January 31, 2015 / gbl08ma / 0 Comments
On 24th June last year, Version 1.4 of my Utilities add-in for the Casio Prizm calculators was released. The plan was for this to be final release of said software, with any further versions being bug-fixing only, and because of this, it was even more thoroughly tested than previous stable releases.
Ironically enough, an apparently innocent code optimization, introduced at a late development stage, introduced a bug in the Tasks functionality of the add-in, where a reference to a nonexistent memory object may happen when there are no tasks. At this point, I was more or less tired of the Casio Prizm platform, because of the many issues I have described throughout the years, and which the homebrew development community is yet to fully solve. However, as time went by, occasionally I’d look into my Prizm projects and I’d inevitably end up optimizing yet another function, or adding another small functionality.
This, plus the desire to iron out some edges, led to the discovery of another bug, this time in the calendar search function. After lengthy debugging sessions it turned out to be a buffer overflow issue that could happen when reading malformed calendar database entries. Fixes for these and other bugs, plus the functionality I added as I had time and will, made it clear that releasing a new version of Utilities was imperative. I often ask myself if continuing the development of such project is still worth it, since:
- I use my Prizm much, much less than I used to (finishing high school marked the end of the period in my life where graphic calculators were needed for education);
- The community of users of these calculators was never very big, and keeps on shrinking. Of the people who go on online communities dedicated to these calculators, some lost interest on the device, and others lost the device to a brick, for which nobody is able to pinpoint a certain cause. Taking into account the results of my survey so far, the intersection between the group of people who own a Prizm and the group of people who search for software for it, seems to be contain no more than 50 people;
- Of the people who remain in the communities, most never paid much attention to Utilities (due to feature creep, it’s likely that most people never understood its power) and the amount of users that still pay attention has reduced too (as well as their attention span for it).

Apparently, at least one hundred thousand of these devices are produced every month, but the amount of users who know they can run extra software in them, is in the order of the few dozens.
Despite all this, such questions are promptly answered by the fact that I still have fun developing it, even if nobody gets to use my work. And so development progresses, albeit at a much more relaxed rhythm, firstly because v1.4 is still very stable (at least, no one complained), and secondly because there is no roadmap to v1.5 nor planned release date. Heck, if I wanted to, I could not release it, and zero people would complain… but perhaps not after seeing what’s coming.
On the video below (without sound), I show a small subset of the new functionality for v1.5 (if it ever gets released, heh heh). The part that, in my opinion, is going to leave the mouths of some people open, starts at 3:30. It is an elaborate method to allow people to extend Utilities to a certain point, by having an easy way to use the big amount of utility functions used internally, as well as the nice GUI methods I developed. As if this wasn’t enough, one still gets access to most known syscalls (those that involve function pointers being the notable omission). What’s presented is, after all, the most powerful scripting engine ever made to run on the Prizm, and because of this one gets goodies like on-calculator development.
As hinted in the video, “PicoC script execution available on select builds only”. Starting with version 1.5 of Utilities, there will be two public builds made available: the normal one, with the now usual feature set plus the added features but without PicoC, and another with all that plus PicoC support enabled. The reason for this, is that such support increases the size of the add-in by at least 60 KiB, and as can be seen in the video above, the scripts have (almost) full reign on the machine, including read/write access to the whole address space (in the video, you can see a script changing the function key color, and while it’s not depicted, it also locks and unlocks Main Menu access). This means that a script can definitely brick a calculator on purpose, and do all the sorts of nasty (and good) things an add-in can do, except use syscalls with function pointers (the reason being, that PicoC doesn’t support them). It’s understandable that not everyone wants to have such a thing installed on the calculator, hence the limited builds.
PicoC is not especially fast, but definitely fast enough for many applications. It is also riddled with bugs, and even things as simple as the scope of variables appear to have bugs. Adding the differences between PicoC and the C90 standard it aims to run, expecting to write C code with the same kind of ease (if it was ever easy, especially after using newer C standards or C++) as when using a fully featured compiler is certainly unrealistic. Still, I hope my PicoC port will constitute an interesting alternative to the never-finished LuaZM and to the Casio BASIC interpreter that comes with the OS.
Regarding the other changes seen on the video, there’s the rearrangement of menus on the home screen. The tools menu now hosts a balance manager, with support for multiple wallets, and it will also host a password generator. The old tools menu has been moved to the “Memory & System” menu on the F5 key.
That’s nice and all, but for when?
I don’t have an answer to that. With v1.5 I would like to include even more features than what I have added so far, namely a proper text editor. Such an editor is being developed by ProgrammerNerd / ComputerNerd, who, just like me, doesn’t always have much free time to work on such things. So I’m patiently waiting, and you should too. Meanwhile, feel free to ask any questions, request features (please be reasonable, and I don’t promise anything) or request development builds for a sneak peek.
January 28, 2015 / gbl08ma / 2 Comments
During the past year, the WebView vulnerability(ies) in Android have been making the rounds in various technology-focused websites. More recently, another WebView vulnerability was discovered, affecting versions 4.3 and below of the popular mobile OS (or roughly 60% of the users). Three days ago, HotHardware released a piece on why Google will not patch this vulnerability on 4.3, let alone older versions.
As a quick reminder, Android 4.3, the last version of the Jelly Bean series of releases was launched on July 24th 2013 and its last point release (4.3.1) on October that year. That was 15 months ago. A device that shipped with this Android version was the second-generation Nexus 7, which is still under warranty on places where two-year warranty is mandatory, like in the EU. The Nexus 7, being a flagship Android device from Google, received updates to more recent Android versions; the same can’t be said about most other devices released with 4.3 or earlier.
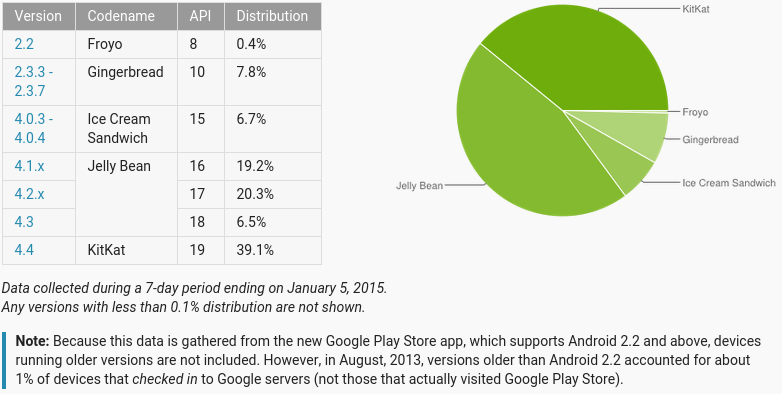
Those 60% sure would like to be in the 39%.
Most of the discussion so far has been centered around whether the responsibility to patch older Android versions and/or push new ones to phones is on Google’s side or on the manufacturers’ side, or if the problem really is with the carriers, which won’t update their customized builds of the OS. There’s also the line of discussion that says such responsibility does not exist, because the problem is fixed in the latest Android version, and anyway, For God’s sake, are you still using a phone that came out six months ago? So vintage. Oh wait, how are you not using a high-end phone from <insert major brand>? (and even high-end phones sometimes don’t get updates past the next major release)
I would like to shine light on another side of the problem: the fact that smartphones, tablets and devices alike can’t be updated by the user software-wise. In fact, it’s not just the user who can’t update or choose to run a different operating system: I’m convinced that for the most part, if the manufacturers wanted to update their Android systems to a more recent OS version, or switch to, say, Windows Phone or Firefox OS, they would have much trouble themselves. And I pinpoint this down to two different but related issues, the lack of a proper drivers system on Android (possibly involving Linux) and the multitude of ways these devices boot their OS, expect updates and do basic hardware communication. Both issues are related to a bigger problem: the lack of standards in the world of embedded consumer electronics.
In this text I’m letting aside all the arguments regarding “open source vs. closed source”, “walled garden vs. open garden”, “but but binary blobs!”, etc. Both theory and practice have evidence that these debacles and inconveniences don’t matter, or there are ways to work around them that are successfully used in practice. The only “inconvenience” that might remain, is the hardware manufacturers’ wish for people to replace their “old” devices every six months or so. This turns out to be a game of extortion made for those who worry about their security: “if you want a OS patched against this horrible vulnerability, just buy a new device that won’t do much more than your current one, but will have that single line of code changed”.
In a perfect world though, manufacturers which wanted to play that game would have to do it in the clear, by explicitly locking their devices (as most already do) and announcing on the box that there will be no updates, fixes or warranties software-wise. (Curiously, the texts that say such things are usually free-as-in-beer software licenses, not software you pay for in the form of hardware). But letting aside the utopia and focusing on the two standards-related issues I mentioned before.
I said Android doesn’t have a proper drivers system. This statement can be taken as incorrect, because, after all, Linux is the part of the stack responsible for driving the hardware. But while Linux is not Android, Android definitely includes Linux, and their creators and maintainers make a deliberate choice to use this kernel. I’m not saying it’s a bad choice, well on the contrary – only Linux and a few other Unix-like kernels could scale down and adapt to the hardware and ARM architecture used in most handheld consumer devices.
Using Linux is taking a giant shortcut (again, that isn’t bad – reusing is good). Microsoft, for things like the (abandoned) Windows RT and Windows Phone, besides porting some of the upper layers of the Windows stack and developing new ones, also had to do additional work to get the NT kernel to run on such hardware. It’s worth mentioning that despite that effort, Windows Phone 8+ has hardware requirements higher than those of Android (comparing versions released in the same time span, please correct me if I’m wrong).
Going back to the drivers, many people say the big roadblock to making new Android releases run on (relatively) old hardware is the binary blobs, the closed-source drivers that control much of the hardware in those embedded systems. Now, a bit of anecdotal evidence: I use proprietary drivers from at least Nvidia and Broadcom on the Linux install on my laptop, and these have survived fine upgrades from Linux Mint 15 to 17, and multiple Linux kernel updates from at least 3.8.8 to 3.14.27. This is because the proprietary part is well separated from the things that can possibly change between kernel versions, and there are clear update paths defined.
Of course it helps if the maker of the proprietary drivers is interested in having their drivers run in newer operating system versions, but if all drivers were properly developed and not added into the system as ugly kernel patches (or should I say, “hacks”?) for which nobody has the source, as I’ve seen System-on-Chip manufacturers do (looking at you, Mediatek, Realtek, …), the problems would be mostly gone. The practice of doing such ugly source editing is one of the reasons I say that even if manufacturers wanted to, they couldn’t switch to another OS or update to more recent Android versions. I suspect that at some companies, just a few months after devices ship, even high-end ones, entire source trees, complete git repos, are rm -r-ed out of every system. Nowhere does the GNU GPL say that it’s not a violation of the license if you get rid of the source, does it? As if such license was ever read by said people…
There is another “entertainment” awaiting those who take the updating matter into their own hands and attempt to port the OS of their liking to their device, which is understanding how the device expects to be updated and how it starts its OS. While this is sometimes just a case of watching updater software do its job (that is, when an update is even available), often additional steps are needed, and this is where one finds out that most devices use U-Boot, but often it’s even more patched than the Linux kernel, and again, source code is nowhere to be seen. There is then a myriad of ways to boot the kernel and from there to starting userspace, and fortunately this is more or less constant between Android devices. Still, undocumented quirks are everywhere, and one basically has to work with each device on an individual basis. The same model has various versions? Great, expect to repeat that work for each version.

These all have a color screen, a speaker, a microphone, some buttons, and can make calls. It’s 2015, standards exist, they must be really similar, right? Yes, as long as you don’t attempt to change their OS…
And finally, we get to what I personally think is the core of the issue: each device is too much of an individual situation, and work must be done for each device. It’s been like this since, well, ever – for well more than a decade, since what can be called the first smartphone was launched (HTC Wallaby). In the beginning, I think this was justified – the hardware was not very powerful to be able to handle complex software abstractions and advanced boot methods, nor did software advance at today’s pace. Consumer handhelds were also not as ubiquitous as today. We can compare this to the evolution of the Personal Computer, where in the end everyone settled around the IBM PC standard. A corresponding standard for the smartphones and tablets everyone has is yet to be found – such a standard is what enables one to buy almost any computer off the shelf and install a different OS in it, or a different version of the same OS. It would also allow for buying devices without OS preloaded. This means the user would be able to control its user experience and security. I would no longer have to buy a new phone to stay safe, just because (and this would happen inevitably – no software is bug-free) a vulnerability was found in Android 4.2.
Sure, despite the PC standards, there are computers in the market which come as locked down as today’s tablets and smartphones. And there is no problem with that, as long as such locked-down things are not the only option. When locked-down is the only option, or unlocked options are prohibitively expensive, there is little room for innovation, consumers end up not having much to choose from, and eventually, no way to have durable hardware, if all the available alternatives support the “update the hardware to update the software” scheme.
Even in today’s context, there are better ways to ensure operating systems keep up-to-date in terms of security, without exactly requiring a change to another version. Google should look a bit more into Microsoft, which got one thing right on Windows for over ten years: Windows Update. Microsoft ensures support for a specified number of years for its OS, independently of the hardware it runs on; this is something consumers like and enterprises love. Google seems to have learned, so much that it is moving a lot of things that were previously built into Android to Google Play Services, a component that can be updated through the Play Store like other apps. Unfortunately, this means making more and more of the OS closed-source, but that’s another subject. Personally, I would rather pay, say, 10 to 20% of the original price of my phone with each update, than having to buy a new phone when I definitely don’t need one except for the bits executing in its CPU which all of a sudden are “old” and insecure.
I believe an update scheme a-la-Microsoft would be profitable for Google and let them have a bigger market share in the enterprise. (Actually, if Google is taking any of that market share, is because of the “cloud! factor” and because enterprises are moving to Google’s systems as “it’s what everyone uses”, and not because it fits their needs better). It could be perceived as terrible for hardware manufacturers, because there would be one less reason to buy new devices, and let’s not forget Google also sells hardware. Apple sells hardware too, and people happily run Windows, Linux or whatever on their Macs and MacBooks, and I doubt Apple has lost any business because of that: well on the contrary. It shows the two things don’t need to be exclusive. Apple still manages to sell a lot of Macs and people who want to stay with an older machine still enjoy updates for much longer. In their line of consumer handhelds, while it is perceived as being even more locked down than the competition, each model tends to get at least two major OS updates (for free!), making people who aren’t in an “upgrade cycle” happier.
I am actually surprised and annoyed that consumer rights associations don’t complain more about the situation. It seems that certain companies were successful in sinking into people’s minds the idea that in the case of phones, tablets, smart watches, etc. the software can’t be decoupled from the hardware. In fact, in its current state, it’s really hard to decouple it, but it’s because that’s what manufacturers want, not because of technical obstacles. Perhaps this thinking comes from the fact that, after all, the introduction of smartphones and tablets to the general public was done by Apple, which presented their vertically-integrated walled-garden first and foremost, and giving everyone else the idea that was the only way these devices would ever be successful.
To finish, another anecdote. I have bought a cheap unknown-brand tablet with a x86-64 Intel CPU. It runs full Windows 8.1 and is fully up-to-date thanks to Windows Update; I’m very happy with it. When Windows 10 comes out I plan to install it; either the upgrade is as easy as from 8 to 8.1, or I’ll install it manually by connecting a USB stick and using the UEFI. As we know, Windows is closed-source, and drivers are nothing more than closed-source “binary blobs”. Still, I know I’ll be able to install most if not all of these drivers in Windows 10, to a point where I can use that version of Windows on the hardware I have now. Perhaps I’ll need to throw some money at Microsoft to have Windows 10, if that idea of giving it for free to users of 8.1 and 7 turns out to not apply to me. Had I bought an Android tablet, I could throw money at Google and at the manufacturer, and I’m sure that after a year or so, neither would put a single update out for the hardware. The money would have rendered a new piece of hardware, yes… but of how much use is another piece of plastic and silicon, when the previous one works perfectly? They sure like to contribute to e-waste.
Related question: are there any phones running full x86 Windows? Perhaps once Windows 10 comes out?
September 29, 2014 / gbl08ma / 1 Comment
My previous post on this blog was published by the end of the long-gone month of June. Many things have changed since then, for example, I entered university and was pressed into creating a Facebook account (more or less separate from the rest of my online presence, so don’t look for me, I won’t add you). On that post, I rambled about the recovery from a big server outage that costed 42 hours of tny.im downtime, and over one week of server downtime. I learned my lessons (I doubt BlueVM learned theirs, but that’s a whole other story), and I went forward with what I said I would do: “setting up a new advanced and redundant system” for ensuring tny.im is always up.
That system has been up and running for over two months now, with varying amounts of servers making the redundancy and load balancing, and a plethora of occasional hiccups. Right now it’s composed of three virtual servers (all from different providers…), but there were times when it was composed of five servers. These three servers are paid, and while they aren’t exactly expensive (but not the cheapest, either), you can imagine the bill, so let’s not talk about tny.im profitability now, OK? (I have kind of given up).
In the spirit of the great statisticians of our time, here’s a graph without title, labels or axis.
However, having three servers serving the same website, with all three of them being almost a clone of each other (which means, all have the same files and database contents, synced), in a DNS round-robin setup doesn’t directly lead to greater uptime. In fact, I have found out it can lead to more outages, since now the total downtime is approximately the sum of the downtime of each server. Of course, most of these outages are partial (as in, only users unlucky enough to have their DNS request resolved to the IP of a server that is down, will actually perceive the site as down), except for when the MariaDB replication freaks out and basically grinds all database operations, on all servers, to a halt, requiring a complicated manual restart of all MariaDB instances, in a specific order (yes, I have spent many hours searching for an alternative database system, and couldn’t find any that met my requirements).
In order to actually achieve greater uptime, one must have a system that automatically manages the DNS records so that the domain(s) of the website in question never have any records pointing to servers that are down. In other words, the “sheep” must be “hidden from sight” as soon as they go “bad”, and should be put back “in stage” once they become “good”. Being DNS something that was definitely not made for real-time record edits, with many systems caching DNS request results well beyond the specified TTL, this system obviously doesn’t ensure that the “bad sheep” are not invisible to everyone watching the show. But if it manages to do it for even a small percentage of the public, it’s already better than not hiding from anyone (and especially, if it successfully hides the problem from the uptime monitor, that’s even better 🙂 ). This explains why the DNS records for tny.im are set with TTLs of five minutes.
The development of such a DNS record management system was also more or less contemplated in my previous post, when I say:
I’ll take this downtime and new server acquisition as the motivation for setting up a new advanced and redundant system, so that if one server goes down, tny.im (and possibly this blog too) will continue to operate as normal.
And in the end, in a later edit:
On related news, Mirasm – the Tiny Server Redundancy Manager – is mostly finished, only needs some more testing to be put on production servers, managing the new tny.im redundancy system.
“Mostly finished”, as we all know, really means “It’s 99% ready, I only need to figure out the remaining 1% that consists on… everything that is tricky and I’m not sure how it’s done”. This is specially true in this case, as I had high requirements for my manager: it couldn’t use any resources other than the servers I had already (it would’ve been easy to have a separate server just for monitoring and editing DNS as needed, but I didn’t want to pay for yet another server on yet another provider), and it couldn’t fail more than tny.im itself. In fact, the time when the manager has to do more important work, is when it is not working, i.e. when a server goes down and so goes the manager. I finally finished the project, and it works as planned. I only got the name wrong…
Introducing mersit, a Tiny Server Redundancy Manager
Pronounced “m-eh-rs-ee-t”, with the first “e” being like the one in “explain”, mersit is a simple Python script (Python 2.7, because I wasn’t sure what libraries were available for 3.x nor if my servers would run it well) hacked together with some sections that definitely look like spaghetti code. The good news is, it works fine, and has been well tested, so if you study it in the “black box” way, there are no big problems with it.
The purpose of the script is to manage the DNS records of the website served by the group of synced servers, in this case, tny.im. It runs on each server, in a peer-to-peer fashion. The peers select a single master, that will monitor all the peers and manage the DNS as they go up and down, “deciding who’s on stage”, and all peers will check whether the master is up, and select a new one that will edit the DNS to “hide the master from the public” when it goes down.
I definitely want to open-source mersit at some point, but not now because it’s not ready for prime-time (see “spaghetti code”, above), and I want to change some things that will make it more general-purpose. mersit has been managing the live records for tny.im for the past week (it’s been peaceful).

Continuing our journey through the world of meaningful graphs, here’s another.
I have gone so far as to write a read-me for mersit (mainly for me to read, as I know I’ll forget how it works within six months). I think it’s best if I put the start of the read-me here, instead of trying to explain it all, once again:
mersit - Tiny Redundant Server Manager
Copyright 2014 tny. internet media
This version is customized for tny.im
This is a Python 2 script that manages a group of computers/servers/thin clients/machines in a network (local- or wide-area), by automatically executing actions when something relevant happens to one of the machines.
We'll call the "machines" "peers". mersit assumes all peers and the network are trusted.
The script is meant to be run directly on the peers that are to be controlled, in a setup where there is not a single point of failure. It is not of much use when run in a single peer; in the context of this script, a "group" only starts to make sense when it has over one element.
We'll refer to this script as "controller software" or simply "controller", and to the other software that runs on a peer and which is to be monitored as "application". The controller is made to run unattended, even though it accepts commands (issued by an "operator") to trigger certain behavior manually.
The "something relevant" mentioned in the first paragraph consists on one of these "events of interest":
- A peer goes "online", that is, it is reachable by other peers and reports the status of its controller software as "OK" or "ready";
- A peer goes "offline", that is, it is either not reachable by at least some peers, or the controller is reporting its state as "not good" or "not ready";
- A peer becomes good-for-work (GFW), which means, that the application is functioning properly and performing its function (such as listening for incoming connections, data to process, etc.);
- A peer becomes not-good-for-work (NFW), in which case the application is not functioning properly, is too busy to perform its function (over capacity), or is otherwise unavailable.
Each peer works in a given "domain", which is the group the peer belongs to. The domain is specified by a name and secret which act basically like a username and password pair. Peers will only communicate with other peers of the same domain, that is, peers where the domain name and secret are the ones the controller is configured to use. The domain acts as the authentication element; an external party can not join, communicate or perform actions in a domain unless it knows the name and password used by the peers of the domain.
(Please note, that communication between peers is not encrypted by the controller - it goes completely plain-text over the network. It is possible to secure the communication between peers using external tools; such secure functionality goes beyond the scope of this software. The "domain" is simply a basic authentication system, implemented using HTTP authentication, to ensure that peers of a certain group don't start talking with peers from other groups. The basic authentication system is enough to protect against the casual script-kiddie, but by no means adequate for protection from a malicious party in an untrusted/open network)
The controller on each peer must know _a priori_ (i.e. before it starts) about where to find at least some of the controllers on other peers. Peer discovery doesn't happen automatically, however, once a peer's controller can communicate with another controller, it will add every controller in the "contact list" of the latter to its "contact list".
Imagine the following situation: you have peers A, B and C (and their controller software). The controller in A only knows about peer B. The controller in B only knows about peer C. If you start the controller on peer A, then start the controller on peer B, peer A will tell peer B about its existence, and peer B will tell peer A about the existence of a peer C (independently of peer C being running/reachable). However, if the controller in A knew about no peer (other than itself), it would never find peer B or C even if their domain settings all matched. Even though a big domain can be bootstrapped from just two peers, to ensure good operation, all controllers should know about all peers. This way, if the controller on a peer resets for some reason, it will have a greater chance of reaching another peer.
The "contact list" is the list of "known" peers. The controller keeps three lists of peers in memory: the "known" peers, the "reachable" peers, and the "GFW" (good-for-work) peers. The list of known peers is initialized from the source code's configuration section when the controller starts. It then proceeds to see which peers are "reachable", that is, can be reached through the network, are in the same domain (not being in the same domain gives the same effect as not being reachable over the network) and have their controller software report its state as "OK".
This initial status checking includes the exchange of some other information about the controller. Once this initial peer identification is done, the controller enters a monitoring loop where it will keep the contents of the three lists up-to-date. The controller keeps running this infinite loop throughout most of its lifetime. How the lists are kept up-to-date and what happens when their contents change is something that depends on the current controller mode.
There are two possible modes for controller operation: master and non-master. There is exactly one controller in master mode per domain, and this controller is usually called "the master" (the master peer has the controller in master mode). The differences between the modes are mostly related to what happens in the monitoring loop, but before going into those differences, it is important to understand how the controllers decide which peer is the master peer.
When a controller starts and there are no reachable peers, it promotes itself to master, since there must be exactly one master per domain. Later, when another controller joins the domain (either because it started or because it went online after e.g. a period without connections or power), it checks which peers are reachable from its "known" list and "asks" them which is the master peer. Every peer should reply with the same peer, in which case the new controller assumes that peer is the master, and informs the master about its existence, to account for the fact that the new peer may not be in the master's "known" list.
However, and especially on domains where not all peers initially know about every other peer, it's possible that a "head split" occurs and there are two masters in the same domain. Imagine a domain where there are four peers D, E, F and G. D only knows about E, which in turn only knows about D. F doesn't know about any peer, and we'll leave G aside for now. All peers are offline.
The D controller starts up, sees it can't reach the only peer it knows (E), so calls itself master. The E controller starts up and reaches D, D says it is the master, E assumes D is master, all is fine.
The F controller starts up, sees it can't reach any peer because its "known" list is empty, so calls itself master and sits quietly waiting for someone to contact it, which in turn would let it know about more peers.
We now have the following situation ([M] represents a controller in master mode, --- represents the knowledge peers have of each other):
-DOMAIN------------------
| |
| D[M]-----E F[M] |
| |
-------------------------
Things could be like this forever, and no conflicts would occur - however, this is probably not a domain you want to have, since F doesn't know about any "event of interest" related to D or E, and these two don't know about any events related to F. In this situation, D--E and F act like separate domains.
Assume that G is a peer which knows about D, E and F, and that its controller starts up, contacting D, E and F. The first two will agree that D is the current master, but F will disagree and say it is the master. At this point we have a conflict. There are many ways to solve this, including some form of "voting" (e.g. the peer the largest amount of the peers say is the master effectively becomes it), but mersit solves this in a simpler way.
The controller checks that everyone in the domain agrees on what peer is the master on every iteration of the monitoring loop. It does this by "asking" each peer in the list of known peers who is the master. The first peer asked is free to reply with any peer. The ones that are asked next must agree with the first one. If not, the controller that was doing the loop tells each disagreeing peer that the actual master, is the one from the first peer's reply. It is possible that a minority is asked first, and thus everyone is forced to "change its opinion" to that of the minority. This is not a problem - mersit assumes all peers are trusted. Note that it can sometimes take some iterations of the monitoring loop for all peers to settle on a single master, because two (or more) peers may be trying to "change the opinion" of the other peers to different masters. This is not a problem either, because even if this kind of concurrency conflict happens once or twice in a row, it will stop happening as soon as one peer is faster than the other to tell everyone (including the other peer(s) that are trying to "change opinions"). What matters is that in the end, every peer knows about all others, and there is a single master. In this case, it could be D:
-DOMAIN--------------------
| |
| D[M]-----E-----F-----G |
| |
---------------------------
If the master becomes unreachable, or its controller stops working, the other peers will also find themselves a new master, by sorting the list of reachable peers alphabetically and choosing the first peer in the sorted list. Of course, if for some reason the list is not consistent across peers, the peers will try to "convince" others to settle on who they "think" is the master as previously explained, until everyone is set to the same master.
Being the master essentially changes what happens in the monitoring loop. When a controller is in master mode, it is responsible for updating the list of "reachable" and "GFW" peers, by checking which peers are reachable (both in terms of network and in terms of functioning controller) and which have the application in a working condition. If there are changes in the lists that indicate an event of interest, it runs the appropriate handler. If, for example, a peer becomes NFW due to a problem in the application, it will stop being in the GFW list, and the handler function for when a peer leaves that list will be run with the peer in question as the argument. If the master becomes unreachable (network error, controller error, etc.), a new master will be found, as explained in the previous paragraph, and the new master is responsible for running the handler with the previous master as argument.
When a peer is not master, it won't run any handlers for events of interest, and it is not responsible for updating the "reachable" and "GFW" lists - it will retrieve these from the master. The controllers on all peers need to keep their lists up-to-date, sharing a "vision of the domain" similar to that of the master, so that any peer can become a master instantly in case of necessity, without having to spend time performing checks on all peers and ensuring it has the best-and-latest list of "known" peers.
The operator can manually tell a controller to become the domain's master. When the appropriate command is issued, the controller will send a command to every other controller instructing them to switch to the new master. This command may not always have an effect in some controllers, because while the first controller is sending the commands, other controllers are seeing if everyone agrees on who's the master, and issuing the same commands with another master in mind. This is a sequence of events picturing the situation, in a domain where there are three peers H, I and J, and H is the initial master:
0. ...
1. Peer H checks that every controller agrees it is the master (all agree);
2. Peer I checks that every controller agrees H is the master (all agree);
3. Peer J checks that every controller agrees H is the master (all agree);
4. Operator issues command for peer I to become master;
5. Controller on I assumes it is master, starts sending commands to other peers;
6. Peer H checks that every controller agrees it is the master, before the message from I that I is the new master can get to H;
7. Peer H finds out I (and possibly others) don't agree, sends them commands to change the master back to H;
8. Peer I changes master back to H;
9. Peer I checks that every controller agrees H is the master (all agree);
10. Peer J checks that every controller agrees H is the master (all agree);
11. ...
If the master doesn't change when the manual command is issued, it's a matter of trying again. Most often, this kind of concurrency problem does not occur, and even when it does, it does no damage. While it is true that mersit could detect this situation and keep issuing commands automatically until the decision takes effect, we chose to not make it this way to allow the human operator finer control.
The primary focus of mersit is to monitor a distributed application. The master checks if the application, or part of the application, running on a certain peer is in working condition by asking that peer's controller about the state of the application it is monitoring. In turn, this controller runs a function, defined by the mersit user in the mersit source code, that should check the application and return True (if application OK) or False (if not). This can involve, for example, making a HTTP request to a HTTP server in that peer to verify it is working. The controller then communicates the status of the application to the master (which may be itself). All this shouldn't take too long, especially when the domain has many servers, as only one peer is asked at a time. If checking the status of the application typically takes over one second, it is best to store the last known status in a variable, and update that state periodically in an asynchronous manner that may be external to the mersit script.
The part related to DNS records is not explained on the read-me, because it is related to the handlers (which each mersit user would customize to the specific needs of the system – as I said, I tried to make it a general-purpose script). Sounds interesting? Feel free to ask questions, or point out problems, in the comments.
March 21, 2014 / gbl08ma / 0 Comments
If you watch other websites, pages and forum threads of mine, you may already know about this, but just to make sure you don’t miss it, v1.3 of Utilities is out. Download or more info.
January 11, 2014 / gbl08ma / 0 Comments
In case you haven’t noticed yet, the version 1.2 of the Utilities add-in for the Casio fx-CG 10 and 20 (known as Prizm) has been released today. More information and download on this page.
Following my announcement on Twitter about the new release, it got retweeted by the official Casio Prizm Twitter account. This is a move without precedents on their part – no 3rd party add-in had ever received the slightest official public recognition. Most likely the social media marketeer retweeted my nice tweet without really knowing what he/she was doing.
However, this had little impact. The tny.im shortlinks you see received less hits by the time they retweeted, than by the time I originally tweeted – despite @CasioPrizm having over the quintuple of followers I have.
November 29, 2013 / gbl08ma / 2 Comments
Note: this was originally published as part of a post on Cemetech.
The status of 3rd-party development (and general user interest) on what is currently Casio’s flagship non-CAS calculator, is disappointing and inglorious, but the user community is not the only guilty of the situation. I would say there is a marketing problem on Casio’s side: the Prizm is only appealing to students and teachers that are already used to Casio calculators. Personally, I know that if it weren’t for the recommendations of my maths teacher (who is a big proponent of these calculators for their ease of use and similar UX across graphic models), I would have bought a non-CAS Nspire instead, or eventually a black-and-white Casio model.
Despite great initial success (first on Omnimaga and then on Cemetech), the Prizm never really caught on with the developers community and I feel it really never caught on with general students, either. While it is true that the Nspire, and more recently the HP Prime, have more powerful hardware, the first also has a more complex system that actively tries to block 3rd-party binary software, and the second does not have the same target market (the HP Prime doesn’t have a non-CAS version). Cemetech seems to have turned more to the TI-84 Plus CSE, but while it doesn’t have the software constraints of the Nspire, it has inferior hardware specs that put it on another league (I guess it had some success on this community because it was similar to “what people were used to”, i.e. the old TI calculators, unlike the Prizm and the Nspires).
Still, and somehow, the Prizm seems to have a notable market share in Asia, but due to different character sets and more, the western and oriental communities don’t communicate much. From what I understand the Prizm seems to be used in China at a higher education level than in the rest of the world.
From my point of view, the marketing done by Casio for the Prizm, was as simple as saying “we were the first to release a full-color graphic calculator, here it is” and running a few contests while the model was new, but without any effort to distinguish themselves from the competition that would come later (and made a much bigger advertising effort in many markets). Even though they were the first to show a calculator with a full-color, high-resolution screen, while simultaneously being allowed on most official exams, I feel they did not fully explore the possibilities of the screen or the OS and hardware behind it, let alone explain them to users.
On the technical side, many aspects of the OS on the Prizm could have been polished (certain things as the Program editor feel really slow at the default clock speed, as do the constant picture decode and redraws when a g3p is shown on the screen, for example in eActivity). Things such as the separation between a “Main Memory” and “Storage Memory”, while familiar to existing users of Casio systems, are metaphors unused on other computer systems and while technically sound (and allowing for backwards compatibility), are inadequate for a great user experience – I know of people who don’t quite understand why they get memory errors on lists, matrices and Basic programs, even though they have plenty of storage memory, and I also know the problem in understanding different memory sections is common to TI calculators. OS updates never (are yet to?) addressed this, but it’s unlikely they’ll ever address it because it would require major technical changes, perhaps even hardware changes (more RAM or dynamic RAM allocation, anyone?) and the development of a platform that’s not akin to anything built by Casio in terms of calculators, which means users would need to relearn it again – if Casio builds something too much different from previous generations, the results might not be positive (look at how the Nspire went on the TI side).
Then Casio moved on to the new Classpad models (which not everyone can buy, because they are not allowed on all the exams, and not everyone needs a CAS calculator on university), and the Prizm was more or less forgotten. While Casio’s offering has some points that stand out from the competition, it has outdated hardware specs when compared to the other CAS calculators.
Casio calculators become “forgotten” not because the manufacturer stops providing support for them (the Prizm just received the 2.00 OS update, and a new official add-in – so things are well on the contrary), but because there is little effort to publicize these updates to their older models. I guess if they don’t move more, it’s because they are selling and working “good enough” for them. Which isn’t a synonym of things being “good enough” for the power user community.
In my opinion, the Casio calculator development community is too spread among many small communities, which have low levels of activity (especially when it comes to the Prizm) and in some ways even alienate from each other, instead of uniting to get things forward. Note that I’m not suggesting the creation of a new community to hold all the 3rd-party Casio development (see xkcd 927), but instead more communication and joint ventures between existing ones, for example in the form of contests. Unfortunately, different ideas and culture seem to make this difficult most of the time, but it would be great if people managed to overcome that in favor of higher goals.
November 26, 2013 / gbl08ma / 0 Comments
Note to self:
By default, Linux Mint brings OpenDNS (which I hate, if not for anything else, for the NXDOMAIN response it gives) as the resolvconf fallback. Deleting /etc/resolvconf/resolv.conf.d/tail as root and then restarting the resolvconf will (re)solve it. Do not waste time trying to figure out where the DNS is being hijacked on your network: the thing is right on your machine, even if you have overridden the DHCP DNS configuration on the network configuration dialogues – out of the box, it will always use OpenDNS if the DNS servers you or DHCP specified, are not available/don’t answer fast enough.
By the way: http://myresolver.info/ helps with debugging DNS issues.
This post brings to an end months of trouble, and me thinking my ISP, to add to the fact that even though my plan is unlimited, severe speed limiting starts at 15 GB of data usage, was also hijacking DNS queries to their own system. Fortunately, looks like it is not the case. At the same time, I’m disappointed with the choice of DNS fallback by the people behind Linux Mint.
September 4, 2013 / gbl08ma / 0 Comments
Every news piece I see about Microsoft buying Nokia, seems to focus on the business side of the things – “was this a good move for Microsoft?”, “was this a good deal for Nokia?”; on the future of Windows (Phone), and on the patent portfolio Microsoft just licensed for 10 years (to me, in practical terms this equates to buying…). But I think everyone is forgetting what Nokia did before the Microsoft partnership involving Windows Phone, more precisely the software that runs on their older phones. What will happen to these pieces of software, some abandoned and others not?
I am not a Nokia user and I haven’t had extensive contact with their hardware or software. I do have some friends with modern Nokia feature-phones and non-WP smartphones, and I know a bit about their experience with them. I have also tested some of Nokia’s experimental/in-development Linux based systems on emulators (yes, Nokia wasn’t just Symbian and WP). That said, I apologize for any wrong facts on this post. I will be using Wikipedia as a (improper) “source” for some things.
Nokia developed, or supported the development, of several embedded operating systems. These ran and run mostly on feature-phones, despite some of them supporting third-party software and having other features that make me label them as a “smartphone with alphanumerical keyboard”. S40 is an example of this, having debuted in 1999 and being used until 2012 (it powers the recent Nokia Asha phones). (source)
Recently, Nokia has also developed Symbian-based systems that run on touchscreen smartphones.


The Nokia 7110 (1999) and the 6300 (2007) are both powered by S40
Then there’s Symbian, which was born not just as a Nokia venture. Symbian, a proper smartphone OS, was born as “a partnership between Ericsson, Nokia, Motorola, and Psion” (source). Nokia used Symbian on most of their earlier smartphones, being the responsible for Symbian’s really high market share, which lasted until the end of 2010.

Nokia N80 (2010), running S60
The S60 platform, first released in 2002, was based on Symbian and during the course of its life, it powered phones with and without touch screens (yet again, cases of smartphones with alphanumerical keyboards). Later in 2010, Symbian^3 was released, to power the Nokia N8. More or less by the same time, Symbian, once made open-source, turned into a licensing-model only.
In February 2011, Nokia announced they were dropping Symbian-based systems in favor of Windows Phone. Later that month, the Nokia 808 PureView, with a 41 (forty one) megapixel camera (just like this newer one), was announced, to officially become the last Symbian smartphone.
Nokia Anna and Symbian/Nokia Belle were released later in 2011 as updates to Symbian^3. Some time between Anna and Belle, Nokia outsourced Symbian support and software development to Accenture, a situation that will stay until 2016. The second feature pack of the Belle update is the latest version of Symbian as of now. Will it be the last? I would say so.

Screenshot of Nokia Belle
Nokia also developed apps and internet services for the later Symbian updates (these included an app store, the Ovi Store). Ovi was the brand for many of these apps and services. Among the Ovi apps, there was Ovi Maps, later renamed to Nokia Maps in 2011 and now called Here. Here runs on many mobile operating systems, not limited to those developed by Nokia, and provides map and traffic services to Windows Phone 8. (source)
From Belle on, it’s what you probably already know – more and more Lumia smartphones powered by Windows Phone. For feature-phones like the 2012 Asha models, Nokia seems to have reverted to S40, not Symbian-based.
And this is the story of Nokia’s moderately successful operating systems more or less known by the common user. But Nokia invested in other projects not so widely known to the general public, but which developers know well. It is the case of the Qt framework, which was developed by Nokia after they bought Trolltech, the original developer. Qt was used in Symbian; a bit after Nokia dropped Symbian, they sold the licensing stuff to Digia, that now owns the Qt trademark and the Qt Project.
Nokia also invested in other OS projects besides S40 and Symbian-based systems. Maemo, an open source software platform intended for smartphones and tablets, was based on Debian Linux. It made its first big appearance in 2009, with version 5, as it powered the Nokia N900. From my point of view, this device had some flaws and ended up being only loved by Linux geeks. But this is my personal opinion, of course. I know I would have liked to own one of these 🙂

Nokia N900 (2009) running Maemo 5 / Fremantle
By February 2010, it was announced Maemo would merge with Moblin, to create MeeGo. Finding the story complicated already? The best (or worst) is yet to come… In September 2011, roughly a year and a half after that merge, the Linux Foundation, which hosted MeeGo at the time, announced it would be terminated in favor of yet another project, Tizen. By the same time, Mer appeared as a fork of MeeGo. A company called Jolla, from Finland, then started cooperating with the Mer project to create the Sailfish OS. Confusing enough?
Basically, from the initial two development efforts (Maemo by Nokia and Moblin by Intel) we walked towards six (and counting) different mobile-oriented Linux-based operating systems, some dead, some dying and others just starting. There doesn’t seem to be much app compatibility between these – other than good old Linux binaries (but that applies to Android too and I’m not talking about that kind of apps), and maybe some HTML5 apps (and of course, all the web pages).
In case you didn’t notice, Nokia (now Microsoft) is obviously not involved in any of the current projects (Tizen, Mer or Sailfish) – it’s just not part of their new strategy (and if for some reason anything Linux was involved in the current strategy, I’m sure Microsoft would dump it ASAP, or at least hide it from the public).
Obviously, as of now, one can’t even speak about the market share of these six mobile OS, without having to use scientific notation with negative exponents and a big amount of small-number guessing. To my eyes, Maemo, despite being old and officially unsupported, seems to have a bigger community (and, I guess, a bigger market share) than any of the other small projects that were born from it and forcibly declared as its successors. Or perhaps, I should say that a big part of the community is still centered around Maemo – even though most of the development actually occurs on the new projects.
Add the six I mentioned, to the count of other newborn mobile OS (Firefox OS, Ubuntu for phones…) and make your bets on which one (or whether any of them) will get a market share we can measure, with a percentage above 1%. Maybe if they all got together and united their efforts… oh wait, refer to “MeeGo” for the expected result. But, I’m getting off-topic…
…or perhaps not so off-topic. Nokia, before Microsoft, and during the course of its handset making history, also developed a bunch of different platforms – S40, Symbian and everything that ran on top of it: S60, Symbian^3, Belle and I may be forgetting some. Not all of these were compatible with one another and they had different user experiences. Now compare this to Apple’s iOS since the first iPhone, or Android since the first phones that ran it. Sure, there were lots of updates to each of these systems, and sometimes the user experience changed a lot, but they never changed names and there was always some kind of data and app compatibility.
Applications one developed for Android 1.6 most likely still work fine in 4.3, even if sporting an outdated user experience. The user experience has changed but progressively, and much of the practice an user gets from using earlier versions is still valid on the latest. On the Nokia side, from S60 onwards, there was some app compatibility (but from what I see, not as good as Android’s or iOS’s), but the constantly changing names and looks confuse consumers.

MeeGo also ran on netbooks, in-vehicle infotainment devices and other embedded systems.
Since the Linux-based Maemo and successors had nothing to do with Symbian, Symbian-based and Linux-based systems always lived in different universes, despite being both made by Nokia for similar devices. And now Windows Phone has nothing to do with either Symbian or Maemo/MeeGo – it’s yet another “ecosystem”. Talk about fragmentation in Android, and I’ll show you all the systems created by Nokia.
Nokia managed to start more mobile OS projects than companies like Microsoft, Apple or Google, and yet didn’t manage to stick with any of them, except maybe Symbian… but even on the Symbian land, there were lots of changes to user experience over the time, and to the end user it definitely didn’t feel like it was the same OS when they bought a new phone.
And now that Nokia is basically Microsoft, users of the multiple platforms that reached the mainstream consumer before Nokia made Windows Phones, are pretty much screwed. Nokia/Microsoft no longer cares about their non-WP phones except for what I call “traditional support” (phone breaks, gets replaced or repaired; security bug is found, gets fixed) – but users expect other types of support for smartphone OS, namely updates (to fix non-critical bugs, for example). And maybe even the traditional support is compromised.
I see a lot of wasted work and money on the Nokia side, investing on things that eventually never went forward because at some point they lost support from Nokia. I even think much of the recent waste over the past two/three years was purposeful (*cough* Stephen Elop *cough*). At the same time, I can see the old Nokia strategy as “not putting all the eggs in the same basket” – they weren’t just committed to Symbian, but also S40 and Maemo/MeeGo, and later Windows Phone. Then they decided to drop all the eggs but S40 and Windows Phone. And now that Microsoft bought Nokia, I believe they are going to drop the S40 egg too.
Ultimately, I believe this isn’t good for the consumer. It loses yet some more mobile OS choice, even if these choices weren’t so popular – at least, they were something different. The choice is more and more between Android, iOS and Windows Phone, and if the currently in-development projects don’t hurry to get on the market to earn some users, they may suffer the same fate as all the other ones that got killed or merged, eventually turning them into abandonware.
August 22, 2013 / gbl08ma / 0 Comments
It would be good if one could go to a store, buy any smartphone or a tablet, and later choose what OS to run on it. Like what happens with desktop and laptop computers, you buy any one of any brand (even Apple!) and you can almost certainly run a OS other than the default on it – some things are taken for granted on a PC, which allows for this kind of freedom of choice.
Sure, you can install custom ROMs on smartphones… now go ahead and buy any one that isn’t popular and see what happens. If there is not a big enough user base most likely there isn’t anyone to develop custom ROMs. And unlike what happens with PCs, there doesn’t seem to be some list of assured features and standards. On personal computers, even on the ones built from OEM parts and no recognizable brand, it’s as simple as setting a boot device that is an OS installation disk. Sure, you need drivers to get the full potential of the hardware. Still, some things Just Work(tm), like PS/2 keyboard and mouse, serial ports, VGA video out (and I don’t mean graphics acceleration) and disk I/O.
Isn’t it about time some sort of standardization starts happening for mobile devices too, both at the hardware (charging connector/method) and software (system booting, basic elements)? The idea would be that simple things like storage I/O, screen (without GPU), touchscreen input (even in single-touch mode) and hardware keys Just Work(tm) because they are really easy to drive by the OS?
Look at something like KolibriOS. It is pretty limited on what it can do on a PC, because of a limited amount of drivers are included, and anyway everything is very simple. But as things are now, there’s no way one could write a KolibriOS that would run on all the phones and tablets the same way Kolibri runs on almost every PC, even with limited functionality.
It’s certainly a distant dream, seeing that even charging connectors are something we are yet to get quite right… all to make big brands happier at the cost of unhappier customers – even if they never noticed they were less happy because of that. </rant>
July 31, 2013 / gbl08ma / 3 Comments
For a long time, I’ve used YOURLS in my URL shortener projects. I have always liked extending it, so that it did something more than just URL shortening. The results of my work have turned, over the past two years, into what tny.im is today.
Until a few days ago, tny.im was running with software based on YOURLS. Yes, “based on YOURLS”. It wasn’t running “on top of” YOURLS. As I added more features to this URL shortener, I found it easier to just modify the core files and add rows to database tables at will. This came with a price: updating YOURLS without losing my modifications and while keeping database compatibility was really hard, requiring me to rewrite all the modifications. To make things even worse, I had modified some of the core files for them to work with the Bootstrap CSS and JS things. The statistics page (yourls-infos.php), which I had also managed to modify to a point where not only it was Bootstrap-themed, but was also the main UI for users to edit short URLs, was a specially hard problem to solve if I was updating YOURLS.
I could have stayed running the 1.5 version of the said script forever. However, it lacked many under-the-hood improvements of the 1.6 versions, and as new versions would be released, it would only become more obsolete. Again, a big problem resided on the link statistics page: it wouldn’t handle links with many clicks properly, because it would use a lot of memory. This bug no longer existed on 1.6, and this was something that kept me thinking I really should update to a newer version.
Another thing that I had heavily modified for tny.im was the public API. I had modified it to not support some methods which would disclose too much information (e.g. long URLs for paid-access links and links which had reached their hit limit), as well as added support for tny.im-specific features like the passcode, hitlimit and Bitcoin related things.
My code for all these things was really ugly. It had been progressively added and changed over the course of two years, had multiple coding styles, multiple indentation styles, multiple bug styles and God-knows-what-else. The fact that I only worked on the project sporadically meant that I often didn’t remember what I had done already, meaning there were giant mistakes like two variables for the same thing. Somehow it all worked, well enough to take to the correct destination over two hundred thousand short URL clicks.
Some days ago, I finally decided it was time to do something. I wanted to add new features to tny.im and future-proof it at the same time, but the code was impossible to maintain – the original core code, mixed with my bad code, made it seem it would inevitably break if I touched it. I knew, from the start, that the proper way to add features to YOURLS was to code plugins – but laziness, convenience and the fact that version 1.5 didn’t offer that many plugin hooks made me modify the core files, as I said above.
I had to start from scratch, doing things in a “staging” vhost that had no communication to the live tny.im website. I started by installing YOURLS on that vhost, on a database separate from the live one, of course. Then I accepted the challenge of trying to implement all the tny.im features, including the Bootstrap theme, without ever touching the core files of YOURLS.
Fortunately, version 1.6 of YOURLS had many more plugin hooks. But I knew I wouldn’t be able to implement every feature as a plugin. Things ended up like this: I consolidated my hackish plugin soup from the old tny.im scripts in a single “tnyim-framework” plugin, and things like the index page UI, link lists/folders, Bitcoin address shortening and “internet toll” features, as well as login/logout (which is separate, and has always been, from YOURLS auth methods) would keep being separate from YOURLS.
Instead of modifying core files like functions.php and functions-html.php to add my code, I put them in a separate tny.im-specific folder. It has it’s own “load-tnyim.php” file, in the style of the “load-yourls.php” file, which loads the necessary variables and files for the tny.im features and UI.
The problem with the statistics page, as well as some modifications I had made on yourls-loader.php, was solved my creating tny.im-specific files that are similar to the YOURLS ones and perform the same functions, but have my modifications. The new statistics page is based on the YOURLS 1.6 one, and it was a hassle to modify to meet the functionality of the old one, that is, Bootstrap-themed, and with that “Manage” tab that allows people to edit links. This was mainly because, as @ozh says, it is an “awful HTML/PHP soup”. Also, it has little to none plugin hooks from what I can see, but even if it had, they would never be enough to allow me to customize it to the point where I did.
Things like link preview, and the API modifications, went in the tnyim-framework plugin. And the reason why I think YOURLS is awesome, is that I managed to change much of the API behavior, adding new return and request fields, as well as obfuscating some, just with plugin hooks.
As for the database, rows specific to tny.im are now kept on their own table. The functions.php on the tny.im folder has methods for adding and editing URLs that handle the tny.im features. It works like this: the code calls my custom methods for adding/editing short links; then, things are added/edited on the normal YOURLS DB table using the core methods, and then my code takes care of the other table which stores things like link hit limit and price (for internet toll links), as well as adding the link to the users’ account when appropriate.
Speaking of user accounts, the data that relates users to the keywords they have access to, is kept also separate from YOURLS tables. Same with the lists of links feature.
Finally I moved the columns of each database table to their correct destination in the new tables – five hours worth of SQL commands. Then I moved the new script files to the vhost of the live site, after editing the YOURLS configuration file and the nginx vhost config of course. It seemed to start working right away. All this took me two days.
Now the code for tny.im is much more clean, readable and most importantly, maintainable. I can finally add new features to tny.im without breaking half of the existing ones. And I can update YOURLS without breaking the whole thing, since none of the new features are implemented in the core files. @ozh’s improvements in pages like the links statistics one and yourls-loader will not automatically get merged with the tny.im code, but I can add them manually while keeping my changes.
I’m not yet fully sure the new tny.im is clear of bugs, but over 90% of it seems to work the same or better than before. It should look and work pretty much the same as it did before – which only proves, that I really made a wrong move when I started editing core files, since everything could have been done without touching them. I think I learned the lesson, hopefully not only for YOURLS, but for most scripts which have plugin interfaces.
I think I made the most full-featured URL shortener ever seen, and obviously I’m proud (certainly too proud) of it. It’s all built around YOURLS, and I bet you wouldn’t even tell it was powered by that script at a first glance. Stay tuned as more features and bug fixes are to come.
