September 27, 2016 / gbl08ma / 0 Comments
I say you should stop trusting them in your systems ASAP. I’m just going to leave this here:
WoSign and StartCom: Mozilla’s proposed conclusion
I’m really glad all of my websites now use Let’s Encrypt. At the same time, I think this means that Let’s Encrypt now is a “monopoly” on the free certificates market – which, all things taken into account, is probably a good thing, as they seem to be way superior to the alternatives both in technical and ethical terms. My only problem with this is the “centralization” that arises: no matter how well Let’s Encrypt is managed, all it will take is the compromise of that single CA to cause major havoc.
June 28, 2016 / gbl08ma / 0 Comments
Because, why not? Let’s Encrypt makes it so easy…
Let’s Encrypt certificates are now used on all the websites maintained by Segvault, but not all of the websites of the TNY Network – the CPUVInf website, for example, seems to be using CloudFlare-provided TLS.
August 23, 2015 / gbl08ma / 1 Comment
Go to the bottom, “Summing it up”, for the TL;DR.
The day I turn this website into a portfolio/CV-like thing will come sooner or later, and arguably that’s a better use for the domain gbl08ma.com than this blog with posts nobody cares about – except when I rant about new operating systems from Microsoft. But if you really care about such posts, do not worry: the blog will still exist, it just won’t be as prominent.
Meanwhile, and off-topic intro aside, the content usually seen on such presentation websites everyone-and-their-cat seems to have these days, will have to wait. In anticipation for that kind of stuff, let’s go in a kind of depressing journey through my eight years programming experience.
The start
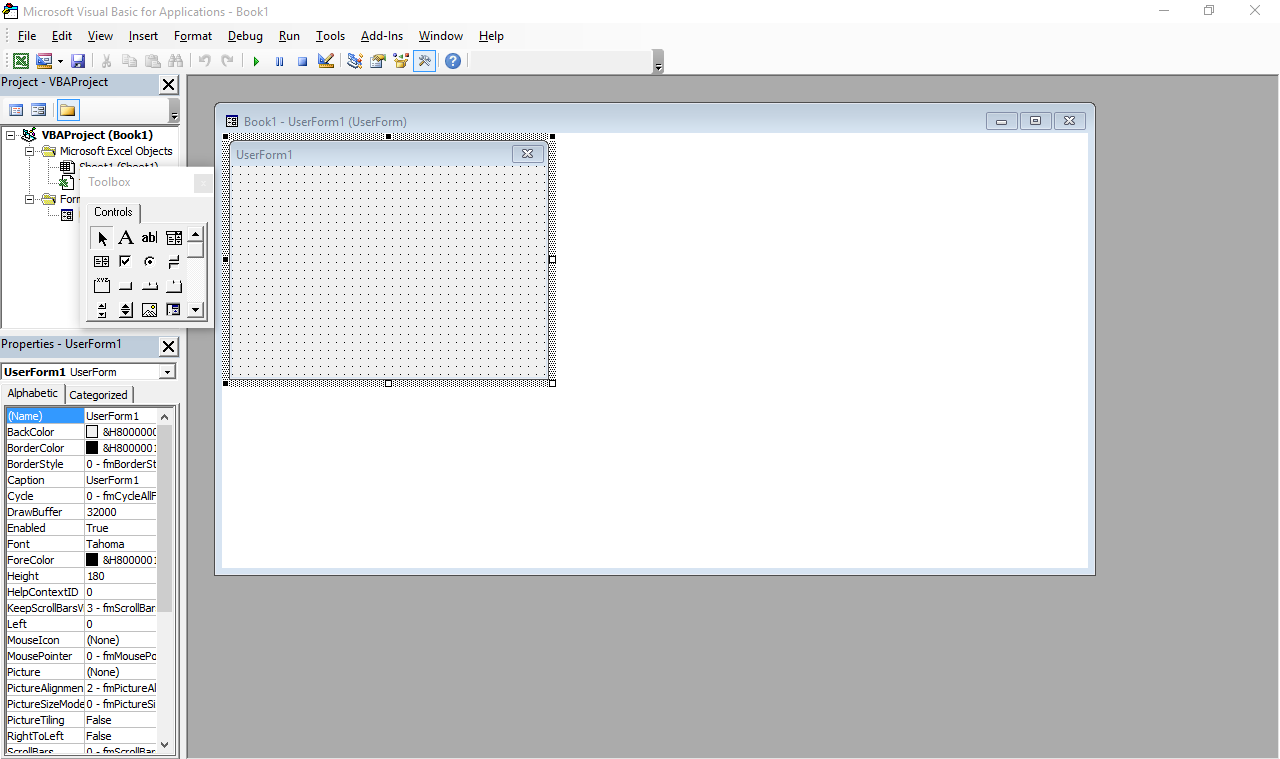
The beginning was what many people would consider a horror movie: programming in Visual Basic for Applications in Excel spreadsheets, or VBA for short. This is (or was, at the time; I have no idea how it is now) more or less a stripped down version of VB 6 that runs inside Microsoft Office and does not produce stand-alone executables. Everything lives inside Office documents.
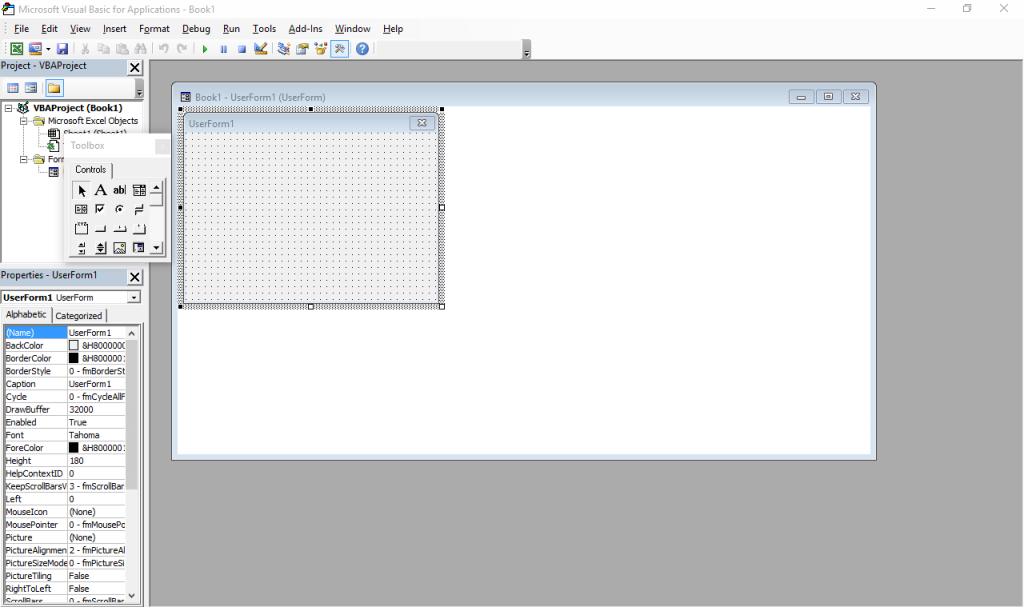
It still exists – just press Alt+F11 in any Office window. Also, the designer has Windows 7 Basic window styles… on Windows 10, which supposedly ditched all that?
I was introduced to it by my father, who knows his way around Excel pretty well (much better than I will probably ever will, especially as I have little interest). My temporal memory is quite fuzzy and I don’t have file timestamps with me for checking, so I was either 9, 10 or 11 years old at the time, but I’m more inclined to think 9-10. I actually went quite far with it, developing a Excel-backed POS system with support for costumer- and operator-facing character LCD screens and, if I remember correctly, support for discounts and loyalty cards (or at least the beginnings of it).
Some of my favorite things I did with VBA, consisted in making it do things it was not really designed for, such as messing with random ActiveX controls and making it draw strange-looking windows (forms) and controls through convoluted Win32 API calls I’d have copied from some website. I did not have administrator rights to my computer at the time, so I couldn’t just install something better. And I doubt my Pentium III-powered computer, already ancient at the time (but which still works today), would keep up with a better IDE.
I shall try to read these backup CDs and DVDs one day, for a big trip down the memory lane.
Programming newb v2
When I was 11 or 12 I was given a new computer. Dual core Intel woo! This and 2GB RAM meant I could finally run virtual machines and so I was put on probation: I administered the virtual computers, and soon the real hardware followed (the fact that people were tired of answering Vista’s UAC prompts also helped, I think). My first encounter with Linux (and a bunch other more obscure OS I tried for fun) was around this time. (But it would take some years for me to stop using Windows primarily.)
Around this time, Microsoft released the Express (free) editions of VS 2008. I finally “upgraded” to VB.NET, woo! So many new things to learn! Much of my VBA code needed changes. VB.Net really is a better VB, and thank Microsoft for that, otherwise the VB trauma would be much worse and I would not be the programmer I am today. I learned much about the .NET framework and Visual Studio with VB.NET, knowledge that would be useful years later, as my more skilled self did more serious stuff in C#.
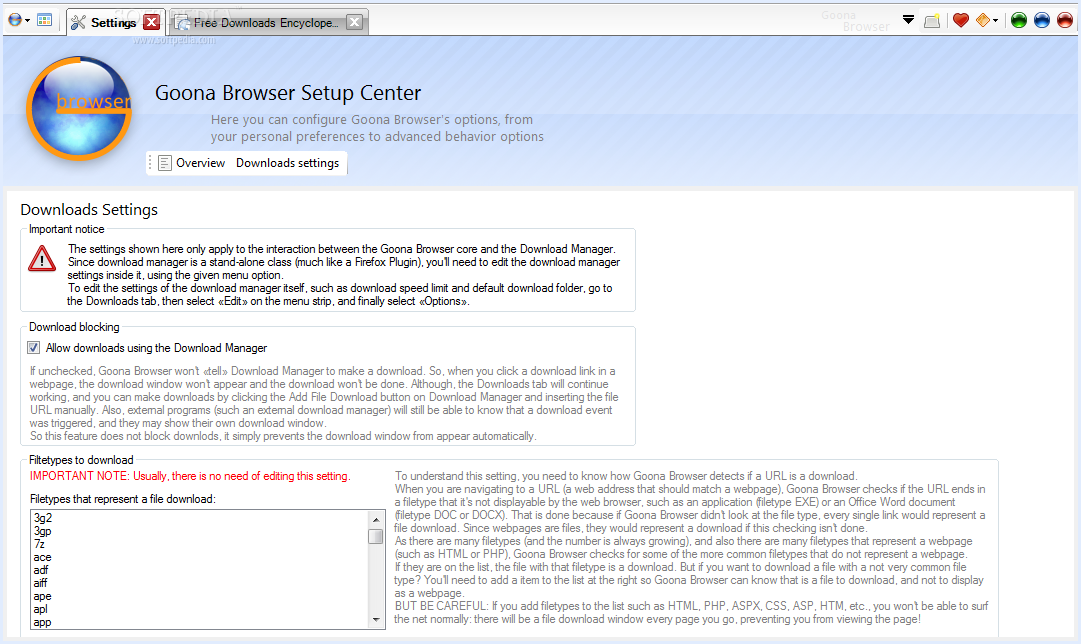
In VB.NET, I wrote many lines of mostly shoddy code. Much of that never saw the light of day, but there are some exceptions: multiple versions of Goona Browser made their way to the public. This was a dual-engine web browser with advanced UI, and futuristic concepts some major players copied, years later.
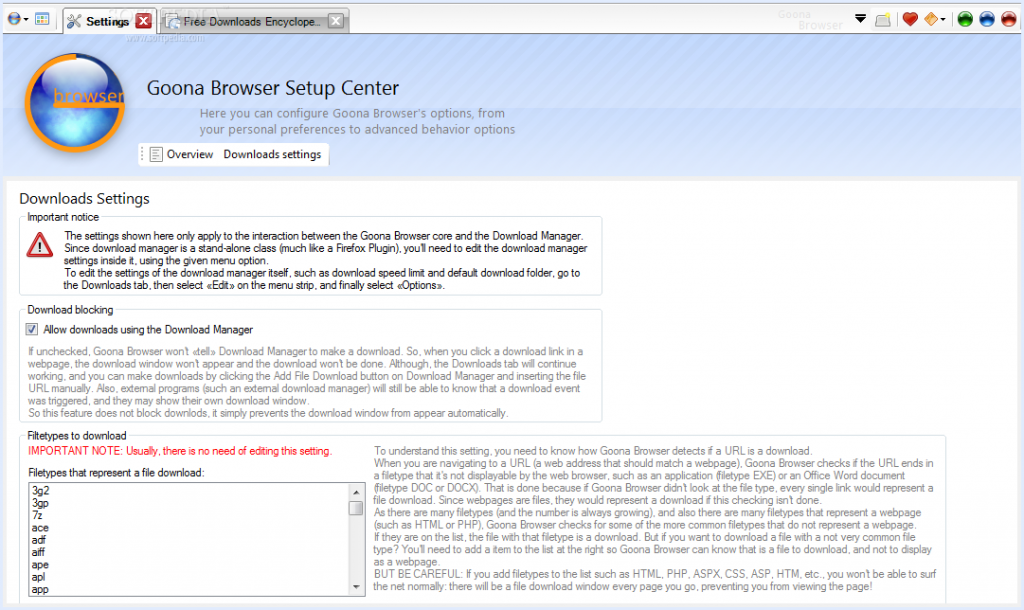
How things looked like, in good days (i.e. when it didn’t crash). Note the giant walls of broken English. I felt like “explain ALL the things”! And in case you noticed the watermark: yes, it was actually published to Softpedia.
If you search for it now, you can still find it, along with its website which I made mostly from scratch. All of this accompanied by my hilariously broken English, making the trip to the past worth its weight in laughs. Obviously I do not recommend installing the extremely buggy software, which, I found out recently, crashes on every launch but the first one.
Towards the later part of my VB.NET era, I also played a bit with C#. I had convinced myself I wanted to write an operating system, and at the time there was a project called COSMOS that allowed for writing (pretty limited) OS with C#… of course my “operating” systems were not much beyond a fancy command line prompt and help command. All of that is, too, stored in optical media, somewhere… and perhaps in the disk of said dual-core computer. I also studied and modified open source programs made in C# (such as the file downloader described in the Goona Browser screenshot) for my own amusement.
All this happened while I developed some static websites using Visual Web Developer Express as editor. You definitely don’t want to see those (mostly never published) websites, but they were detrimental to learning a fair bit of HTML and CSS. Before Web Developer I had also experimented with Dreamweaver 8 (yes, it was already old back then) and tried my hand at animation with Flash 8 (actually I had much more fun using it to disassemble existing SWFs).
Penguin programmer
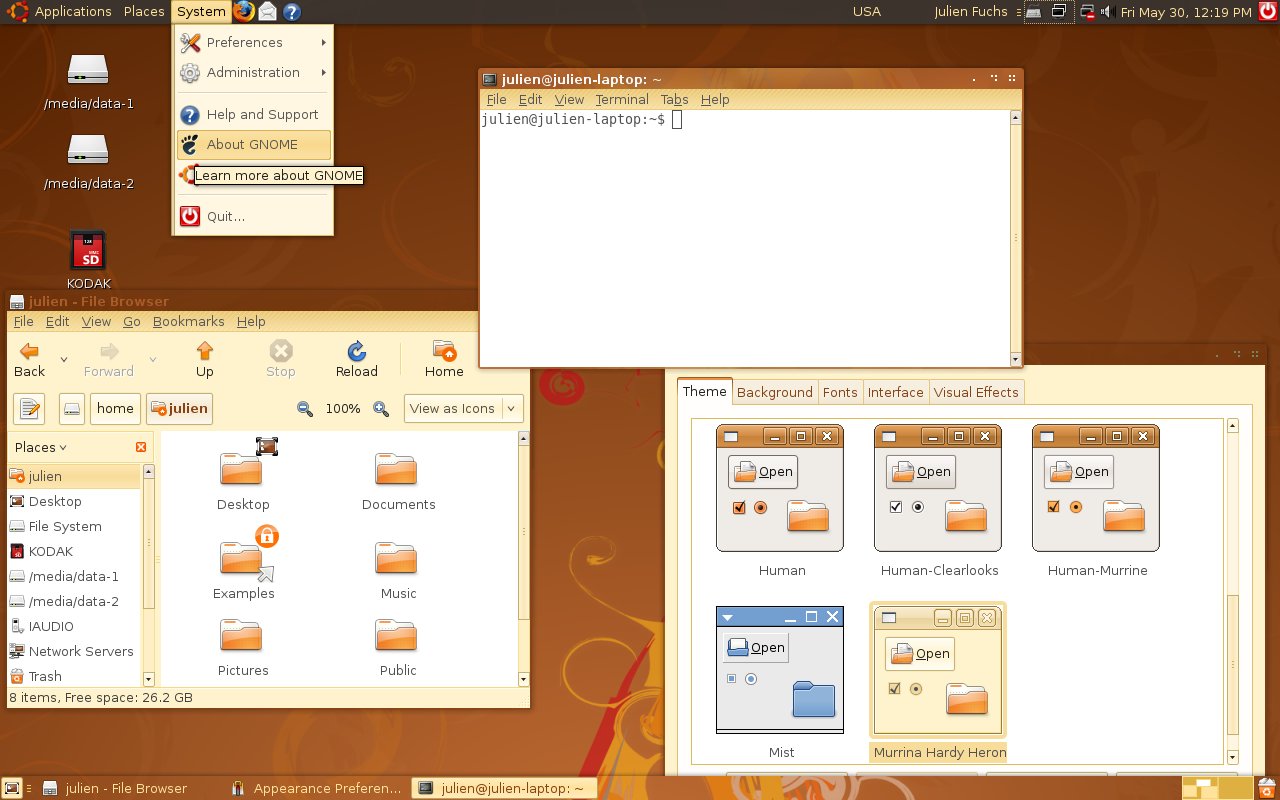
At this point I was 13 or so, had my first contact with Linux more than done, through VMs and Live CDs, aaand it happened: Ubuntu became my main OS. Microsoft “jail” no more (if only I knew what a real jailed platform was at the time…). No more clunky .NET! I was fed up with the high RAM usage of Goona Browser, and bugs I was having a hard time debugging, due to the general code clumsiness.
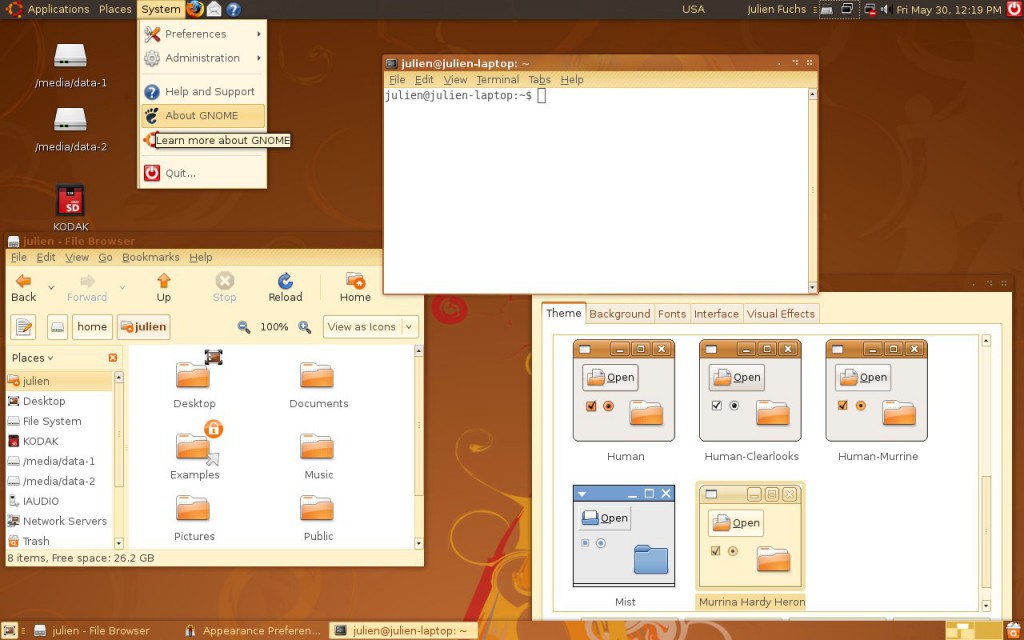
How Ubuntu looked like when I first tried it. Good times. Canonical, what did you do?
For a couple of years, in terms of desktop development, I only made some Python scripts for my own amusement and played a very small bit with MonoDevelop every time I missed .NET. I also made a couple Lua scripts for Rockbox. I learned much about Linux usage and system maintenance as I used it more and more on my own computers and on my first Virtual Private Servers, which I got after much drama in the free web hosting communities. Ugh, how I hate CPanel.
It was around this time that g.ro.lt and n.irc.su appeared. g.ro.lt was a URL shortener that would later evolve into 4.l.to and later tny.im. n.irc.su was a social network built on Elgg, which obviously failed. I also made some smaller websites, like one that would take you to random image hosting websites, URL shorteners and pastebins, so you would not use the same service every time you urgently needed one. These represented my first experiences with PHP programming.
I have no pictures to show. The websites are long gone, not on the Internet Archive, and if I took screenshots, I have no idea where I put them. Ditto for the logos. I believe I still have the source code for the random-web-service website somewhere, at least the front page layout.
All this working on top of free stuff: free (and crappy) subdomains, free (and crappy) web hosting, free (and less crappy) virtual servers. It would take me some time until I finally convinced myself I needed to spend some money for better reliability, a gist of support and less community drama. And even then I would spend Bitcoin, which I earned back when it was really cheap, making the rounds of silly faucets and pulling money out of CPAlead-like offers through the use of multiple proxies (oh, the joy of having multiple VPS…). To this day I still don’t have a PayPal account.
This time, and when I actively developed tny.im (as opposed to just helping maintain it), was the peak of my gbl08ma-as-web-developer phase. As I entered and went through high school, I would get more and more away from HTML and friends (but not server maintenance), to embrace something completely different…
Low level, little resources: embedded systems
For high school math everyone had to use a graphing calculator. My math teacher recommended (out of any interest) Casio calculators because of their ease of use (and even excitedly mentioned, Casio leaflet in hand, the existence of a new and awesome color screen model that “did everything and some more”). And some days later I had said model in my hands, a Casio fx-CG 20, or Prizm, which had been released about a year before. The price difference from the earlier dot-matrix screen Casio calcs was too small to let the color screen go.
I was turning 15, or had just turned 15. I remember setting up the calculator and thinking, not much after, “I want to code for this thing”. Casio’s built-in Basic dialect is way too limited (and after having coded in “real” languages, Basic was silly). This was in September 2011; in March next year I would be releasing my first Prizm add-in, CGlock, a calculator PIN-locking software.


Minimalist look, yay! So much you don’t even notice it’s a color screen.
This was my first experience with C; I remember struggling with pointers, and getting lots of compilation warnings and errors, and run-time errors. Then at some point everything just “clicked in” and C soon became my main language. Alas, for developing native software for the Prizm, this is the only option (besides using C++ without most of its features, not even the “new” keyword).
The Prizm is a horrible platform, especially for newbie C programmers. You can’t use a debugger, nor look at memory contents, the OS malloc/free implementation has bugs (and the heap is incredibly small, compared to the stack) and there’s always that small chance some program damages your calculator, or at least corrupts your estimated files and notes. To this day, using valgrind and gdb on the desktop feels to me as science fiction made true. The use of alloca (stack allocation) ends up being preferred in relation to dynamic allocation, leading to awkward design decisions.

Example of all the information you can get about an error in a Prizm add-in. It’s up to you to go through your binary (and in some cases, disassemble the OS) to find out what these mean. Oh, the bug only manifests itself when compiling with optimizations and without symbols? Good luck…
There is a proprietary emulator, but it wasn’t designed for software development and can’t emulate certain things. At least it’s better than risking damage to expensive hardware. The SuperH-4 CPU runs at 58 MHz and add-ins have access to about 600 KiB of memory, which is definitely better than with classic z80-powered Texas Instruments calculators, but one still can’t afford memory- or CPU-intensive stuff. But what you gain in performance and screen resolution, you lose in control over the hardware and the OS, which still have lots of unknowns.
Programming for the Prizm taught me how it’s like to work without the help of the C standard libraries (or better, with the help of incomplete and buggy standard libraries), what a stack overflow looks like (when there’s no stack protection), how flash memories work, what DMA is, what MMUs do and how systems can be bricked when their only bootloader is not read-only. It taught me how compilers work from an end-user perspective, what kind of problems and advantages optimizations introduce, and what it’s like to develop parts of the C standard library.
It also taught me Casio support in Portugal (Ename) is pretty incompetent at fixing calculators, turning my CG 20 into a CG 10 and leaving two big capacitors out of a replacement main board. In this hardware topic, I learned quite a bit about digital logic from Prizm hardware discussions at Cemetech. And I had some contact with SH4 assembly and a glimpse into how to use IDA Pro. Thank you Casio for developing a system that works so well and yet is so broken in so many under-the-hood ways, and thank you Cemetech for briefly holding the Prizm higher than TI calcs.
I developed other add-ins, some from scratch and others as ports of existing PC software (such as Eigenmath). I still develop for the Prizm from time to time, but I have less and less motivation as the homebrew community has stagnated and I use my Prizm much less, as I went to university. Experience in obscure calculator platforms does not make for a nice CV.
Yes, in three years or so I went from the likes of Visual Studio to a platform where the only way to debug is to write text to the screen. I still like embedded and real-time programming a lot and have moved to programming more generic and well-known things such as the ESP8266.
Getting in the elevator
During the later part of high school (which I started in the fall of 2011 and ended in the summer of 2014), I did more serious Python stuff, namely Mersit, later deprecated in favor of Picored, which is not written in Python but in Go. Yes, I began trying higher-level stuff again (higher level, getting in the elevator… sorry, I’m bad at jokes).
My first contact with Go was when I was 17, because I wanted to develop something that ran without external dependencies (i.e., unlike Java or .NET) and compiled to native code. I wanted to avoid C/C++, but I wasn’t looking for “a better C” either, so Rust was not it. Seeing so much stuff about Go at Hacker News, one day I decided to try my hand at it and I like it quite a lot – I’m still unsure if I like it because of the language itself or because of the great libraries one can use with it, but I think both play an important role.


This summer I decided to give C# another chance and I’m quite impressed – turns out I like it much more than I thought. It may have something to do with trying it after learning proper languages vs. trying it when one only knows VB. I guess my VB.NET scars are healed. I also tried a bit of Java, in my first contact with it ever, and it seems my .NET hate converted into Android API hate.
Programming with grades
University gave the opportunity (or better, the obligation) of having other people criticize my code. The general public could already see the open-source C code of my Casio Prizm add-ins, and even the ugly code of Goona Browser, but this time my code was getting graded. It went better than I initially thought – I guess the years of experience programming in different languages helped, especially as many of the people I’m being compared with have only started programming this year.
In the first semester we took an introductory programming course, which used Python, and while it was quite easy for me, I took the opportunity to learn Python to a greater depth than “language in which to write quick and dirty glue code”. You see, until then I had not used classes in my Python code, for example. (This only goes to show Python is a versatile language, even if slow.)
We also took an introductory computer architecture course where we learned how basic CPUs work (it was good for gluing all the separate knowledge I already had about it) and programmed in assembly for a course-specifc CISC-like architecture. My previous experience with reading SH4 assembly proved quite useful (and it seems that nowadays the line between RISC and CISC is more blurred than ever).
In the second semester, I had the opportunity to exercise my C knowledge, this time not limited to the Prizm platform. More interestingly, logic programming, a paradigm I had no intention of ever programming in, was presented to us. So Prolog it was. It went much better than I anticipated, but as most other people who (are forced to) learn it, I have no real use for it. So the knowledge is there, waiting for The Right Problems(tm). I am afraid I’ll forget much of it before it becomes useful, but if there’s something picking C# up again taught me, is that I can pick up pretty fast skills learned and abandoned long ago.
The second year is about to begin and there’s some object-oriented programming coming, I hope I do well.
Summing it up
I have written non-trivial amounts of code in at least 8 languages: Visual Basic, PHP, C#, Python, Lua, C, Go, Java and Prolog. I have contacted with two assembly dialects and designed web pages with HTML, CSS and Javascript, and of course automated some tasks with bash or plain shell scripting. As can be seen, I’m yet to do any kind of functional programming.
I do not like “years of experience” as a way to measure language proficiency, especially when such languages are learned for use in short-lived side projects, so here’s a list with an approximate number of lines of code I have written in each language.
- C: anywhere between 40K lines and 50K lines. Call it three years experience if you will. Most of these were for Prizm add-ins, and have since been rewritten or heavily optimized. This is changing as I develop less and less for the Prizm.
- PHP: over 15K lines, two years if you want to think that way. The biggest chunk of these were for developing the additions to YOURLS used in tny.im, but every other small project takes its own 200-500 lines of code. Unfortunately, most of this is “bad” code, far from idiomatic. The usual PHP mess, you know.
- Python: at least 5K lines over what amounts to about six months. Of these, most of the “clean” lines (25-35%) were for university projects.
- Go: around 7K lines, six months. Not exactly idiomatic code, but it’s clean and works well.
- VBA: uh, perhaps 3 or 4K lines, all bad code 🙂
- VB.NET: 10K lines or so, most of it shoddy code with lots of Try…Catch to “fix” the problems. Call it two years experience.
- C#: 10K lines of mostly clean and documented code. One month or so 🙂
- Lua: mostly small glue scripts for my own amusement, plus some more lines for use in games such as Minetest, I estimate 3-4 K lines of varying quality.
- Java: I just started, and mostly ported C# code… uh, one week and 1.5K lines?
- HTML, CSS and JS: my experience with JS doesn’t go much beyond what’s needed to modify DOM elements and make simple AJAX requests. I’ve made the frontend for over 5 websites, using the Bootstrap and INK frameworks.
- Prolog: a single university assignment, ~250 lines or one month. A++ impression, would repeat – I just don’t see what for.
In addition to all this, I have some experience launching the programs and services I make – designing logos/branding, versioning, keeping changelogs, update instructions, publishing, advertising, user support. Note that I didn’t say I’m good at any of these things, only that I have experience doing them, for better or worse…
Things I’d like to have more experience with:
- Continuous integration / testing in general;
- Debugging code outside of .NET/Visual Studio and printing debug lines in C;
- Using Git and other VCS in big repos/repos with more people (I want to see those merge conflicts and commits to the wrong branch coming);
- Server-side web development on something other than PHP and Go. And learning to use MVC frameworks, independently of the language;
- C++ (and Java, out of necessity. Damned Android);
- Game development. Actually, this is how many people start, but I’m so cool that I started by developing POS software 🙂
August 1, 2015 / gbl08ma / 1 Comment
After yesterday’s popular post Windows 10 is unfinished, where I bashed said OS, today, I’m going to praise Windows 10 (where possible). This is so we can keep with the opinion diversity people are now accustomed to seeing on the Web, faithfully satisfying the thousands of Reddit and Hacker News users who can’t skip a beat on hot technology topics and especially, hot discussions on those topics.
A lot of people took my post as my definitive opinion on the matter and also as if I was telling some universal truths, and mistakenly concluded that I only had negative things to say about Microsoft’s latest big release. Others were saying I focused on the wrong problems; that the design issues were minor nitpicks, and effectively they are, when compared to the functionality problems (which I’m also having, but apparently that part was overlooked). My intention was not to write a fanboy post nor to start flamewars, and that’s the case with this post too.
Yesterday’s post was written from start to end on my Windows 10 tablet, without hardware keyboard (yes, it was painful, but not as much as it would have if using an Android tablet with similar characteristics), including screenshots and image editing (MS Paint FTW!). That’s not the case with today’s post, that was written with my laptop, because Microsoft is yet to issue an update to fix the virtual keyboard in Windows 10. The OS it is running doesn’t matter; let’s just say I’m writing this in MS-DOS 6.0’s edit.
Let the deserved Windows 10 appraisal start.
Upgrade process
I upgraded from Windows 8.1, before Microsoft decided it was ready for me to install it. Yes, I forced the download and installation process. I wanted to get it downloaded before the end of July, so that it would not count towards this month’s data cap. I wanted to get it installed because I thought it would have tons of updates to download in the first days (not the case), and also because I’m going to need this tablet operational by September when university classes begin, so I thought I better get used to it and point out all mistakes sooner rather than later.
Yes, I could have stayed for another year on 8.1 before losing the option to upgrade for free, but I’m also interested in developing Universal Apps, so here’s that.
Despite me rushing the update and the tablet having 32 GB of storage of which only 22 GB are for the Windows partition, the process went perfectly, and apparently I still have the option to go back to 8.1 if I wish (at the expense of only having 2 GB of free disk space on C:). All data and apps were kept, except f.lux, possibly because (as far as I could understand when uninstalling its remnants) it was installed in AppData (note that AppData is mostly kept, too, but f.lux in particular wasn’t).
From leaving Windows 8.1 to seeing Windows 10 desktop it took my tablet about a hour and half. The flash storage on it is not especially fast (definitely not a SSD), which probably explains why most people can do it in one hour.
All points taken into account, the upgrade process went surprisingly well and was fast, as appears to be the case with the majority of users. Much better than ending up with a system that doesn’t boot at all, or with driver issues (which some users are still having), which as far as I remember were popular problems in previous versions’ in-place upgrades. Also, kudos to Microsoft for making it work on devices with such a limited amount of system storage.
Initial setup
There was the first-run setup, where the polemic privacy defaults are located (I disabled almost everything), but the most complicated part is what comes when the system finishes installing. In my case, Windows understood this was a tablet and accordingly selected tablet mode automatically. Because on 8.1 I basically only used the desktop, and because I thought it would be easier to find most settings on the desktop mode, I immediately went looking for the switch and since then I have only used desktop mode.
The desktop mode still works very well with touch screens; I have gone back to tablet mode for five minutes just to check it out, but went back quite fast, as I deemed the desktop good enough. Tablet mode didn’t fix the problem of the touch keyboard appearing over other windows even when docked, which would have been its major selling point for me right now.
Windows 8’s modern apps were kept from the previous version, including the MSN-powered apps such as Travel, which have been discontinued and will stop working in September. Of course, those who have an Universal app replacement (Mail, Calendar, Twitter, Maps, possibly more) are replaced. In the case of Mail and Calendar, it remembered the previously added account, but I had to pair them again in the case of Google and Microsoft accounts, and re-insert credentials for IMAP accounts.
OneDrive apparently now refuses to have its folder out of the C: drive, or perhaps that’s only a problem when the folder you want to chose is on a removable drive. I solved this problem by mounting the SD card, where I had the OneDrive folder, on the C: drive (NTFS mountpoints FTW!), then pointing OneDrive to this mountpoint. Yes, I know what I’m doing and you should too. This SD card, unlike what Windows thinks, is never removed.
I also had to download desktop Skype. Before I was using the Modern UI version of Skype, which was discontinued some time ago. But the desktop version uses so much RAM and is less touchscreen friendly, making it one of the most annoying parts of my Windows 10 experience. It also doesn’t update with new messages during Connected Standby, which is a thing my tablet has and I’m going to talk about later, and it doesn’t put its notifications in the new Action Center, either.
Tablet usage
People are saying the tablet experience has actually gone worse with Windows 10, but to be honest if they fixed the touch keyboard I’d say it is as good as Windows 8. Of course, if you are used to the charms bar and to the gesture of “swiping down an app” to close it, you’ll be out of luck:
- swiping from the top on a window does nothing except move or restore it (if it was maximized);
- swiping from the left opens the Action Center (where some handy, more or less configurable shortcuts are located, so you won’t miss the “Settings” part of the charms bar);
- swiping from the right shows the task view, where you can switch apps and desktops;
- sadly there’s no longer a way to bring up a big clock, even when running full-screen stuff (games, videos…), something the charms bar was good for.
As it’s been widely reported, now Universal apps, Windows 8 apps and “normal” software made for the Win32 API all work together, with the same window borders and titles and showing on the same task lists. If only it had been this way since the beginning, Windows 8 would not have received so much negative critique and “Modern apps” could have actually been more used. Yes, I believe windows are adequate even for tablet devices (and not just by putting two windows side-by-side), and that is certainly one of Windows differentiating factors in the world of tablet OS.
Resource usage
I still can’t comment much on this part, because I’m having some issues with my Voyo A1 Mini that look not like Windows fault but driver problems. The “System” process (i.e., the NT kernel) is often using multiple MBs of RAM. I know I’m not the only user with this problem; there is at least one known bad network driver, but I don’t use it. I’ve also seen suggestions for disabling the network device usage service, but in my case that didn’t help. The result is that it always has 90-95% of physical memory used, and the commit charge at something like 3 GB of 3,9 GB.
I have also noticed search indexing stuff has gone more aggressive again on Windows 10, after being mostly quiet on 8.1 (as far as I could see). But since I haven’t done any serious monitoring, this could be just my impression.
The update could also have damaged the special CPU throttling set up for this device, given that it now runs much more hot than before, even for the same typical load. It appears the CPU (Intel Baytrail) works at higher frequencies more often – just a slight load and there it goes to 1,55 GHz or so (the “announced speed” of the CPU is 1,33 GHz). I have updated to the latest DPTF (Intel’s thermal stuff) drivers and it reduced the problem a bit, but it’s still present.
Now, this isn’t all that bad, given that Windows is very responsive even with the CPU at 75 degrees Celsius and 95% of the physical memory used. Let’s just wait for updates, both for Windows and for drivers, before taking more conclusions.
Connected Standby is still annoying
My tablet supports Connected Standby. On Windows 8, it was more or less like suspending the computer, but Windows Store apps could still run in the background to perform small tasks, and if you were playing media in such an app, it would keep playing even with the screen off – just like with Android devices.
The problem is if you want to use something other than a Windows Store app (read: 99,9% of the software available for Windows) to play music, or download files, or if you want to watch YouTube with something other than IE’s Modern UI mode. Windows will just suspend desktop apps and they will stop playing, or downloading, or crunching numbers. What makes this really annoying is that there is no way to turn off the screen without entering Connected Standby. So it’s burning extra battery and, at night, our eyes too.
In Windows 10, Connected Standby is more or less the same thing. I hoped that with Windows 10 they would add an option to be able to white-list certain “old fashioned” (Win32) apps into running during connected standby, or alternatively, a way to turn off the screen without going into standby.
At least, the “Sleep” and “Turn off the screen” settings now seem a bit better decoupled, and with my current settings (turn off screen after 2 minutes, sleep after 4) there is a bigger delay between when the screen turns off and the music stops playing. During this delay one can tap the screen and it will turn back on, instantly. Just like with a normal laptop that turns off the screen after a while. Let’s just hope Microsoft doesn’t consider this to be a bug and doesn’t “fix” it.
Cortana
I can’t comment much on the Cortana feature itself, but I can comment on the stuff surrounding Cortana and whether the feature is enabled or not. Here, Windows is set up with a system language of US English. The region was set to Portugal, and the time and date and formatting settings to Portuguese. I was told by a friend I had to set my region to US for Cortana to become available, and that’s indeed true.
I just don’t understand, if Cortana is going to speak in English anyway (because that’s the system language), why does it have anything to do with the region. Unless it is expecting to change the language it uses depending on the region setting, and not depending on the language I want to see (and hear) stuff in. Oh well.
Finally, I have watched Cortana tell me how awesome are all the things that can be done with this feature, but I didn’t enable it because of the privacy policy, and I don’t think I’d use the functionality enough to be worth yet another “I agree” on a privacy setting. I can always turn it on later.
Feedback
Microsoft seems really interested in listening to what the users have to say, so there’s a dedicated feedback app and everything. Unfortunately, this app filters content by region instead of filtering by language, which limits what reviews you can see and upvote. I wonder if anyone from Microsoft will look at the feedback of less populous countries like the one I live in, and even smaller ones.
Microsoft also seems really interested in learning how people use the OS, so much that only Enterprise users can completely disable this kind of feedback. Privacy concerns aside, I really hope the data generated with these feedback tools won’t be used as motivator or justification for taking away even more features and customization ability.
Rolling release
I always wanted to move to a rolling release Linux distro, but I’m yet to make the move; it appears I switched to a rolling Windows release before I did the same with Linux! I actually think it is a very good idea to stop releasing major versions and put new things out in a more continuous way. Major upgrades are a hassle, even when the upgrading itself takes just one hour – first, a giant download, then having to wait while the Windws upgrades and reboots multiple times, then having to set so many little settings that are new or changed with the new version…
I would be even happier if every user had the ability to refuse or at least delay certain updates (even because of, say, known driver and software incompatibility issues). The way things are done right now, only makes the whole thing look like a giant Microsoft-controlled botnet and by paving the way to Windows-as-a-service, makes people fear a future where you’ll pay for Windows by the month (and perhaps by the window/app/user?).
Finally, it’s about time Microsoft finds an ingenious way around the way file handles work in Windows, such that system files can be replaced without rebooting the system. Or at least, they could make the reboots less disrupting, for example by “suspending” the apps before the reboot, then restoring them.
Conclusion
My conclusion is to sit and wait. Windows 10 is actually pretty good for what feels like the end result of a development cycle damaged by setting a release date way too early. It should have been ready when it was ready, but I understand Microsoft not wanting to deal with another “XP to Vista” situation, where it took five years to release a new OS version with an abandoned revolutionary version in between, and a shitty end result. This way, the most people can say is that it’s shitty, but at least it came on time.
If you are using Windows 7 on a desktop and are happy with it, or using 8.1 on a tablet, I don’t think you have much to gain by upgrading now, unless you desperately want to use Cortana. People using Windows 8.1 without a touchscreen may find more value in upgrading now, especially if they use Modern UI apps and are annoyed by the context switches between them and the desktop.
Anyway, I always wanted to try Longhorn in its unstable and unpolished state, and now here is an opportunity – not with Longhorn, but with another revolutionary Windows version that while stable, has its own big polishing needs. But we already talked about that…
July 31, 2015 / gbl08ma / 80 Comments
Windows 10 came out some hours ago, and, surprise surprise, it’s unfinished! I can’t complain about the system stability (even though the Windows Reliability History tells me there have been some errors happening in the background), but the RAM usage has gone up when compared to 8.1. On a device with just 2 GB of RAM, this matters, but not nearly as much as what’s coming next…
What’s worse is really the touch experience – ruined, compared to 8.1. Imagine the touch keyboard no longer docks properly, which means 90% of the time the cursor is behind the keyboard, and I can’t see what I’m writing (I can’t believe nobody complained about this in the previews!). Then there’s the ultra-invasive privacy settings defaulting to on, which I disabled on the first run setup, but apparently, some choices were ignored – for example, I disabled error reporting, and when later I went to check, found it enabled in its highest level.
Windows 10 still suffers from many of the problems of Windows 8 in terms of UI inconsistency. The void between the “modern” UI and the classic desktop is greatly reduced, with Modern apps and Universal apps running windowed just like all other software. But things are far from perfect.
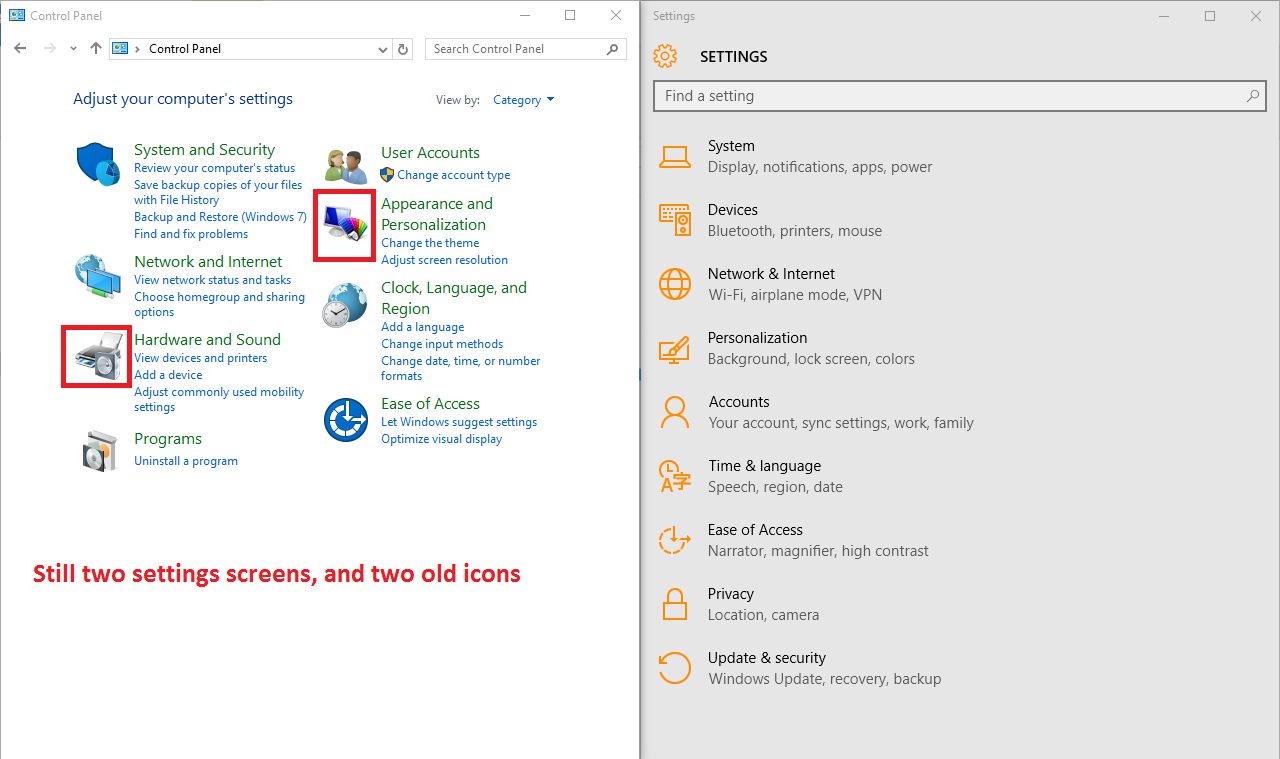
Microsoft didn’t quite manage to get rid of legacy design paradigms, and the OS still speaks at least three different design languages: if you look carefully, you’ll see elements that would fit better in Windows 7, others that are the continuation of the “modern UI” design, and things that would really fit better in XP and earlier (like the small, tabbed setting dialogs reachable from the legacy Control Panel).
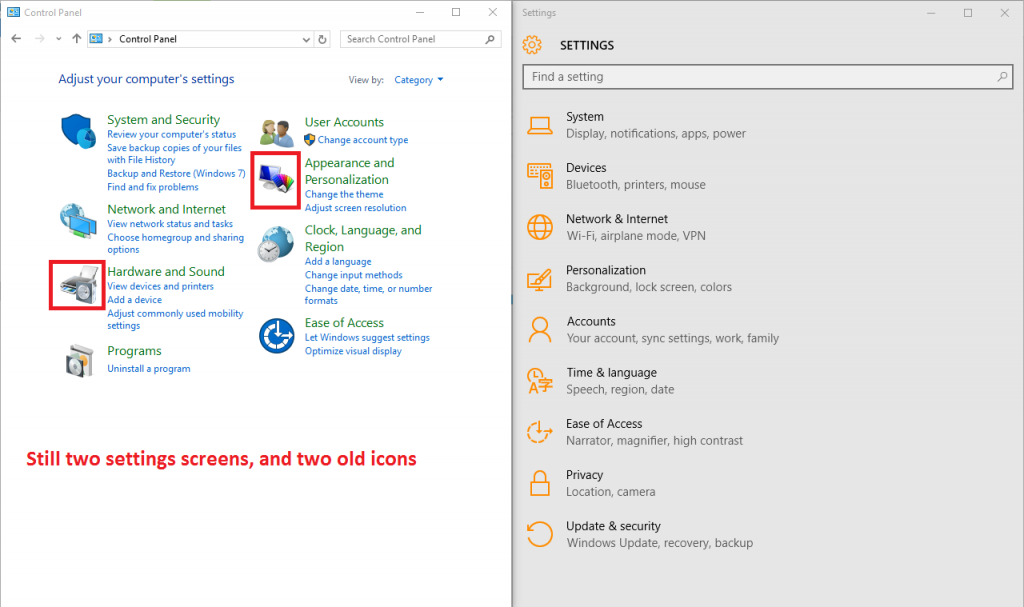
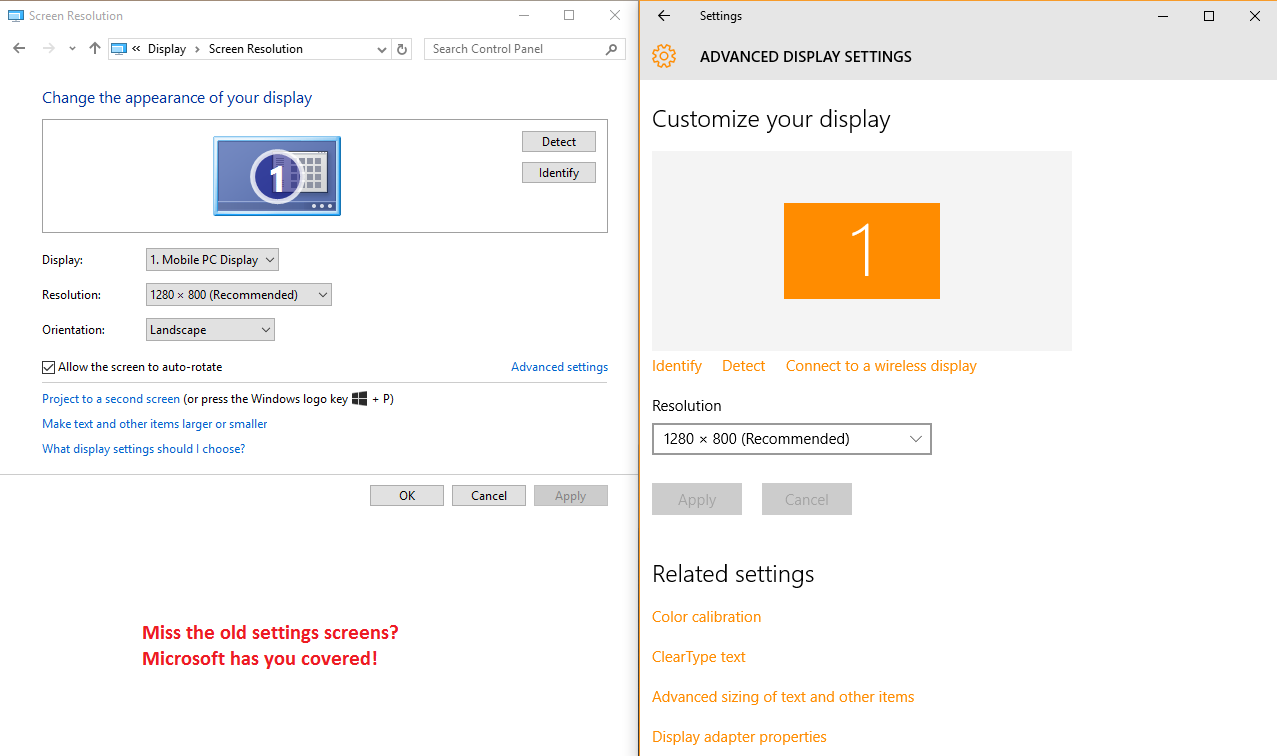
There are still two control panels, with certain things only accessible in one of them, and others available in both but with different names for the same thing (or the same thing, but negated, as is the case with screen rotation lock – in some places, “on” means “do not rotate”; in others it means “allow rotation”).
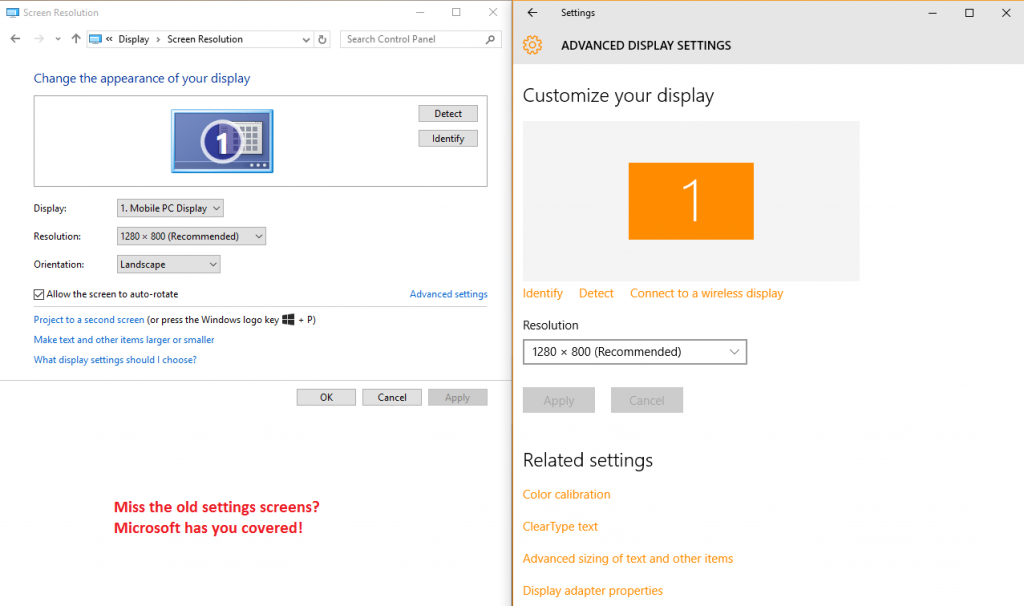
At least, there are now some more links between the two settings panels, but sometimes Windows will just tell you “This setting is now on …” without actually taking you there.
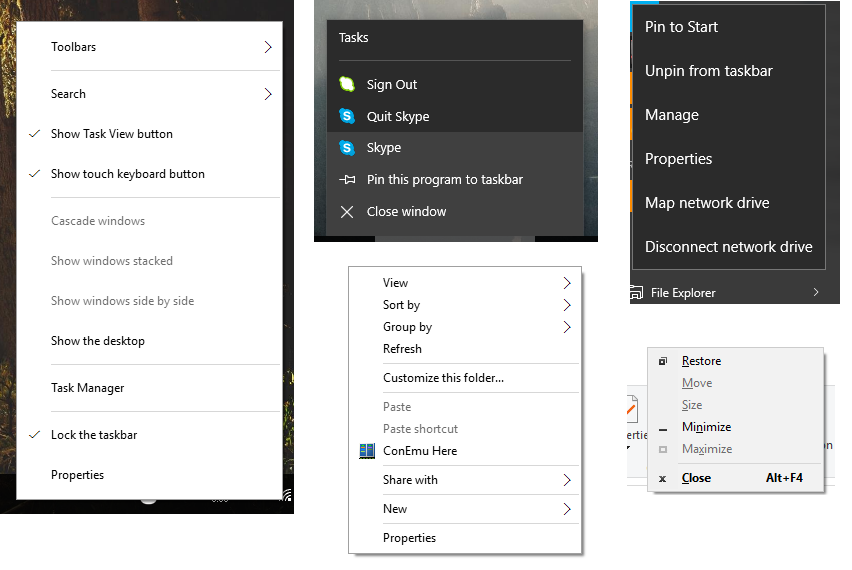
Depending on where you right-click (and, for certain things, how the planets are aligned) you can open at least four different styles of context menu.
Both Windows 8 and 8.1 were, even despite their messy paradigms and inconsistent styles, more polished in terms of looks than Windows 10. Windows 10 has an incomplete icon set, with many icons yet to be updated to the new design. The fact that the icons are very different from those of 7 and 8 (the icon change from 7 to 8 was much more subtle) only makes the problem worse. You really don’t need much effort to find icons yet to be updated.
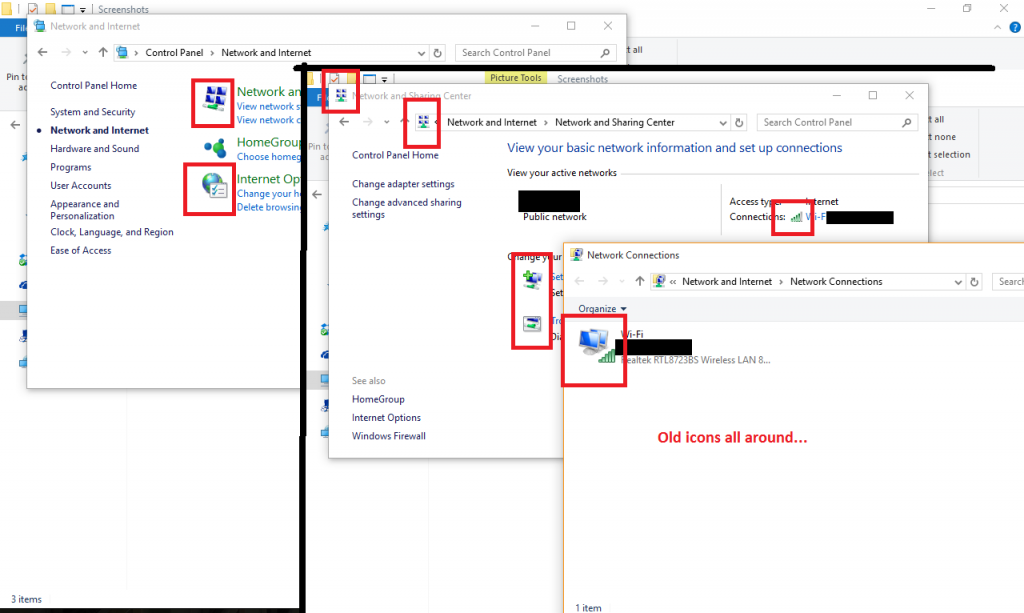
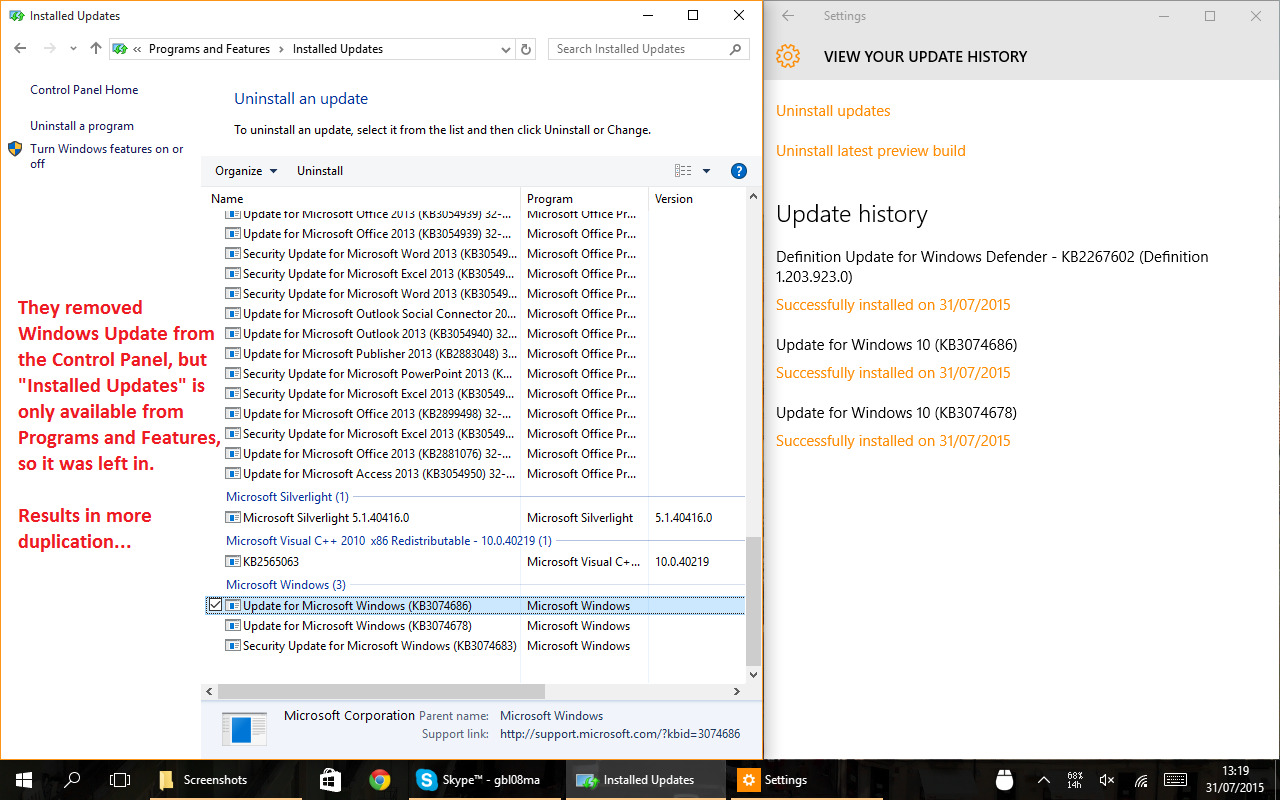
Leaving design aside, we can see that they tried to remove some functionality, like Windows Update, from the legacy Control Panel. But the migration transmits a feeling of incompleteness:
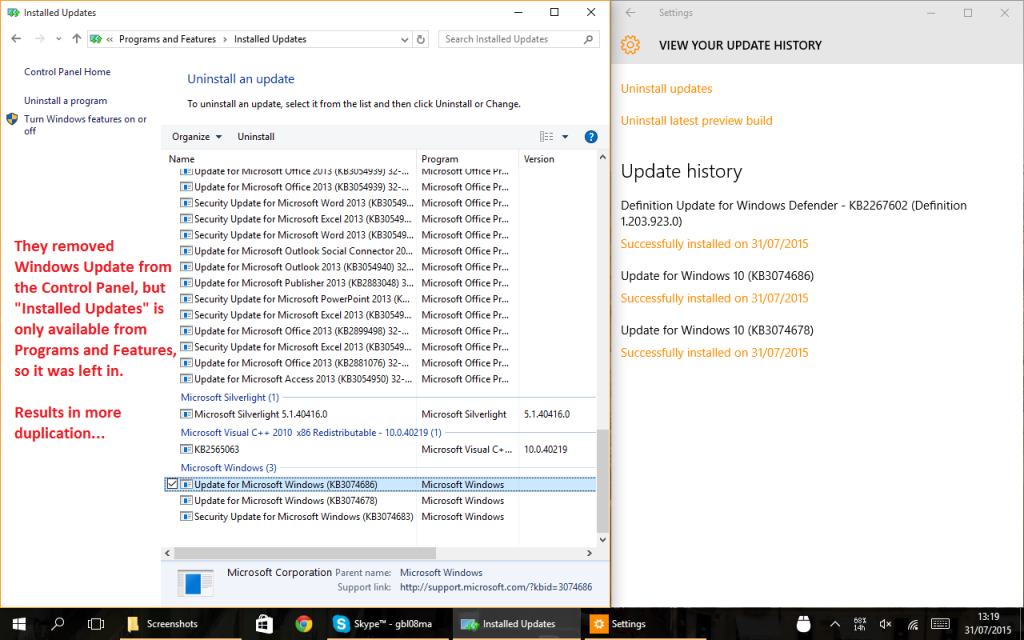
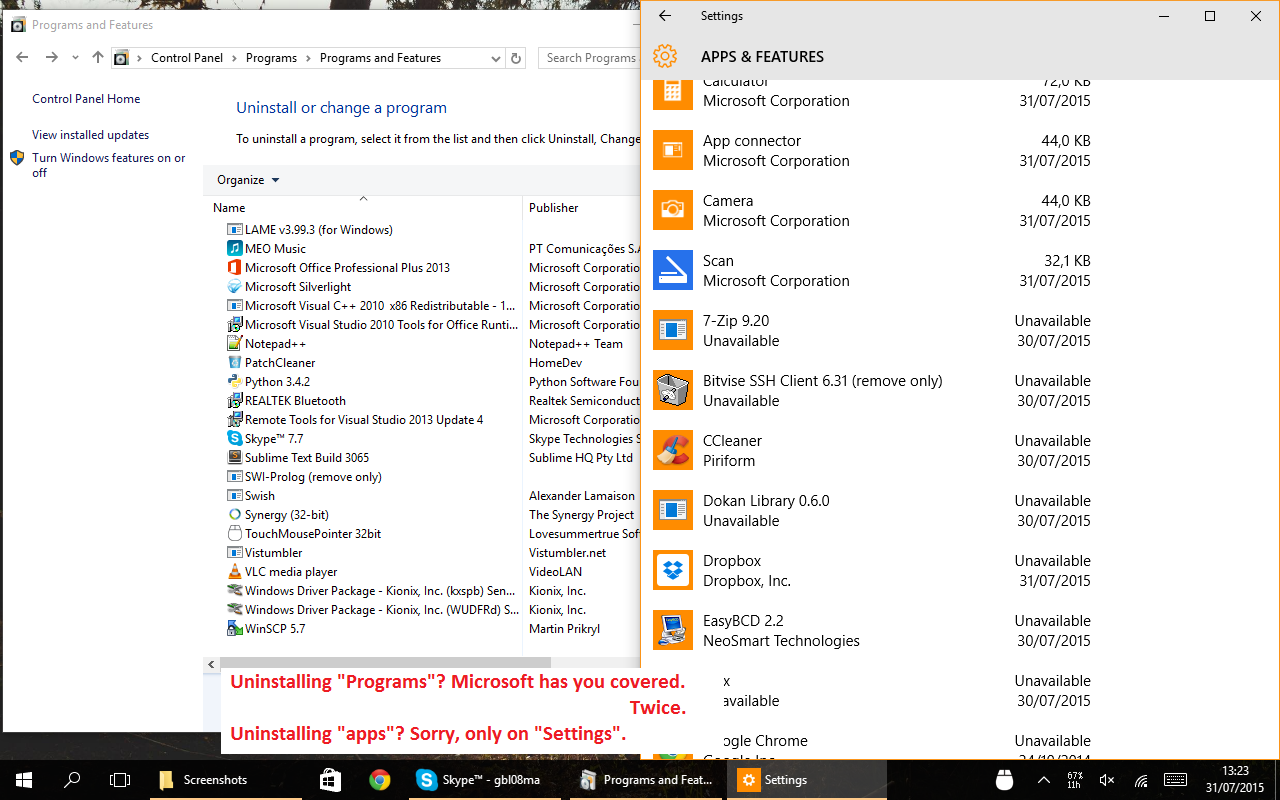
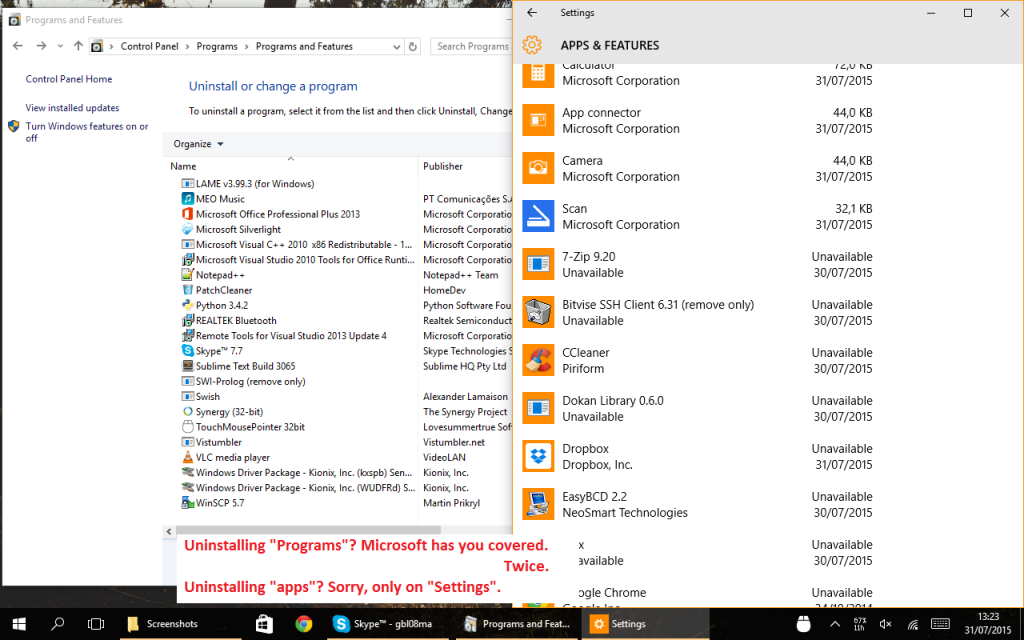
Many settings are duplicated in the Settings app and in the Control Panel. But it’s often not a 1:1 relation: to uninstall modern apps, for example, you must go through the Settings app. Going through the old Programs and Features won’t show these apps.
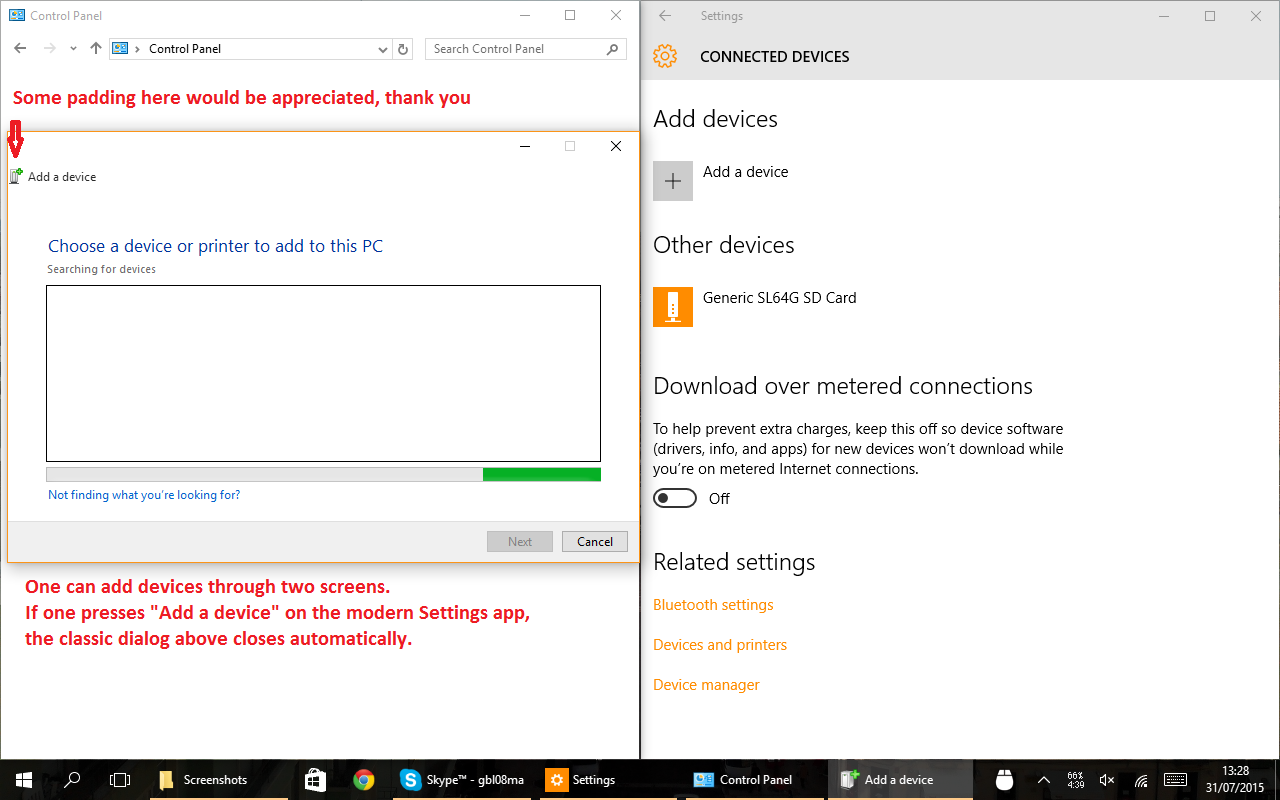
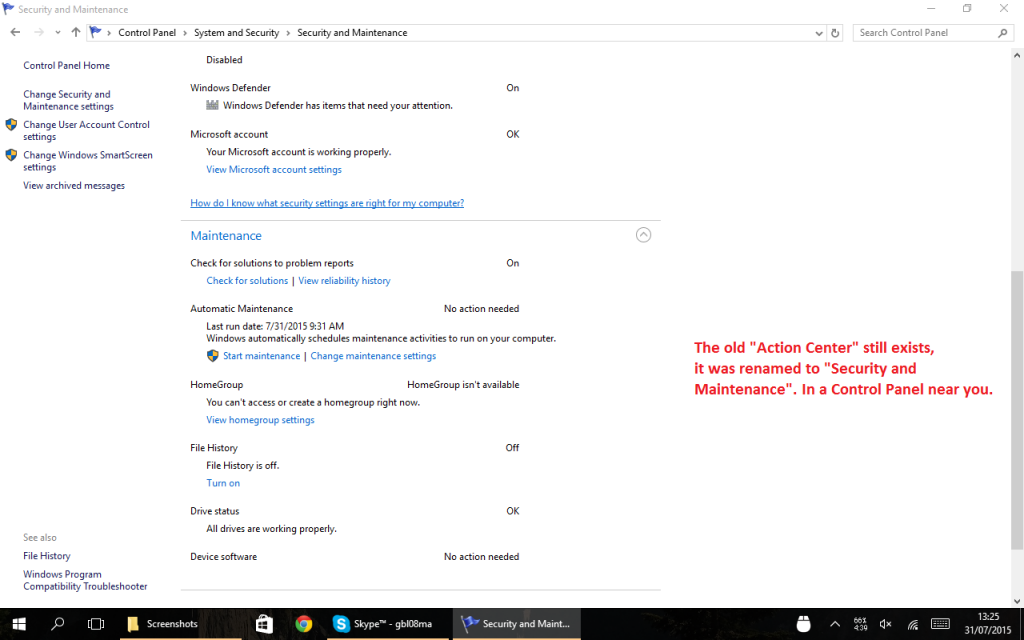
Certain things were renamed – the “Action Center” is the new notification center of Windows 10 (which is a really appropriate name, and what the Action Center should have been since the beginning). If you are looking for the old thing, it still exists:
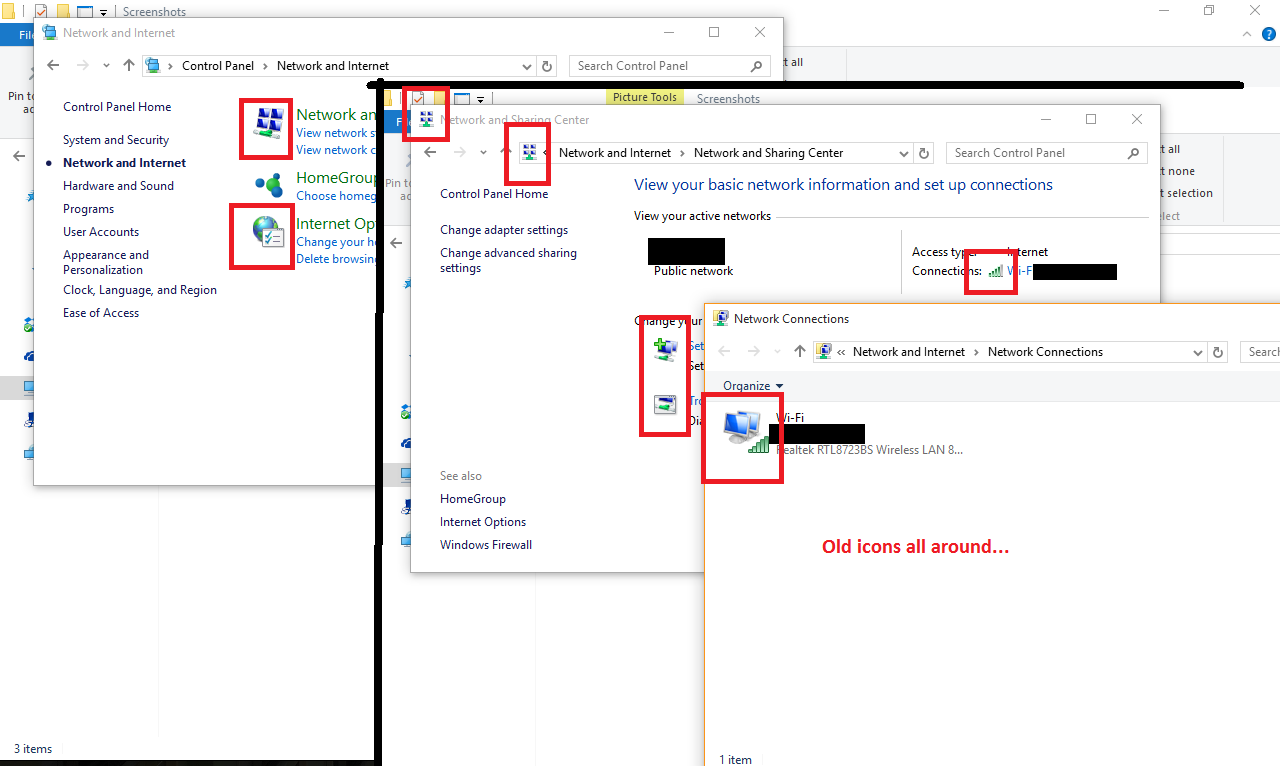
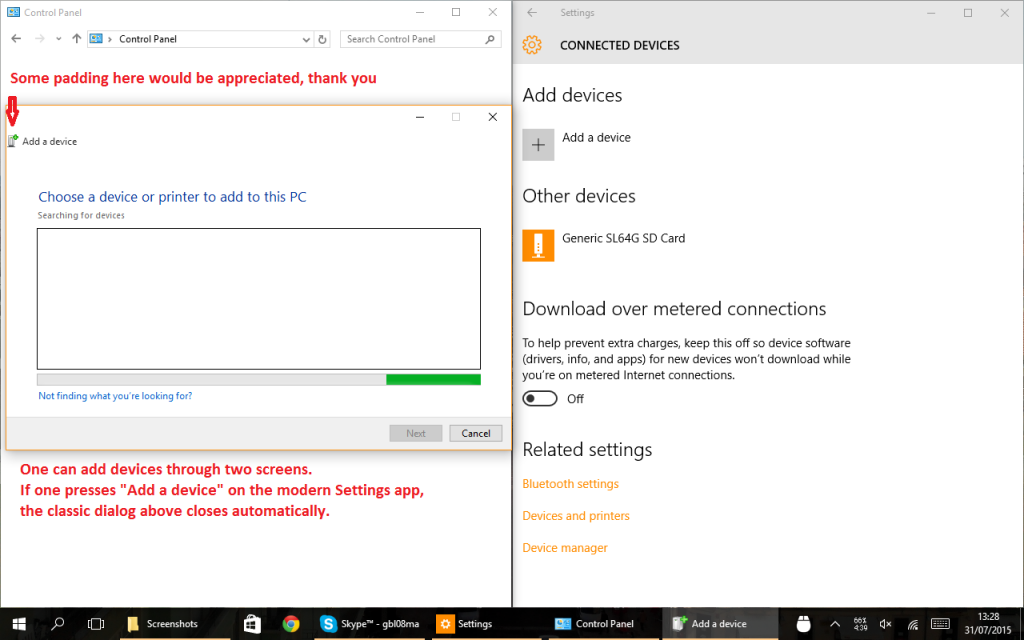
There are at least two ways to add devices, with different UI flows. Also note the lack of padding on the icon of the window to the right:
The sometimes useful Math Input Panel is still stuck in the past of Windows Vista or 7, with obvious readability problems in the menu:

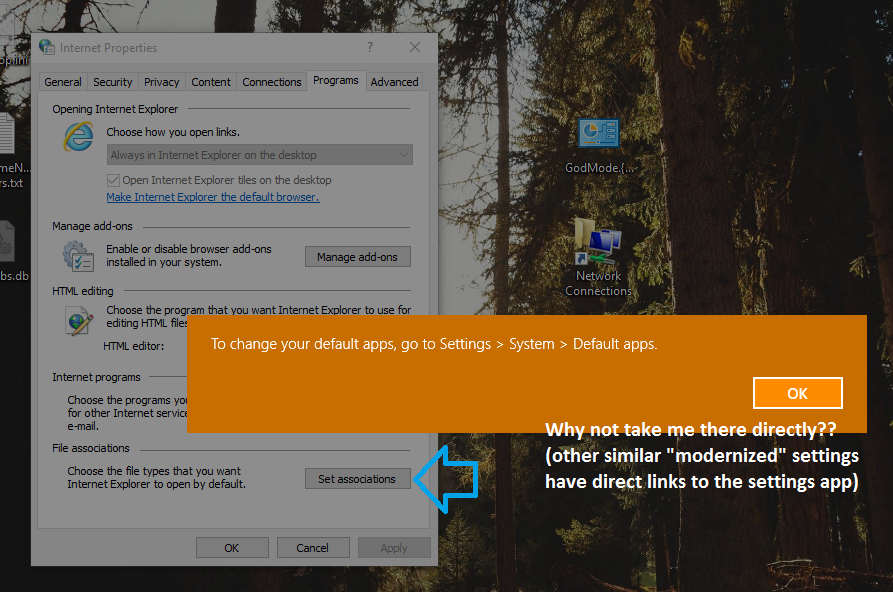
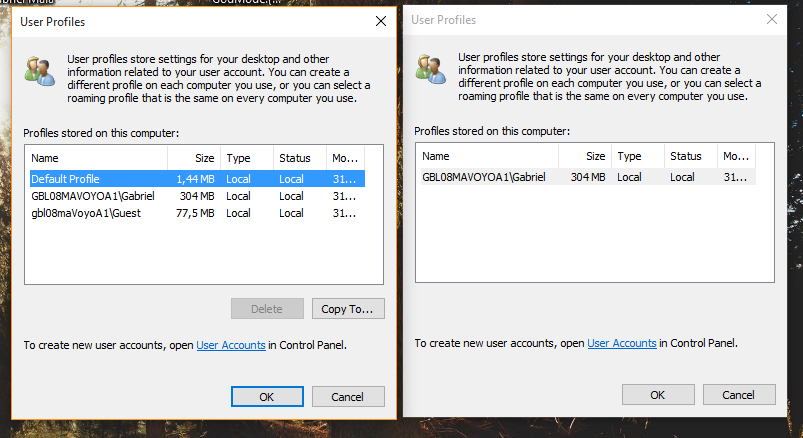
Then there are gems like this dialog, that depending on from where it is opened, shows different items (possibly not exclusive to Windows 10):
The first non-preview release of Windows 10 still contains too many rough edges and suffers from a lack of attention to detail I was only used to seeing in older Windows’ preview releases. I say “first non-preview release”, because as Microsoft is switching to a rolling release model, it no longer makes much sense to call this a “final release”.
Intentionally or not, Microsoft pushed the quality assurance process to the final user. For what is supposedly the best Windows ever made, I’m not impressed. Thank God I didn’t pay for it (even though it’s for sale, and it’s not cheap).
May 1, 2015 / gbl08ma / 0 Comments
Some years ago, I followed a blog […]. I liked much of the music that was shared there, and somehow it worked best for me than any recommendation engine. […] In the hope that there may be someone out there with a taste for music mostly similar to mine and lucky enough to get to this website, starting May 2015 I’ll share in this page the monthly additions to my music collection. Hopefully this will also answer the “what do you even listen to” question that pops up among friends from time to time.
—
A few years later, all the music recommendation/discovery engines I know are like this: 60% of the suggestions don’t fit my taste and the other 40% are already in my collection. What about starting to do some sound analysis instead of blindly following things like LastFM’s “related” list of artists and (often incorrect) genre tags? The suggestions SoundCloud puts to play, automatically, after finishing a track, are the closest I have heard to actually finding music similar to what I was listening, but I may have just been lucky so far.
Let’s see how this goes.
March 9, 2015 / gbl08ma / 0 Comments
Here’s a new video showing another set of features of the upcoming v1.5 of my Utilities add-in, for the Casio Prizm. Note that this is only an early preview and some things may change until the final release. Meanwhile, feel free to comment.
February 2, 2015 / gbl08ma / 0 Comments
Just two days ago, I mentioned in this blog the Windows port Microsoft made for the ARM architecture:
Microsoft, for things like the (abandoned) Windows RT and Windows Phone, besides porting some of the upper layers of the Windows stack and developing new ones, also had to do additional work to get the NT kernel to run on such hardware. It’s worth mentioning that despite that effort, Windows Phone 8+ has hardware requirements higher than those of Android (comparing versions released in the same time span, please correct me if I’m wrong).
Today, as I open the web browser I’m greeted by multiple related news: a quad-core ARMv7 / 1 GB RAM version of the popular Raspberry Pi board, named “Raspberry Pi 2”, was released, will run Ubuntu Snappy Core, and, mind you, Windows 10.
Now that Windows RT is pretty much dead in the water, it looks like Microsoft found at least one use for their port besides Windows Phone: a strategically introduced “Windows 10 for makers”, which is free – something that would come out as impossible some years ago, in the license-angry Microsoft phase. (Yes, just like they also offered the Windows 8.1 license to OEMs of tablets with screen >= 7 inches, and apparently will offer Windows 10 to Windows 7 and 8.1 users for one year after its release). Of course, there’s no news of this Windows version being the slightest open-source – that is something that in the beginning of 2015, is still thought as “impossible” – but Microsoft is making promising steps, after having open-sourced the .NET framework.
Now, let me explain: while this is a nice move from Microsoft, is not something that leaves me particularly happy (in fact, it leaves me somewhat worried, and it’s not because “OMG OMG Linux is going to lose market share”). For starters, there’s the fact that there have been way more powerful ARMv7 devices around for a long time, for a similar or equal price ($35 USD) – take a look, for example, at the ODROID-C1, so why didn’t Microsoft decide to offer Windows for those too?
The answer, in my opinion, is very simple: Microsoft wants to “look cool”, and benefit from the free advertising and consequent increase of popularity a partnership with the Raspberry Pi Foundation has. Releasing Windows 10 for ARM in a more flexible setup (one that would support different boards besides the new Raspberry Pi) would be even more interesting to the community and probably more flexible for wearable, IoT, etc. projects, but that’s not the path they chose.
Supporting only the Raspberry Pi is also the easiest option, partly due to the lack of standards in the ARM world, which I complained about in the aforementioned blog post. Supporting other boards would lead to a lot of work supporting the different SoC, different peripherals, different boot methods and imaging formats (nothing that Microsoft couldn’t abstract away with a generic second-stage bootloader for WIM files), etc. In other words, it would leave them with as much work as the Linux community has in order to support different embedded systems and CPU architectures (heh).
Something that’s still unclear to me is the licensing part. This Windows version, while free, certainly comes with caveats. I’m sure Microsoft won’t allow using it on consumer products based on the Raspberry Pi (for example, using the upcoming version 2 of the Compute Module), as otherwise it would constitute a free alternative to licensing Windows Embedded. I also expect this version to come severely crippled as not to be able to act as a server; otherwise, expect some cheap Windows servers coming up soon. Even if it’s not crippled, the EULA rules it all, which means that even if a port of this Windows to other ARM boards and devices was possible, or if someone starts selling RPi-based Windows ARM servers, it most likely would not have Microsoft’s blessing.
I’m also a bit worried that the Raspberry Pi Foundation might start to push for Windows instead of Linux, especially since I bet the Windows port will be much more popular than the Linux distros. Doing so would kill half of the purpose of the whole Raspberry Pi thing, in my opinion. Most kids, given the opportunity to use the same user interface and some of the programs they are already used to, will never try to learn new things, much less tinker with them. Having them use a different GUI, or perhaps no GUI at all, by booting directly to a shell (try that, Windows! The closer you can get is the command line on a Windows Recovery Environment! heh) allows for an experience that is, from the start, much different from what they would get with a typical off-the-shelf computer.
By making people move out of their “comfort zone”, the Raspberry Pi Linux distros encouraged people to learn their way around a different system. I’m afraid people who buy a Raspberry Pi and promptly install Windows on it will keep without knowing what a command line is, and will keep doing the same things they did on their full computers. Text-based UIs are definitely not the best option for many/most things, but there are many things they’re better at than GUIs, and more importantly, some people find them out to discover they like them much more than GUIs. But if these people are never given the opportunity, they will never find it out.
Now I must admit, it would be super awesome if Microsoft came up with something like FX!32 but for running x86 binaries on ARM. That would probably require an even more restrictive EULA and/or more crippling for this Raspberry Pi version, as then people would be able to run, for example, all sorts of existing server software that currently requires a paid Windows Server license.
To conclude, I don’t think Microsoft is actually interested in making Windows available for more devices or actually making it a viable choice for low-cost embedded hobby projects and consumer products. They are just trying to gain popularity among not only the general public, but also among the developer and hobbyist community. Unfortunately, I’m not sure if this movement of “embracing OSS and open-sourcing ALL THE THINGS!” is going to last when/if Microsoft reaches their market share goals.
We can look into how the competition did: Android, initially pretty much completely open source, was made more closed as its market share increased. Google keeps on moving more and more things to closed-source blobs under their control, which has upsides (it’s easier to update many parts of the OS) and many downsides (lower user control, etc.). I wonder and worry if Microsoft will do something similar as their popularity endeavors are successful, turning their back on users, developers and all this “freedom hype” once again.
January 31, 2015 / gbl08ma / 0 Comments
On 24th June last year, Version 1.4 of my Utilities add-in for the Casio Prizm calculators was released. The plan was for this to be final release of said software, with any further versions being bug-fixing only, and because of this, it was even more thoroughly tested than previous stable releases.
Ironically enough, an apparently innocent code optimization, introduced at a late development stage, introduced a bug in the Tasks functionality of the add-in, where a reference to a nonexistent memory object may happen when there are no tasks. At this point, I was more or less tired of the Casio Prizm platform, because of the many issues I have described throughout the years, and which the homebrew development community is yet to fully solve. However, as time went by, occasionally I’d look into my Prizm projects and I’d inevitably end up optimizing yet another function, or adding another small functionality.
This, plus the desire to iron out some edges, led to the discovery of another bug, this time in the calendar search function. After lengthy debugging sessions it turned out to be a buffer overflow issue that could happen when reading malformed calendar database entries. Fixes for these and other bugs, plus the functionality I added as I had time and will, made it clear that releasing a new version of Utilities was imperative. I often ask myself if continuing the development of such project is still worth it, since:
- I use my Prizm much, much less than I used to (finishing high school marked the end of the period in my life where graphic calculators were needed for education);
- The community of users of these calculators was never very big, and keeps on shrinking. Of the people who go on online communities dedicated to these calculators, some lost interest on the device, and others lost the device to a brick, for which nobody is able to pinpoint a certain cause. Taking into account the results of my survey so far, the intersection between the group of people who own a Prizm and the group of people who search for software for it, seems to be contain no more than 50 people;
- Of the people who remain in the communities, most never paid much attention to Utilities (due to feature creep, it’s likely that most people never understood its power) and the amount of users that still pay attention has reduced too (as well as their attention span for it).

Apparently, at least one hundred thousand of these devices are produced every month, but the amount of users who know they can run extra software in them, is in the order of the few dozens.
Despite all this, such questions are promptly answered by the fact that I still have fun developing it, even if nobody gets to use my work. And so development progresses, albeit at a much more relaxed rhythm, firstly because v1.4 is still very stable (at least, no one complained), and secondly because there is no roadmap to v1.5 nor planned release date. Heck, if I wanted to, I could not release it, and zero people would complain… but perhaps not after seeing what’s coming.
On the video below (without sound), I show a small subset of the new functionality for v1.5 (if it ever gets released, heh heh). The part that, in my opinion, is going to leave the mouths of some people open, starts at 3:30. It is an elaborate method to allow people to extend Utilities to a certain point, by having an easy way to use the big amount of utility functions used internally, as well as the nice GUI methods I developed. As if this wasn’t enough, one still gets access to most known syscalls (those that involve function pointers being the notable omission). What’s presented is, after all, the most powerful scripting engine ever made to run on the Prizm, and because of this one gets goodies like on-calculator development.
As hinted in the video, “PicoC script execution available on select builds only”. Starting with version 1.5 of Utilities, there will be two public builds made available: the normal one, with the now usual feature set plus the added features but without PicoC, and another with all that plus PicoC support enabled. The reason for this, is that such support increases the size of the add-in by at least 60 KiB, and as can be seen in the video above, the scripts have (almost) full reign on the machine, including read/write access to the whole address space (in the video, you can see a script changing the function key color, and while it’s not depicted, it also locks and unlocks Main Menu access). This means that a script can definitely brick a calculator on purpose, and do all the sorts of nasty (and good) things an add-in can do, except use syscalls with function pointers (the reason being, that PicoC doesn’t support them). It’s understandable that not everyone wants to have such a thing installed on the calculator, hence the limited builds.
PicoC is not especially fast, but definitely fast enough for many applications. It is also riddled with bugs, and even things as simple as the scope of variables appear to have bugs. Adding the differences between PicoC and the C90 standard it aims to run, expecting to write C code with the same kind of ease (if it was ever easy, especially after using newer C standards or C++) as when using a fully featured compiler is certainly unrealistic. Still, I hope my PicoC port will constitute an interesting alternative to the never-finished LuaZM and to the Casio BASIC interpreter that comes with the OS.
Regarding the other changes seen on the video, there’s the rearrangement of menus on the home screen. The tools menu now hosts a balance manager, with support for multiple wallets, and it will also host a password generator. The old tools menu has been moved to the “Memory & System” menu on the F5 key.
That’s nice and all, but for when?
I don’t have an answer to that. With v1.5 I would like to include even more features than what I have added so far, namely a proper text editor. Such an editor is being developed by ProgrammerNerd / ComputerNerd, who, just like me, doesn’t always have much free time to work on such things. So I’m patiently waiting, and you should too. Meanwhile, feel free to ask any questions, request features (please be reasonable, and I don’t promise anything) or request development builds for a sneak peek.
January 28, 2015 / gbl08ma / 2 Comments
During the past year, the WebView vulnerability(ies) in Android have been making the rounds in various technology-focused websites. More recently, another WebView vulnerability was discovered, affecting versions 4.3 and below of the popular mobile OS (or roughly 60% of the users). Three days ago, HotHardware released a piece on why Google will not patch this vulnerability on 4.3, let alone older versions.
As a quick reminder, Android 4.3, the last version of the Jelly Bean series of releases was launched on July 24th 2013 and its last point release (4.3.1) on October that year. That was 15 months ago. A device that shipped with this Android version was the second-generation Nexus 7, which is still under warranty on places where two-year warranty is mandatory, like in the EU. The Nexus 7, being a flagship Android device from Google, received updates to more recent Android versions; the same can’t be said about most other devices released with 4.3 or earlier.
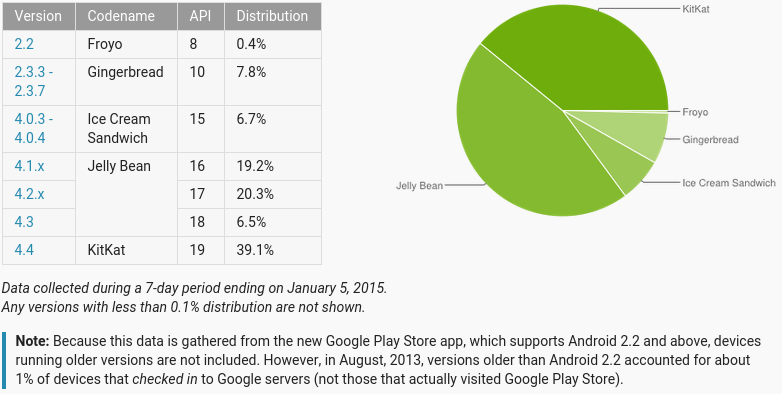
Those 60% sure would like to be in the 39%.
Most of the discussion so far has been centered around whether the responsibility to patch older Android versions and/or push new ones to phones is on Google’s side or on the manufacturers’ side, or if the problem really is with the carriers, which won’t update their customized builds of the OS. There’s also the line of discussion that says such responsibility does not exist, because the problem is fixed in the latest Android version, and anyway, For God’s sake, are you still using a phone that came out six months ago? So vintage. Oh wait, how are you not using a high-end phone from <insert major brand>? (and even high-end phones sometimes don’t get updates past the next major release)
I would like to shine light on another side of the problem: the fact that smartphones, tablets and devices alike can’t be updated by the user software-wise. In fact, it’s not just the user who can’t update or choose to run a different operating system: I’m convinced that for the most part, if the manufacturers wanted to update their Android systems to a more recent OS version, or switch to, say, Windows Phone or Firefox OS, they would have much trouble themselves. And I pinpoint this down to two different but related issues, the lack of a proper drivers system on Android (possibly involving Linux) and the multitude of ways these devices boot their OS, expect updates and do basic hardware communication. Both issues are related to a bigger problem: the lack of standards in the world of embedded consumer electronics.
In this text I’m letting aside all the arguments regarding “open source vs. closed source”, “walled garden vs. open garden”, “but but binary blobs!”, etc. Both theory and practice have evidence that these debacles and inconveniences don’t matter, or there are ways to work around them that are successfully used in practice. The only “inconvenience” that might remain, is the hardware manufacturers’ wish for people to replace their “old” devices every six months or so. This turns out to be a game of extortion made for those who worry about their security: “if you want a OS patched against this horrible vulnerability, just buy a new device that won’t do much more than your current one, but will have that single line of code changed”.
In a perfect world though, manufacturers which wanted to play that game would have to do it in the clear, by explicitly locking their devices (as most already do) and announcing on the box that there will be no updates, fixes or warranties software-wise. (Curiously, the texts that say such things are usually free-as-in-beer software licenses, not software you pay for in the form of hardware). But letting aside the utopia and focusing on the two standards-related issues I mentioned before.
I said Android doesn’t have a proper drivers system. This statement can be taken as incorrect, because, after all, Linux is the part of the stack responsible for driving the hardware. But while Linux is not Android, Android definitely includes Linux, and their creators and maintainers make a deliberate choice to use this kernel. I’m not saying it’s a bad choice, well on the contrary – only Linux and a few other Unix-like kernels could scale down and adapt to the hardware and ARM architecture used in most handheld consumer devices.
Using Linux is taking a giant shortcut (again, that isn’t bad – reusing is good). Microsoft, for things like the (abandoned) Windows RT and Windows Phone, besides porting some of the upper layers of the Windows stack and developing new ones, also had to do additional work to get the NT kernel to run on such hardware. It’s worth mentioning that despite that effort, Windows Phone 8+ has hardware requirements higher than those of Android (comparing versions released in the same time span, please correct me if I’m wrong).
Going back to the drivers, many people say the big roadblock to making new Android releases run on (relatively) old hardware is the binary blobs, the closed-source drivers that control much of the hardware in those embedded systems. Now, a bit of anecdotal evidence: I use proprietary drivers from at least Nvidia and Broadcom on the Linux install on my laptop, and these have survived fine upgrades from Linux Mint 15 to 17, and multiple Linux kernel updates from at least 3.8.8 to 3.14.27. This is because the proprietary part is well separated from the things that can possibly change between kernel versions, and there are clear update paths defined.
Of course it helps if the maker of the proprietary drivers is interested in having their drivers run in newer operating system versions, but if all drivers were properly developed and not added into the system as ugly kernel patches (or should I say, “hacks”?) for which nobody has the source, as I’ve seen System-on-Chip manufacturers do (looking at you, Mediatek, Realtek, …), the problems would be mostly gone. The practice of doing such ugly source editing is one of the reasons I say that even if manufacturers wanted to, they couldn’t switch to another OS or update to more recent Android versions. I suspect that at some companies, just a few months after devices ship, even high-end ones, entire source trees, complete git repos, are rm -r-ed out of every system. Nowhere does the GNU GPL say that it’s not a violation of the license if you get rid of the source, does it? As if such license was ever read by said people…
There is another “entertainment” awaiting those who take the updating matter into their own hands and attempt to port the OS of their liking to their device, which is understanding how the device expects to be updated and how it starts its OS. While this is sometimes just a case of watching updater software do its job (that is, when an update is even available), often additional steps are needed, and this is where one finds out that most devices use U-Boot, but often it’s even more patched than the Linux kernel, and again, source code is nowhere to be seen. There is then a myriad of ways to boot the kernel and from there to starting userspace, and fortunately this is more or less constant between Android devices. Still, undocumented quirks are everywhere, and one basically has to work with each device on an individual basis. The same model has various versions? Great, expect to repeat that work for each version.

These all have a color screen, a speaker, a microphone, some buttons, and can make calls. It’s 2015, standards exist, they must be really similar, right? Yes, as long as you don’t attempt to change their OS…
And finally, we get to what I personally think is the core of the issue: each device is too much of an individual situation, and work must be done for each device. It’s been like this since, well, ever – for well more than a decade, since what can be called the first smartphone was launched (HTC Wallaby). In the beginning, I think this was justified – the hardware was not very powerful to be able to handle complex software abstractions and advanced boot methods, nor did software advance at today’s pace. Consumer handhelds were also not as ubiquitous as today. We can compare this to the evolution of the Personal Computer, where in the end everyone settled around the IBM PC standard. A corresponding standard for the smartphones and tablets everyone has is yet to be found – such a standard is what enables one to buy almost any computer off the shelf and install a different OS in it, or a different version of the same OS. It would also allow for buying devices without OS preloaded. This means the user would be able to control its user experience and security. I would no longer have to buy a new phone to stay safe, just because (and this would happen inevitably – no software is bug-free) a vulnerability was found in Android 4.2.
Sure, despite the PC standards, there are computers in the market which come as locked down as today’s tablets and smartphones. And there is no problem with that, as long as such locked-down things are not the only option. When locked-down is the only option, or unlocked options are prohibitively expensive, there is little room for innovation, consumers end up not having much to choose from, and eventually, no way to have durable hardware, if all the available alternatives support the “update the hardware to update the software” scheme.
Even in today’s context, there are better ways to ensure operating systems keep up-to-date in terms of security, without exactly requiring a change to another version. Google should look a bit more into Microsoft, which got one thing right on Windows for over ten years: Windows Update. Microsoft ensures support for a specified number of years for its OS, independently of the hardware it runs on; this is something consumers like and enterprises love. Google seems to have learned, so much that it is moving a lot of things that were previously built into Android to Google Play Services, a component that can be updated through the Play Store like other apps. Unfortunately, this means making more and more of the OS closed-source, but that’s another subject. Personally, I would rather pay, say, 10 to 20% of the original price of my phone with each update, than having to buy a new phone when I definitely don’t need one except for the bits executing in its CPU which all of a sudden are “old” and insecure.
I believe an update scheme a-la-Microsoft would be profitable for Google and let them have a bigger market share in the enterprise. (Actually, if Google is taking any of that market share, is because of the “cloud! factor” and because enterprises are moving to Google’s systems as “it’s what everyone uses”, and not because it fits their needs better). It could be perceived as terrible for hardware manufacturers, because there would be one less reason to buy new devices, and let’s not forget Google also sells hardware. Apple sells hardware too, and people happily run Windows, Linux or whatever on their Macs and MacBooks, and I doubt Apple has lost any business because of that: well on the contrary. It shows the two things don’t need to be exclusive. Apple still manages to sell a lot of Macs and people who want to stay with an older machine still enjoy updates for much longer. In their line of consumer handhelds, while it is perceived as being even more locked down than the competition, each model tends to get at least two major OS updates (for free!), making people who aren’t in an “upgrade cycle” happier.
I am actually surprised and annoyed that consumer rights associations don’t complain more about the situation. It seems that certain companies were successful in sinking into people’s minds the idea that in the case of phones, tablets, smart watches, etc. the software can’t be decoupled from the hardware. In fact, in its current state, it’s really hard to decouple it, but it’s because that’s what manufacturers want, not because of technical obstacles. Perhaps this thinking comes from the fact that, after all, the introduction of smartphones and tablets to the general public was done by Apple, which presented their vertically-integrated walled-garden first and foremost, and giving everyone else the idea that was the only way these devices would ever be successful.
To finish, another anecdote. I have bought a cheap unknown-brand tablet with a x86-64 Intel CPU. It runs full Windows 8.1 and is fully up-to-date thanks to Windows Update; I’m very happy with it. When Windows 10 comes out I plan to install it; either the upgrade is as easy as from 8 to 8.1, or I’ll install it manually by connecting a USB stick and using the UEFI. As we know, Windows is closed-source, and drivers are nothing more than closed-source “binary blobs”. Still, I know I’ll be able to install most if not all of these drivers in Windows 10, to a point where I can use that version of Windows on the hardware I have now. Perhaps I’ll need to throw some money at Microsoft to have Windows 10, if that idea of giving it for free to users of 8.1 and 7 turns out to not apply to me. Had I bought an Android tablet, I could throw money at Google and at the manufacturer, and I’m sure that after a year or so, neither would put a single update out for the hardware. The money would have rendered a new piece of hardware, yes… but of how much use is another piece of plastic and silicon, when the previous one works perfectly? They sure like to contribute to e-waste.
Related question: are there any phones running full x86 Windows? Perhaps once Windows 10 comes out?