basically means my StartSSL account is lost, unless I create a new account and ask their staff to link it to the old one. They probably won’t do that without a payment and some ID checks so… out of question. I guess, if the BlueVM server doesn’t come back, that I’ll just create a new StartSSL account and generate a new cert for tny.im. There’s no security issue with this, as the previous certificate has not been compromised (unless BlueVM is collecting certificate private keys from inside their clients’ machines…) and so it doesn’t need to be revoked.
To conclude the HTTPS point: tny.im has the HTTPS service unavailable for now, until I can retrieve the existing certificate from the previous server, or until I get a new one.
Is all the fault in BlueVM’s side? Of course not… I could have lost my love for the money earlier, bought the SecureDragon VPS yesterday already and reduce the downtime by 24 hours. But since I had hope the problems on BlueVM support were just Sunday-related, I thought that by Monday they would have it fixed. They didn’t.
On related news, I’ll take this downtime and new server acquisition as the motivation for setting up a new advanced and redundant system, so that if one server goes down, tny.im (and possibly this blog too) will continue to operate as normal. I have two servers already (assuming the BlueVM one comes up), and I plan on developing a system where firing up new instances of tny.im on any empty server will be really easy. The system will be always prepared to lose any server at any point, without data loss, and restore full service within five minutes. That way, I can add less reliable hosts, perhaps even VPS trials, to the redundant system. This also allows for scaling the service as needed. Sounds ambitious? Of course it won’t happen in a week, but I have the full summer to develop and test the system…
Why don’t I just go with some SaaS that supports scaling? Two reasons: the price is too high, and the tny.im software is not coded in a way that’s compatible with these services. Let me remember you, that while not exactly being a CGI script, tny.im is not coded in one of those fancy modern languages, and even though PHP is not exactly outdated or unmaintained, the quality of the code can make it pretty horrible or pretty good. And the code is… not perfect – it doesn’t use any popular framework, it is based on YOURLS and has many, many hacks feature additions, plus a… very close relationship with the database.
Let me finish by saying that downtime of this kind is something to be expected if I were still hosted by FreeVPS and the like. But believe it or not, on FreeVPS and other sponsorships I’ve never seen a customer service as bad as the one of BlueVM (and it’s hard to remember an outage as big as this one). It is definitely not adequate for a paid service. In addition to S19-NY, they have many other instances down, with similar or worse downtime. The admins don’t appear to be online or reachable in any way, even by other staff members. The latest news/excuse on the S19-NY situation is that IPMI is broken and they are waiting for the provider to fix it… now tell me, does this look like a serious company, or some poor-man’s sponsorship?
EDIT: The BlueVM server is still down. tny.im is now hosted by three servers with round-robin balancing. HTTPS service was restored with a new certificate.
EDIT 7/7/2014: I forgot to update this post in time, but the BlueVM server has been up since three days ago. But I only got to know that the service was restored thanks to a friend of mine, because they didn’t reply to my ticket to inform me about it. Anyway, I don’t plan to renew this server, and BlueVM lost me as a customer (except for some really cheap deal which I’ll use as a personal/development box, and never in production).
On related news, Mirasm – the Tiny Server Redundancy Manager – is mostly finished, only needs some more testing to be put on production servers, managing the new tny.im redundancy system.
April 12, 2014 / gbl08ma / 4 Comments
Just in case you didn’t know/notice, this website and tny.im are no longer hosted on a VPS provided by FreeVPS. Due to issues on the node where that VPS was hosted, that made it become network-unreachable, I needed to buy a new server to avoid a longer downtime.
I ended up buying a KVM-powered VPS from BlueVM because they accept Bitcoin and had a good special deal at the time. It’s my third day with the server and so far, so good. It has better specs than the server I had, and after config optimization tny.im is now able to handle more concurrent requests than it did before. I will keep readers updated and post a detailed review of the server, later.
Moving away from sponsorships is be better in the long term (less worries, proper support…), even if it means that tny.im is now unprofitable (temporarily, hopefully).
August 22, 2013 / gbl08ma / 0 Comments
If I tried to crowdfund the renewal of my domain names or server hosting, I wonder how well that would work…