March 27, 2019 / gbl08ma / 6 Comments
Many are aware that some YouTubers are unhappy with how YouTube operates. But are you aware that Android app developers go through similar struggles with Google Play? Let me try and explain everything that’s wrong with Android in a single 20 minutes read.
Android was once considered the better choice of mobile platform for those looking for customizability, powerful features such as true multitasking, support for less common use cases, and higher developer freedom. It was the platform of choice in research and education, because not only are the development tools free and cross-platform, Android was also a very flexible operating system that did not get in the way of experimenting with innovative concepts or messing with the hardware we own. This is changing at an increasingly faster pace.
While major new Android versions used to bring features that got both users and developers excited, since a few versions ago, I dread the moment a new Android version is announced and I find myself looking for courage (heh) to look at the changelogs and developer guidelines for it. And new Android versions are not the only things that make my heart beat faster for the wrong reasons: changes to Google Play Store policies are always a fun moment, too.
Before we dive in any further, a bit of context: Android was not the first mobile OS I used; references to my experiences and experiments with Windows Mobile 6.x are probably scattered around this blog. I started using Android at a time when 4.2 was the latest version, I remember 4.4 being announced shortly after, and that was the version my first Android phone ran until the end of its useful life. Android was the first, and so far only, mobile operating system for which I got seriously invested in app development.
I started messing with Android app development shortly before 6.0 Marshmallow was released, so I am definitely not an old timer who can say he has seen Android evolve from the beginning, and certainly not from the perspective of a developer. Still, I feel like I have witnessed a decade of changes – in big part, because even during my “Windows Mobile experiments” era, I was paying attention to what was happening on the Android side, with phones I couldn’t yet afford to buy (my Windows Mobile “Pocket PCs” were hand-me-downs). I am fully aware of how bad Android was for both users and developers in the 4.x and earlier eras, in part because I still had the opportunity to use these versions, and in part because my apps had to support some of them.
API deprecation and loss of backwards compatibility
With every Android version, Google makes changes to the Android APIs. These APIs are how apps interact with the operating system, and simplifying things a bit, they pretty much define what apps can and can’t do. On top of this, some APIs require permissions, which you agree to when you install apps that use them, and some of these permissions can be allowed or denied by the user as he runs the app (of course, the app can refuse to run if the permissions are denied, but the idea is that it will degrade gracefully and provide at least some functionality without them). This is the case for the APIs that access your contact list or your location.
New Android versions include new APIs and, in the past, barely any changes were made to APIs introduced in previous versions. This meant that applications designed with an older version in mind would still work fine, and developers did not need to immediately redesign their apps with new versions in mind.
In the past two to three years, new Android versions have also began removing APIs and changing how the existing ones work. For example, applications wishing to stay active in the background now have to display a permanent notification, an idea which sounds good in theory, but the end result is having a handful of permanent notifications in your drawer, one for each application that may need to stay active. For example, I have two in my phone: one for the call recorder, and another for the equalizer system. One of my own apps also needs to have a similar notification in Android 8/Oreo and newer, in order to reliably perform Wi-Fi scans to locate the user in specific locations.
In the upcoming Android version 10/Q, Google intends to restrict even more what apps can do. They are removing the ability for apps to access the clipboard, killing an entire category of clipboard management apps (so that you can have a history of what you copied, so that you can sync the clipboard with your other phones and computers, etc.). Currently, all apps can access the clipboard without special permissions, but the correct way to solve this is to add a permission prompt, not to get rid of the API entirely. Applications can no longer turn the Wi-Fi on or off, which prevents automation apps from e.g. turning off the Wi-Fi when you’re driving. They are thinking of entirely preventing apps from accessing arbitrary files in “external storage” (SD cards and the area of internal memory on your phone where screenshots and camera pictures go, and where you put your MP3s, game ROMs for emulation, etc.).
Note that all of these things that they are removing for “security”, could simply be gated around a permission prompt you’d have to accept, as with the contact list, or location. Instead, they decided to remove the abilities entirely – even if users want these features, apps won’t be able to implement them. Existing apps will probably be review-bombed by users who don’t understand why things no longer work after updating to the shiny new Android version.
These changes to existing APIs mean more for users and developers. Applications that worked fine until now may stop working. Developers will need to update their apps to reflect this, implement less user-friendly workarounds, explanation messages, and so on. This takes time, effort, money etc. which would be better spent actually fixing other issues of the apps, or developing new features. For small teams or solo developers, especially those doing app development as a hobby or as a second job, catching up with Google’s latest “trends” can be insurmountable. For example, the change to disallow background services meant that I spent most of my free time during one summer redesigning the architecture of one of my apps, which in turn introduced new bugs, which had to be diagnosed, corrected, etc., and, in the end, said app still needs to show a notification to work properly in recent Android versions.
There are other ways Google can effectively deprecate APIs and thus limit what applications can do, without releasing new Android versions or having to update phones to them. Google can decide that apps that require certain permissions will no longer be allowed on the Play Store. Most notably, Google recently disallowed the SMS and Call Log permissions, which means that apps that look at the user’s call log or messaging history will no longer be allowed on the store.
Apps using these permissions can still be installed by downloading their APKs directly or by using alternative app stores, but they will no longer be allowed on the Play Store. This effectively means that for many apps, the version on the Play Store no longer contains important functionality. For example, call recorders are no longer able to associate numbers with the recordings, and automation apps can no longer use SMS messages as a trigger for actions. Because Google Play is where 99% of people get their apps, this effectively means functionality requiring these permissions is now disallowed, and won’t be available except to a extremely small minority of users who know how to work around these limitations.
The Google Play Store is the YouTube of app developers
Being on the Play Store is starting to feel much like producing content for YouTube, where policy changes can be sudden and announced without much time in advance. On YouTube, producers always have to be on the lookout for what might get a video demonetized, on top of dealing with content claims, both actions promoted by entirely automated, opaque systems. On the Play Store, we need to be constantly looking out for other things that might suddenly get our app pulled or our developer account banned – together with the accounts of everyone who Google decides has anything to do with us:
And this is just a tiny sample, not even the “best of”, of the horrifying stories that are posted to r/androiddev, every other day. For each of these, there are dozens in the respective “categories”. Sometimes the same stories, or similar ones, also make the rounds in Hacker News. It seems Google is treating Play Store bans and app removals with the same or worse flippancy that online games ban players suspected of cheating. Playing online games isn’t the career of most people who do it, but Android app development is, which leads to the obvious question, what do people do when they are banned?
After writing this, I realize my YouTube analogy is terrible. You see, on YouTube generally one receives strikes, instead of waking up one day to suddenly see their account banned. YouTubers also have the opportunity to profit from the drama caused by the policy changes by “reacting” to them, for example. And while YouTubers typically have the sympathy of their viewers, app developers have to deal with user outrage – because users have no idea, or don’t care, about why we’re being forced to massively degrade the performance and features of our apps. For example, the developer of ACR, a popular call recorder, had to deal with bad app reviews, abuse and profanity among thousands of emails from outraged users after removing the call log permission, and this was after an extensive campaign warning users of the upcoming changes (as a user of ACR, I uninstalled the Play Store version and installed the “unchained” version, which keeps the call log features, through XDA Labs).
As a freelance developer or as a small company, developing for Android is riskier than ever. I can start working on an app idea today and it’s possible that in six months, when it is ready for the initial release, changes to the store policy will have rendered my app unpublishable or have severely affected its functionality… in addition to the aforementioned point about APIs deprecating and changing semantics, requiring constant upkeep of the code to keep up with the latest versions.
If you opened the links above, by now you have probably realized another thing: user support with actual humans is non-existent, and if only their bots were as responsive as Google Assistant… And, if they are not bots, then they are humans which only spit out canned responses, which is just as bad. It is widely known that the best method for getting problems solved with regards to Google Play listings, is to catch the attention of a Google employee on social media.
It seems the level of support Google gives you is correlated to how many people will read your rants about your problems with their platforms. And it’s an exponential correlation, because being big isn’t enough to get a moderate level of support; you must be giant. This is a recurring problem with most Google services, especially if you are not using G Suite (apparently, app developers do not count as “paying customers” when it comes to support). Of all the things I’d like the EU to regulate (and especially, to not regulate, but that’s a story for a different time), the obligation for these mega-corporations to provide actual user support is definitely one of them.
Going back to the probably flawed YouTube analogy, there’s one more parallel to draw: many people believe that in recent years, YouTube has been making changes to both policies, business models and the “algorithm”, that heavily favor the big, already-established creators and make it hard for smaller ones to ever be successful. I believe we are seeing a similar trend on the Google Play Store – just keep in mind you must not analyze an app’s popularity or “level of establishment” by the number of downloads or active users, but by how much profit it generates in ad revenue and IAP cuts.
“Android is open source”
“Android is open source” is the joke of the year – for the fifth consecutive year. While it is true that the Android Open Source Project (AOSP) is still a thing, many of the components that make Android recognizable and usable, both from an end user and developer’s perspective, are increasingly closed source.
Apps made by Google are able to do things third-party apps have trouble replicating, no doubt due to the tight-knit interaction between them and the proprietary behemoth that is Google Play Services. This is especially noticeable in the “Google” app itself, Google Assistant, and the Google launcher.
If you install an AOSP build, many things will be missing and many apps – my own ones included – will have trouble running. Projects looking to provide “de-googlified” versions of Android have developed extensive open source replacements for many of the functions provided by Google Play Services. The fact that these replacements had to be community-developed, and the fact that they are very much necessary to run the majority of the popular applications, show that nowadays, Android can be considered open source as much as in the sense that it can be considered a Linux distro.
AOSP, on its own, is effectively controlled by Google. The existence of AOSP is important, if nothing else, to define common APIs that the different “OEM flavors” of Android must support – ensuring, with minor caveats, that we can develop for Android and not for “Samsung’s Android” or “Nokia’s Android”. But what APIs come and what APIs go is completely decided by Google, and the same is true for the overall system architecture, security model, etc. This means Google can bend AOSP to their will, stripe it of features and move things into proprietary components as much as they want.
Speaking of OEMs and inter-device compatibility, it’s obvious that this push towards implementing important functionality in Google Play Services and making the whole operating system operate around Google’s components has to do with keeping the “OEM flavors” under control. A positive effect for users and developers is that features and security patches become available even on devices that don’t receive OEM updates, or only receive updates for the major Android version they came with, and therefore would never receive the new features in the latest major release. A negative effect is that said changes can affect even old Android versions overnight and completely at Google’s discretion, much like restrictions on what APIs and permissions apps on the Play Store are allowed to use.
Google’s guiding light when it comes to Android openness seems to gravitate towards only opening the Android source as much as necessary for OEMs to make it run on their devices. We are not at that extreme point – mainly because the biggest OEMs have enough leverage to prevent that from happening. I feel that at this point, if Google were able to make Android entirely closed source, they would do it. I wonder what future Fuschia holds for us in this regard.
So secure you can’t use it
The justifications for many of the changes in later Android versions and Google Play policies usually fall into one of two types: “security” and “user experience”, with the latter including “battery life”. I’m not sure for whom Google is designing their “user experience” in recent years, but it certainly isn’t for “proficient users” like me. Let’s, however, talk about security first.
Security should be proportionally strong to what it is protecting. With each major Android version, we see a bigger focus on security; for example, it’s becoming harder and harder to root a phone, short of installing a custom ROM that includes superuser functionality from the start. One might argue this is desirable, but then you notice security and privacy have also been used as the excuse to disallow the use of certain permissions like the call log and messaging access, or to remove APIs including the external storage one.
This increase in security strength makes sense: security is now stronger because we are also storing more valuable information in our phones, from “old-fashioned” personal information about us and our acquaintances, to biometric information like fingerprint, facial and retinal scans. Of course, and this is probably the part Google et al. are most worried about, we’re also storing entire payment systems, the keys for DRM castles, and so on.
Before finishing my point about security, let’s talk a bit about user experience. User experience is another popular excuse for making changes while limiting or altogether removing certain features. If something has to be particularly complicated (or even “insecure”) in order to support the use cases of 1% of the users, it often gets simplified… while the “particularly complicated” or “insecure” system is stripped entirely, leaving the aforementioned 1% with a system that no longer supports their use cases. This doesn’t sound too bad, right? However, if you repeat the process enough times, as Google is bound to do in order to keep releasing new versions of their software (so that their employees can get their bonuses), tying the hands of 1% of the users at a time, you are probably going to be left with something that lets you watch ads only… and probably Google ads at that, I guess. You didn’t need to make phone calls, right? After all, the person on the other side might be pulling a social engineering scheme on you, or something…
Strong security and good user experience are hard to combine together. It seems that permission prompts do not provide sufficient security nor acceptable user experience, because apparently it’s easier to remove the permissions altogether than to let users have a choice.
User choice is what all of this boils down to, really. Android used to give me the choice of being slightly insecure in exchange for having more powerful and innovative features in the apps I install, than in the competing mobile platforms. It used to give me the choice of running 10 apps in the background and having my battery last half a day as a result, but now, if I want to do so, I must deal with 10 ongoing notifications. I used to be able to share files among apps as I do on my desktop, but apparently that is an affront to good security too. I used to be able to log the Wi-Fi networks in my vicinity every minute, but in Android 9 even that was limited to a handful of scans per hour, killing some legitimate use cases including my master’s thesis project in the process. Fortunately, in academia we can just pretend the latest Android version is 8.
Smart cards, including SIM cards, were invented to containerize the secure portion of systems. Authentication, attestation, all that was meant to be done there, such that the bigger system could be less secure and more flexible. Some time in the last two decades, multiple entities decided it was best (maybe it provided “better user experience”?) that important security operations be moved into the application processor, including entire contactless payment systems. Things like SafetyNet were created. My argument in this section goes way beyond rooting, but if my phone is rooted and one of the apps to which I granted root permission steals my banking details, … apparently the banking app shouldn’t have been allowed to run in the first place? Imagine if the online banking of my bank refused to open on my desktop because it knows I know the password for the administrator account.
Still on the topic of security, by limiting what apps distributed on the Play Store are allowed to do and ending support for legitimate use cases, Google ends up encouraging side-loading (direct APK download and installation). This is undesirable from a security point of view, and I don’t think I need to explain why.
Our phones are definitely more secure now, but so much “security” is crippling the use cases of people who do more than binge-watch YouTube and their social network feeds. We should also keep in mind that many people are growing up with smartphones and tablets alone, and “just use your desktop for those advanced tasks” is therefore not an answer. It’s time for my retarded proposal of the week, but what about not storing so much security-sensitive stuff in our phones, so that we don’t need so much security, and thus can actually get back the flexibility and “security pitfalls” we had before? Android, please let me shoot myself in the foot like you used to.
Lack of realistic alternatives
This evolution of Android towards appealing to the masses (or appealing to Google’s definition of what the general public should be allowed to do) would not worry me so much if, as a user, I had a viable mobile OS alternative. On the Apple side, we have iOS, whose appeal from the start was to provide a “it just works”, secure platform, with limited flexibility but equally limited margin for error. Such a platform is actually a godsend for many people, who certainly make up the majority of users, I don’t doubt. Such a platform doesn’t work for me, because as I said, I need to be able to shoot myself in the foot if I want to: let me have 2 hours of battery life if I want, let my own apps spy on my location if I want.
This was fine for many years, because we had Android, which let us do this kind of stuff. It just so happens that because of AOSP, and because there were no other open source or licensable platforms with traction, Android ended up being the de-facto standard for every smartphone that isn’t an Apple one. On the low-end, Android is effectively the only option. Of course, this led to Android having the larger market share. Since “everyone” uses it now, there’s pressure to copy the iOS model of “it just works” and “safe for people with self-harm tendencies” – you can’t hurt yourself even if you wanted.
Efforts to introduce an Android competitor have been laughable, at best. Windows Phone/Windows Mobile failed in part because of a weak and possibly too late entry, combined with a dubious “vision” and bad management decisions on Microsoft’s part. In the end, what Microsoft had was actually good – if there weren’t the case, there wouldn’t be still plenty of die-hard WP/WM fans – but getting there so late (and with so many mixed signals about the future of the platform) means developers were never sufficiently captivated, and without the top 100 apps in there, users won’t find the platform any good, no matter how excellent it is from a technical standpoint. Obviously, it does not help that a significant number of those “top 100 apps” are Google properties; in fact, the only reason Google has their apps on iOS is because, well, iOS was there already when they arrived on the scene.
If even a big player with stupid deep pockets like Microsoft can’t introduce a third mobile platform, the result of smaller-scale attempts like Firefox OS is quite predictable. These smaller attempts have an additional problem, which is finding hardware to run on. It doesn’t help that you can’t change the OS on a phone the same way you can on a PC. In fact, in the long gone year of 2015, I was already ranting about the lack of standardization in smartphone hardware. It’s actually fun to go back at that post, made when Android 4.4 was the latest version, and see how my perception of Android has changed.
I should also note that if a successful Android alternative appears, it will definitely run Android apps, probably through a compatibility layer. In a way, Android set the standard for apps much in the same way that 15 years ago, IE6 was setting web standards in the worst way possible. Did someone say antitrust?
Final thoughts
Android, and therefore Google, set the standard – and the implementation – for what we can and can’t do with a smartphone, except when Apple introduces a major innovation that OEMs and Google are compelled to quickly implement in Android. These days, it seems Apple is stalling a bit in innovation in the smartphone front, so Google is taking the opportunity to “innovate” by making Android more similar to iOS, turning it into a cushioned, limited, kid-safe operating system that ties the hands of developers and proficient users.
Simultaneously, Google is solving the problem of excessive shovelware and even a bit of malware on the Play Store, by adding more automation, being even less open about their actions, and being as deaf as ever. Because it’s hard to understand whether apps are using certain permissions legitimately or not – and because no user shall be trusted to decide that by themselves – useful applications, from call recording tools, to automation, to literally any app that might want to open arbitrary files in the user storage, are being “made impossible” by the deprecation and removal of said permissions and APIs.
We desperately need an Android alternative, but the question of who will develop, use and target said alternative remains unanswered. What I know, is that I no longer feel happy as an Android developer, I no longer feel happy as an Android user, and I’m not likely at all to recommend Android to my friends and family.
Edited at 2:56 March 28th UTC to add clarification about Android clipboard access.
See the discussion for this article on Hacker News, r/AndroidDev, r/Android
April 25, 2018 / gbl08ma / 2 Comments
In the introductory post to this series about the state of internet forums, I mentioned that, to me at least, forums felt like a relic of the past, a medium many internet users will never experience, and that many forums were seeing a downwards trend in the amount of activity in the past few years. But is this just a personal feeling supported by anecdotes, or is this really a general situation?
In the previous post, I also said that these posts would be subjective texts posted to a personal blog, not scientific studies. However, I thought it would be interesting to use these posts to do some introspection and try to understand where this feeling that “forums are dying” comes from. After all, it might just be that I and my circle of friends are abandoning forums, and (in a possibly correlated way) the forums we used to frequent are also dying, while the big picture is quite different. There’s also the possibility that this trend is limited to certain cultures, regions of the world, or specific forum topics/themes.
To do this “introspection”, I’ll be going through some of the forums I know about, and maybe even some I don’t know about, to see how they are doing. I have good news: you can completely skip this lengthy post and you probably will still enjoy the rest of the series. Yeah, this series will still be primarily anecdote-based, but at least we will have looked at a slightly larger number of anecdotes – and we will have taken a deeper look at them. Yay for small sample sizes. Let’s start with the ones I know about.
This forum was founded in April of 2010, and it is the first forum I remember being a part of, although I know for sure I signed up for other forums before that one – also related to web hosting, I just don’t remember their name anymore, and I’m sure that they have not been online for years now. I was one of the first 20 members of that forum, and I ended up being a quite relevant member, because I was a moderator there for over a year, between 2011 and 2012 (or even the start of 2013). I actually got through some “drama” together with the rest of the team, involving forum ownership/administration changes.
I put “drama” in quotes, because to this day I’m still not sure whether the things we were seeing as extremely serious threats were actually that serious… keep in mind that, at the time at least, most of the staff was under 20, perhaps even under 18. I know that at some point legal paperwork was flying around against us, someone wanted to trademark FreeVPS and take the forums from us, or something like that. Now I find all of this a bit cringe-worthy, but I learned quite a lot of stuff (from systems administration, to project management, time management and other soft-skills). Anyway, let’s set the nostalgia aside…
This was actually the first forum I “abandoned”, in the sense I stopped going there as frequently or participating there as much as I initially did. And thus it was only while I was “researching” for this post that I found out that this community, too, is in trouble. The activity levels are way, way down than back in the “golden days”, with what seems to be an average of five posts per day – and sometimes a day goes by without a post. Back in those “golden days”, there would be over 100 posts per day, so much that the statistics page of the forum still indicates an all-time average of 73 posts/day.
This one is not dead, it’s just… trying to find a way to evolve, maybe reinvent itself a bit, in an attempt to bring back the glory of the earlier days. Founded in 2000 – just barely after I learned the basics of how to read Portuguese (let alone write English) – Cemetech (pronounced KE’me’tek) is a community focused on graphing calculators and, to a lesser degree, DIY electronics, and other… nerd stuff. At least, this is how I saw it back when I joined in November 2011. To be fair, of all things this community had to offer and discuss, I really only ever cared about Casio Prizm discussions. After I moved on from Casio Prizm development – and at a time when forum activity was already decreasing – I tried to foment discussions on my Clouttery project, with mild but disappointing success.
Cemetech is a bit of a strange beast because, at least in my view, it hinges a bit too much on the interests, activities and projects of its founding member KermM and other staff, which to me at least, always seemed to be close friends with each other. For one example, I felt like a lot of attention was given to Casio calculators and especially the Prizm models at a time when KermM was “fed up” with TI for some reason, but once TI started releasing new models, with color screens and other features debuted by the Prizm, Casio calculators were slowly forgotten in that community. I’m sure they didn’t do this on purpose – for many years, until the Prizm was launched and caught the eyes of the staff, the community was much more TI-focused than Casio-focused, and it wasn’t unexpected to see it return a bit to its roots. Perhaps I should rephrase my sentence where I said it hinges too much on the staff’s interests… what I mean is, the staff there used to be a discussion promoter, posting a lot on every thread; since KermM kind of left to pursue his PhD and then to be a founder of a startup, Geopipe, activity levels took a hit – at least, and again, from my point of view.
This is a quite anecdotal example… not only is the community this “strange beast”, it’s also focused on the quite niche topic of graphing calculators – even though it always had so many more topics, it was calculator stuff that brought in the most people and the most posts. As a hacker’s platform, graphing calculators are dying, due to new exam regulations in multiple countries imposing restrictions on their hardware and software, and sometimes doing away with this kind of calculators entirely.
It isn’t surprising that a forum about a dying niche subject would be dying. Cemetech now seems down to about 40 posts per day… wait, that doesn’t seem very low. But if you look at the forum index alone, you’ll see that many sections have not even seen a new post in this month, and the number of topics with active discussion seems much lower to me than it once was. Oh well, maybe it’s just me – this is a subjective blog post, after all.
Yet another community focused on graphing calculators – at least initially. This one is much more recent than most of the communities around this topic, but it too has been struggling with lack of activity. In my opinion, it never had that much activity to begin with, but there’s no doubt it went through some rough months – fortunately, it seems to be speeding up a bit now.
CodeWalrus was founded in October 2014… and I’m not sure how to explain this, and I’ll probably get it wrong, but it was founded by people previously associated with Omnimaga (yet another calculator community) – including its founder – but who no longer wanted to be involved in Omnimaga. This older community is, too, pretty much inactive these days (see stats). As for CodeWalrus, which also has a stats page, things look way brighter. At least, you certainly can not accuse the members of not trying to cheer things up.
Before I move on to talking about another forum, note how I said that CodeWalrus was initially more focused on graphing calculators (by virtue of the interests of the members, not because that was the topic imposed by the administration). Well, their strategy – from the very first day – for catering to people with other interests seems to have paid off. A brief look at the active topic lists shows no posts related to graphing calculators… wow.
I don’t think this community needs to be introduced to my readers. It’s a giant community and I can’t quite take its pulse, unlike what I did with the other anecdotes in this post. With over eight million members, its scale is completely different from the other forums I mentioned so far. It isn’t a dying forum, and that’s why I brought it here: to show that definitely not all forums are dying. Or maybe only big forums survive? We shall look into that in future posts.
This forum might not be dying, but it could still be interesting to see whether the variation in number of posts and sign-ups is positive or negative. I searched, and searched, and could not find a live statistics page, or any up-to-date report. With a forum so big, it’s quite possible that computing these kinds of statistics in a real-time fashion is simply unfeasible. However, certain forum views still show the current totals at the bottom. With the help of Internet Archive’s Wayback Machine, we can plot stuff over time…
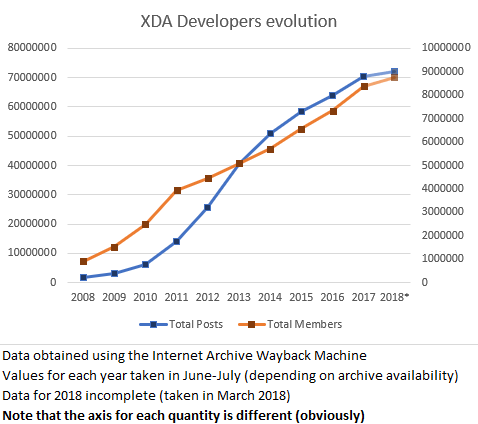
Take from that what you will… but its growth doesn’t seem to be decelerating, even if it apparently isn’t as active as it was in 2012-2013. It could also have happened that despite the slight decrease in the speed at which new posts are added, the quality of the discussion has improved, with an overall better result.
Still on the big forums league, SkyscraperCity – a community with about one million members and over 100 million posts that claims to be the world’s biggest community on “skyscrapers and everything in between”, founded in 2002. In practice, it’s a forum about urbanism that, along many international discussions, also hosts some regional sub-forums where all kinds of stuff is discussed. For example, in the Portuguese forum, you can find topics ranging from architecture and urbanism to transportation and infrastructures, and also general topics about what’s going on in the country as well as completely off-topic stuff like discussion about what’s on TV. It is at SkyscraperCity that you can find the most forum-based discussion around the Lisbon subway, for example – with over 3000 posts per year about that subject alone.
I only participate, precisely, in the Lisbon subway discussions at that forum, so even though I vaguely know about the other sub-forums and topics, I have no idea if the forum is more or less active than it used to be. Using, again, the Wayback Machine, let’s take a look at the evolution in the number of members and total posts in the last 10 years.
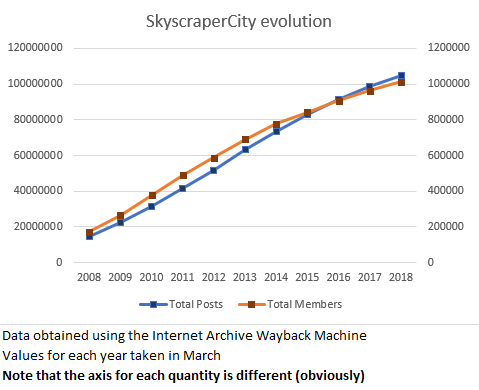
This graph is even less interesting than the XDA one. The number of members and posts has been growing essentially linearly. There is a slight deceleration in the last three to four years, especially in the member count, but that could be due to better spammer detection systems (something as simple as a better captcha system could have that effect).
SkyscraperCity is yet another forum that, despite using antiquated software and not having the best availability or reliability history, doesn’t seem to be going anywhere. It isn’t displaying “exponential user growth” like investors and shareholders like so much to hear. But hey, one of the nice things about forums, is that generally they don’t need to boost user counts like that, because they don’t typically have shareholders to report nice numbers to.
Looks like we’re back to the subject of web hosting. LowEndTalk is the discussion forum of LowEndBox, a website that lists deals on low-spec virtual and dedicated private servers. I never participated or followed this forum in any way, but I have known about its existence and have had a good idea of its “dimension” for almost as long as I have known about FreeVPS.
LowEndTalk makes my job a bit hard because, as far as I can see, they don’t list the total number of members nor the total number of posts anywhere. Fortunately, they do show the total number of threads (or “discussions”, as their forum software calls them), rounded to the nearest hundred. Let’s see if we can get any sort of trend out of this. Wayback Machine to the rescue…
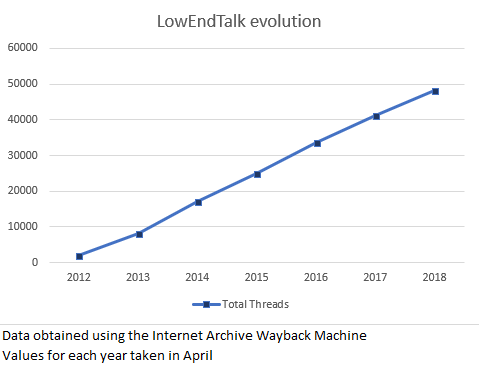
Judging by the thread counts alone, looks like LowEndTalk is yet another forum that isn’t going anywhere, with over 7000 new threads being added each year. The chart gives the impression that growth is slightly more linear than it actually is: the rise in the number of threads is actually slowing down a bit, from an average of about 8700 threads/year in 2013-2015 to about 7500 threads/year from 2015 to the present. Nothing to worry about.
You might be wondering why I brought LowEndTalk here, since it’s not an especially big or especially well-known forum, and it’s not a forum I frequent, either. The reason is that during my “research” for this post, a few things caught my eyes when looking at LowEndTalk.
For a start, their forum software (Vanilla Forums) is not one I commonly see in the wild, or at least one that I recognize – despite the fact that according to Vanilla Forums, they are “Used by many of the world’s leading brands”. At least in its LowEndTalk incarnation, it is extremely “clean”, simple and still good looking. It’s not “responsive” web design, but it’s very readable and fast. It’s definitely different from your run-of-the-mill SMF/phpBB/MyBB-powered forum. But is it better? We shall look into this in a future post.
LowEndTalk only became a “traditional forum” in 2011. Before, they were a Q&A website (like StackOverflow, for example) powered by OSQA. Using the Wayback Machine, it’s easy to see that some of the hot topcis were discussions about moving from OSQA to something more appropriate to their needs. Therefore, this community has yet another interesting quirk: they were not born as a “traditional forum”, they actually moved into one after the community was already bootstrapped and a Q&A model was deemed inappropriate.
LowEndTalk have recently set up a Discord “server”. Unlike what seemed to be the plan at CodeWalrus at one point, it is apparently not their intention to move discussion out of the forum and into Discord. Still, I think this is an interesting point for a future post about forum alternatives – what are people moving to, after all?
Including this one here is pretty ridiculous, but I thought I’d do so anyway, even if only as some sort of honorable mention to the thousands of small forums hosting communities of developers and users of open source projects. I feel that these kinds of forums, along with self-hosted issue trackers (such as Flyspray or Trac) were a much more common sighting in the distant past before GitHub.
Anyway, what is Rockbox and their forums? Rockbox is an open-source firmware for that ancient thing smartphones made us forget about, the MP3 player. You know, of the old-school iPod-with-clickwheel kind.
I used Rockbox for a couple years on the 2nd iPod Nano my parents won in some sort of raffle and which they never really heavily used. iTunes made it a PITA to use it; my family (unlike me) isn’t that much into listening to music and maintaining a music library; and finally, my dad was into PDAs and Pocket PCs way before the iPhone even launched.
For us, the thought of playing music on a MP3 player was already kind of strange even when that iPod was brand new – why go through the hassle of using iTunes, transcoding music files, having to charge and carry around yet another device… when we could just take a full-size SD card, insert it into one of these ginormous Pocket PCs (which also made phone calls) and listen to our existing MP3s and WMAs (no M4A transcoding required!) using Windows-freaking-Media Player on Windows Mobile (or any other player of our liking, since those phones could run arbitrary EXEs compiled for Windows Mobile, and many player application alternatives existed).
Anyway, to finish telling yet another personal story of my life: I found out about Rockbox at a point when the iPod was already forgotten in a drawer. Long story short, that iPod got 500% more use ever since I installed Rockbox on it. Rockbox can even run Doom and has a Gameboy/Gameboy Color emulator, how awesome is that? (And no, Rockbox is not Linux-powered, but there was a separate project which ported Linux to some older iPods.) Sadly the capacitors on my iPod’s screen have failed and only 30% of the screen is readable now, making it a bit hard to use the device.
I would still use that iPod to this day if it weren’t for that malfunction (which I don’t feel like spending $10 on a new screen to fix): the iPod has just 4 GB of storage, but Rockbox can play Opus, the awesome audio format that’s simply the best in terms of quality/filesize ratio (and I hope this sentence will look extremely dated in 10 years). I can fit the relevant part of my music library in there by converting over 10 GB of high-quality MP3, M4A and FLAC into less than 4 GB of Opus at 96 kbit/s – which sounds great.
Rockbox, as you might guess, is pretty much dead these days. It never got to the point where it supported the most recent MP3 players or the latest iPod models, thanks to Apple and their locked bootloaders. MP3 players became a niche/audiophile product as people moved on to smartphones and the demand for them dropped; the prices went up as a result. Perhaps most importantly, if it weren’t for the fact that it could support more devices, Rockbox is a finished product: it can play any relevant music format (including tracker music), it has everything you could possibly want from a music player in terms of sound effects/adjustments, playlist control and library browsing. And now for something that might take you off-balance: Rockbox is a project by Haxx – yes, the same Haxx of the extremely popular and successful program curl! In fact, there is a noticeable overlap between both development teams. Both are awesome pieces of software.
I just realized this post was supposed to be about “forums” and not “alternative firmware for embedded devices and opinions about sound formats”… shit. Anyway, Rockbox is dead and, surprise! the forums are pretty much dead too, for obvious reasons – it would be quite interesting if the forums outlived the open source project they were built around, but it doesn’t seem like this will be the case, and I never saw it happen.
Conclusions
Maybe forums aren’t dying left and right like I thought they were. But they don’t seem to be growing as fast as the rest of the internet. IDK, at this point I’m just making stuff up because I don’t know how fast “the internet” grows. Perhaps it has to do with that shareholder thing, forums don’t usually have to report inflated numbers to anyone. Or maybe people are really locked down inside the bubble-decorated walled-garden of the EVIL ZUCC. Yeah, let’s pretend that is the case, so that my plans for the following posts are not completely foiled. As for this pointless anecdote-based post, its end is here.
BTW: did you know I started working on this post on the 7th of March… only to leave it rotting unfinished since the 9th of March… and finally finish it today? But it’s fine: this way, I could include a ZUCC reference while people are still outraged at Facebook, and before they go back to using it again happily ever after.
September 2, 2017 / gbl08ma / 0 Comments
I neglect this blog very much. I write a non-negligible amount of stuff on the internet, but it’s usually on forums, Reddit, Hacker News and similar, and this blog ends up forgotten. I just wrote a 2000 words post on at CodeWalrus, about the current state of Clouttery, but since it also contains a personal-life-log part, I thought it would be the perfect thing to cross-post here. It’s not the first time I paste forum posts here, and it’s something I should probably do more often, as it helps keep this blog alive while at the same time preserving posts that, while usually made as replies to a forum topic, are general enough to stand on their own.
Hello everyone again. I figured it was time for an update, even though this is not exactly a “happy” update, at least as far as Clouttery is concerned. This is a long post, bring it to bed so you can fall asleep to it if you wish, but trust me, it’s worth reading. I hope you can learn a thing or two about managing your side projects, from reading about my mistakes.
Last school year was the last year of my undergrad course (and I’m starting a second cycle course in a couple weeks) and this required some more effort, so I had less time for side projects. As often happens when one works on something for an extended period of time, I too gradually lost interest in this project.
To make things more… interesting, in mid-March I launched a small website that was meant to be kind of a practical joke about the unreliability of the Lisbon subway (for those who haven’t yet figured it out, I’m Portuguese). You’ll be able to understand what it is about by checking out its repo on GitHub.
I started that project mostly to have something different to work on that was not Clouttery, and the original plan was for it to be something I’d build in a few weeks, publish and then forget, for it to be yet-another-small-thing in my portfolio. But to my surprise, after minimal “marketing” on the SkyscraperCity Portuguese community, that has a section dedicated to railways and subways, my website received a lot more attention than I was expecting, especially for something so simple and tongue-in-cheek.
I then understood there was a real interest in a service that would let people work-around the problems in the Lisbon subway, while at the same time denouncing the problems with the service (for example, by collecting independent statistics). Long story short, a small community assembled around this project, which ended up evolving into an Android app called UnderLX that’s even published on Google Play. And there’s still a lot of work to do for it to become the product I envisioned.
This obviously took most of my summer.
Yes, it’s true that, unlike Clouttery (for which I had even written a complete billing system from scratch!), I’ll never be able to monetize UnderLX effectively. However, it is way more satisfying to work on, at least until I get saturated of it too. With Clouttery, it often took a while to realize what it was about, and let’s be honest: the final reaction of many people was just “meh”. However, with UnderLX, people tend to pay a bit more attention, and those who understand the whole potential of the project usually become much more involved in it. “Unfortunately” for me, the technical side of it is more complex than Clouttery.
It also has an “advantage” to my eyes: both the client (Android app) and the server are open-source from the first day. I regret not going this route with Clouttery; now I have lots of closed-source code which I can’t easily show to anyone because, well, it’s in private repos. I’ll go back to this point, later.
Finally, to add to the school work, the gradual loss of interest, this happy accident that was UnderLX, there’s a fourth factor in all this. Because of multiple reasons including the astronomical rise of the price of Bitcoin, it made economical sense to fulfill a long-time desire of mine: to build a desktop, so I could have a powerful machine, more powerful than my six-years-old laptop. Picking parts and putting it together was very enjoyable, and now I have a proper workstation like I had been dreaming of for the past couple years. If you are interested I might even post a thread about it here. I wasn’t much into PC gaming before (in part, because the hardware didn’t really allow for it), but… you see… to sum things up, many hours were spent chilling to some great triple-A titles (thanks Steam summer sales!…). 
That’s all really nice, but I thought this topic was about Clouttery?
Work on Clouttery gradually slowed down through the last months of 2016, subject to how busy I was with school, and pretty much completely halted in March this year, as I got more and more tired of working on it, so I decided to do that “small” subway thing. It also didn’t help that I was going through a complex phase with Clouttery, more specifically regarding the Windows and Linux clients.
- I couldn’t get the Linux client to work right, despite trying to develop it from scratch multiple times using different languages and technologies. No matter what I tried, there were always major roadblocks to getting it to the point I wanted. I did not want to write it in C or C++; I hate Python but decided to try using it anyway – didn’t end well; UI framework bindings for Golang are apparently all terrible, or don’t have a suitable license. Mono would have been a viable choice, but the gtksharp bindings were tricky to get to work, they apparently had to be recompiled for each GTK version (meaning I couldn’t simply distribute a single binary), and the bindings for GTK3 aren’t/weren’t exactly ready for prime-time. Ugh, I don’t even know what all the problems were anymore. I do remember that I just wanted to write code, but problems with libraries and bindings and whatever were always getting in the way.
- The UI of the Windows client suffers from major lag and other problems, so I decided to switch from WinForms, which is no longer supported, to the supported and way more modern and flexible alternative: WPF. But this was taking a lot of time, certain things were much harder to get to work than I expected, it didn’t help that I only had time to work on it like one hour at a time (school work, etc.), and I lost more and more interest.
For you to get an idea of how inactive this project has been, these are the dates of the latest commits to Clouttery repos:
- Server: 2017-07-10 (and this was only to fix a bug with notification filtering; previous “real” work on it had been on the 23rd of March)
- Windows client: 2017-03-26
- Android client: 2016-12-29
- Chrome client: 2016-09-08
- Linux client: 2017-03-09
Earlier, I mentioned I regret not open-sourcing Clouttery from the beginning. I decided to work on it privately, because it was supposed to become a commercial service, and I feared that if I made it possible for people to host their own Clouttery servers and recompile the clients to talk to it, then nobody would pay for the service. This is obviously a stupid way of thinking, especially when the project in question is a personal project of a student that doesn’t have much time to work on it, and likely would never be able to get it to a commercially-viable state. If the service was worth it, I guess most people would happily pay for it, just to not have the hassle to figure out how to make the server and clients work for themselves; this is especially true since the target audience wasn’t exactly software developers nor sysadmins, i.e. it was people who wouldn’t have a clue how to do that nor would bother even if they were given clear and easy instructions.
Right now I have 30K lines of code, possibly more, that’s closed-source, but for no good reason. To aggravate things, Clouttery shows more of my abilities in software development and engineering than any of my open source projects, because it contains code in more languages, for more platforms, than any other of my projects; it includes web design, API design, use of cryptography, etc. It is not the most beautiful code (for example, the UnderLX Android app has much cleaner and organized code than the Clouttery client, and even then it’s not exactly stellar), but it works, and definitely shows what I’m capable of.
This whole situation is even more ridiculous, because right now there’s very little to no code in Clouttery that’s “novel” to the point of requiring intellectual property protection.  At this point, Clouttery is extremely dumb, as I never got to work on the “intelligence” that would involve machine learning, pattern matching and the like. And in the end, if I wanted to make my super-awesome-and-courageous battery level prediction and damage identifying algorithms secret, I could always have added them as a closed source module while keeping the “infrastructure” open source.
At this point, Clouttery is extremely dumb, as I never got to work on the “intelligence” that would involve machine learning, pattern matching and the like. And in the end, if I wanted to make my super-awesome-and-courageous battery level prediction and damage identifying algorithms secret, I could always have added them as a closed source module while keeping the “infrastructure” open source.
Finally, I always told people that if I were to stop working on Clouttery, I would release its source code. I don’t know what you think, but if I half-close my eyes and look from far away… yeah… like that… yep, I definitely stopped working on it. 
Then why don’t you open source Clouttery?
I definitely want to open source Clouttery, so I can show its code to more people, and so that others may eventually try to pick up on the project. I intend to keep running the official Clouttery server – if for no one else, for me, as my family finds Clouttery useful. I think I would be a little sad if someone took the project and simply changed its name and started running their own “official” service, available to the masses and possibly profiting from it, so I’ll see what kind of licensing restrictions I can add to prevent that. Without the help of a lawyer, it’s a bit hard to add clauses to existing software licenses or write new ones from scratch; even with legal help, it’s easy to get to a controversial result – for example, Facebook has that famous problem with the “patents” file on their open source projects, like React.
…so why didn’t you do it already?
Because ideally, I’d like to publish the source code with the complete commit history. The problem is that, in the past, secrets (API keys and the like) have been committed to the repos. If I remember correctly, the latest server code no longer has that problem – keys are read from a separate, uncommitted file and no longer stored in the source code, but going back in history the secrets are still there. Some of these secrets are hard to revoke and replace, and I’ll need to go on an individual basis to see what can be done about them. Furthermore, the clients also contain secrets in their repos, but this is just one secret per client that’s used to authenticate the client before the server, and since it’s relatively easy to get these secrets from the binaries anyway, I might just go and make them public anyway – their only purpose is to stop people from using the official server with unofficial clients, but if the whole thing is going to be open source, that doesn’t make much sense. These secrets are not involved in securing the pairings between clients and user accounts, so in terms of user account security, there’s no problem with publishing them.
I also need to write a bit of documentation explaining essential things about each repo, and ideally also explaining how to run the server, what needs to be in the database, etc. Or I could not care about any of that, and just have people figure it out by themselves – at that point, I make it hard for people to contribute, but at least people can already look at the code, which is much better than the current situation.
As you can imagine, all this takes time and effort, and I’ve been busy with all those things I mentioned in the first section. But with classes starting very soon, I’d like to get this going ASAP, or it’s not going to be done for some more months.
Did I “give up” on Clouttery too soon?
Is it a good idea to open source it, even if in the distant future I decide to turn it into a proper commercial service?
Do you agree it would have been better if it were open source from the beginning?
What license do you think would be most adequate? – don’t forget the server and each client can have different licenses.
Would you be interested in submitting pull requests for this project, perhaps even taking over one of the sub-projects or the whole thing?
Share your thoughts.
August 23, 2015 / gbl08ma / 1 Comment
Go to the bottom, “Summing it up”, for the TL;DR.
The day I turn this website into a portfolio/CV-like thing will come sooner or later, and arguably that’s a better use for the domain gbl08ma.com than this blog with posts nobody cares about – except when I rant about new operating systems from Microsoft. But if you really care about such posts, do not worry: the blog will still exist, it just won’t be as prominent.
Meanwhile, and off-topic intro aside, the content usually seen on such presentation websites everyone-and-their-cat seems to have these days, will have to wait. In anticipation for that kind of stuff, let’s go in a kind of depressing journey through my eight years programming experience.
The start
The beginning was what many people would consider a horror movie: programming in Visual Basic for Applications in Excel spreadsheets, or VBA for short. This is (or was, at the time; I have no idea how it is now) more or less a stripped down version of VB 6 that runs inside Microsoft Office and does not produce stand-alone executables. Everything lives inside Office documents.
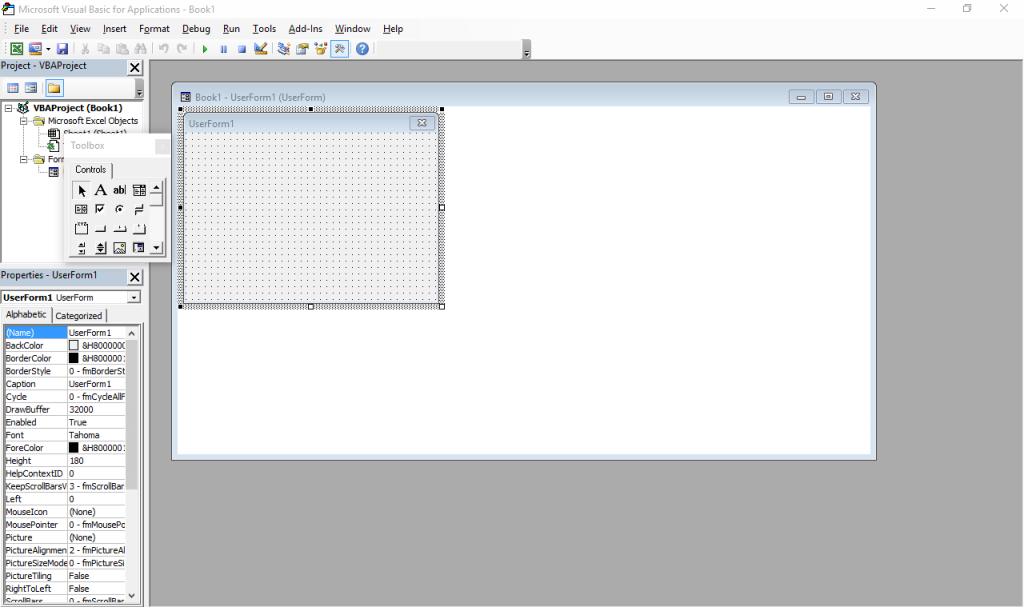
It still exists – just press Alt+F11 in any Office window. Also, the designer has Windows 7 Basic window styles… on Windows 10, which supposedly ditched all that?
I was introduced to it by my father, who knows his way around Excel pretty well (much better than I will probably ever will, especially as I have little interest). My temporal memory is quite fuzzy and I don’t have file timestamps with me for checking, so I was either 9, 10 or 11 years old at the time, but I’m more inclined to think 9-10. I actually went quite far with it, developing a Excel-backed POS system with support for costumer- and operator-facing character LCD screens and, if I remember correctly, support for discounts and loyalty cards (or at least the beginnings of it).
Some of my favorite things I did with VBA, consisted in making it do things it was not really designed for, such as messing with random ActiveX controls and making it draw strange-looking windows (forms) and controls through convoluted Win32 API calls I’d have copied from some website. I did not have administrator rights to my computer at the time, so I couldn’t just install something better. And I doubt my Pentium III-powered computer, already ancient at the time (but which still works today), would keep up with a better IDE.
I shall try to read these backup CDs and DVDs one day, for a big trip down the memory lane.
Programming newb v2
When I was 11 or 12 I was given a new computer. Dual core Intel woo! This and 2GB RAM meant I could finally run virtual machines and so I was put on probation: I administered the virtual computers, and soon the real hardware followed (the fact that people were tired of answering Vista’s UAC prompts also helped, I think). My first encounter with Linux (and a bunch other more obscure OS I tried for fun) was around this time. (But it would take some years for me to stop using Windows primarily.)
Around this time, Microsoft released the Express (free) editions of VS 2008. I finally “upgraded” to VB.NET, woo! So many new things to learn! Much of my VBA code needed changes. VB.Net really is a better VB, and thank Microsoft for that, otherwise the VB trauma would be much worse and I would not be the programmer I am today. I learned much about the .NET framework and Visual Studio with VB.NET, knowledge that would be useful years later, as my more skilled self did more serious stuff in C#.
In VB.NET, I wrote many lines of mostly shoddy code. Much of that never saw the light of day, but there are some exceptions: multiple versions of Goona Browser made their way to the public. This was a dual-engine web browser with advanced UI, and futuristic concepts some major players copied, years later.
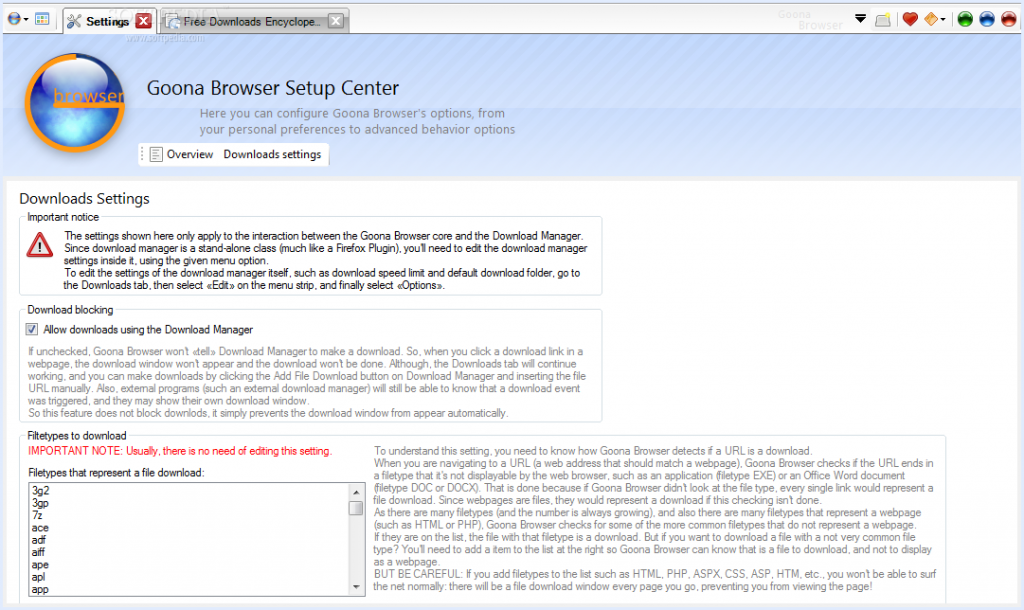
How things looked like, in good days (i.e. when it didn’t crash). Note the giant walls of broken English. I felt like “explain ALL the things”! And in case you noticed the watermark: yes, it was actually published to Softpedia.
If you search for it now, you can still find it, along with its website which I made mostly from scratch. All of this accompanied by my hilariously broken English, making the trip to the past worth its weight in laughs. Obviously I do not recommend installing the extremely buggy software, which, I found out recently, crashes on every launch but the first one.
Towards the later part of my VB.NET era, I also played a bit with C#. I had convinced myself I wanted to write an operating system, and at the time there was a project called COSMOS that allowed for writing (pretty limited) OS with C#… of course my “operating” systems were not much beyond a fancy command line prompt and help command. All of that is, too, stored in optical media, somewhere… and perhaps in the disk of said dual-core computer. I also studied and modified open source programs made in C# (such as the file downloader described in the Goona Browser screenshot) for my own amusement.
All this happened while I developed some static websites using Visual Web Developer Express as editor. You definitely don’t want to see those (mostly never published) websites, but they were detrimental to learning a fair bit of HTML and CSS. Before Web Developer I had also experimented with Dreamweaver 8 (yes, it was already old back then) and tried my hand at animation with Flash 8 (actually I had much more fun using it to disassemble existing SWFs).
Penguin programmer
At this point I was 13 or so, had my first contact with Linux more than done, through VMs and Live CDs, aaand it happened: Ubuntu became my main OS. Microsoft “jail” no more (if only I knew what a real jailed platform was at the time…). No more clunky .NET! I was fed up with the high RAM usage of Goona Browser, and bugs I was having a hard time debugging, due to the general code clumsiness.
How Ubuntu looked like when I first tried it. Good times. Canonical, what did you do?
For a couple of years, in terms of desktop development, I only made some Python scripts for my own amusement and played a very small bit with MonoDevelop every time I missed .NET. I also made a couple Lua scripts for Rockbox. I learned much about Linux usage and system maintenance as I used it more and more on my own computers and on my first Virtual Private Servers, which I got after much drama in the free web hosting communities. Ugh, how I hate CPanel.
It was around this time that g.ro.lt and n.irc.su appeared. g.ro.lt was a URL shortener that would later evolve into 4.l.to and later tny.im. n.irc.su was a social network built on Elgg, which obviously failed. I also made some smaller websites, like one that would take you to random image hosting websites, URL shorteners and pastebins, so you would not use the same service every time you urgently needed one. These represented my first experiences with PHP programming.
I have no pictures to show. The websites are long gone, not on the Internet Archive, and if I took screenshots, I have no idea where I put them. Ditto for the logos. I believe I still have the source code for the random-web-service website somewhere, at least the front page layout.
All this working on top of free stuff: free (and crappy) subdomains, free (and crappy) web hosting, free (and less crappy) virtual servers. It would take me some time until I finally convinced myself I needed to spend some money for better reliability, a gist of support and less community drama. And even then I would spend Bitcoin, which I earned back when it was really cheap, making the rounds of silly faucets and pulling money out of CPAlead-like offers through the use of multiple proxies (oh, the joy of having multiple VPS…). To this day I still don’t have a PayPal account.
This time, and when I actively developed tny.im (as opposed to just helping maintain it), was the peak of my gbl08ma-as-web-developer phase. As I entered and went through high school, I would get more and more away from HTML and friends (but not server maintenance), to embrace something completely different…
Low level, little resources: embedded systems
For high school math everyone had to use a graphing calculator. My math teacher recommended (out of any interest) Casio calculators because of their ease of use (and even excitedly mentioned, Casio leaflet in hand, the existence of a new and awesome color screen model that “did everything and some more”). And some days later I had said model in my hands, a Casio fx-CG 20, or Prizm, which had been released about a year before. The price difference from the earlier dot-matrix screen Casio calcs was too small to let the color screen go.
I was turning 15, or had just turned 15. I remember setting up the calculator and thinking, not much after, “I want to code for this thing”. Casio’s built-in Basic dialect is way too limited (and after having coded in “real” languages, Basic was silly). This was in September 2011; in March next year I would be releasing my first Prizm add-in, CGlock, a calculator PIN-locking software.


Minimalist look, yay! So much you don’t even notice it’s a color screen.
This was my first experience with C; I remember struggling with pointers, and getting lots of compilation warnings and errors, and run-time errors. Then at some point everything just “clicked in” and C soon became my main language. Alas, for developing native software for the Prizm, this is the only option (besides using C++ without most of its features, not even the “new” keyword).
The Prizm is a horrible platform, especially for newbie C programmers. You can’t use a debugger, nor look at memory contents, the OS malloc/free implementation has bugs (and the heap is incredibly small, compared to the stack) and there’s always that small chance some program damages your calculator, or at least corrupts your estimated files and notes. To this day, using valgrind and gdb on the desktop feels to me as science fiction made true. The use of alloca (stack allocation) ends up being preferred in relation to dynamic allocation, leading to awkward design decisions.

Example of all the information you can get about an error in a Prizm add-in. It’s up to you to go through your binary (and in some cases, disassemble the OS) to find out what these mean. Oh, the bug only manifests itself when compiling with optimizations and without symbols? Good luck…
There is a proprietary emulator, but it wasn’t designed for software development and can’t emulate certain things. At least it’s better than risking damage to expensive hardware. The SuperH-4 CPU runs at 58 MHz and add-ins have access to about 600 KiB of memory, which is definitely better than with classic z80-powered Texas Instruments calculators, but one still can’t afford memory- or CPU-intensive stuff. But what you gain in performance and screen resolution, you lose in control over the hardware and the OS, which still have lots of unknowns.
Programming for the Prizm taught me how it’s like to work without the help of the C standard libraries (or better, with the help of incomplete and buggy standard libraries), what a stack overflow looks like (when there’s no stack protection), how flash memories work, what DMA is, what MMUs do and how systems can be bricked when their only bootloader is not read-only. It taught me how compilers work from an end-user perspective, what kind of problems and advantages optimizations introduce, and what it’s like to develop parts of the C standard library.
It also taught me Casio support in Portugal (Ename) is pretty incompetent at fixing calculators, turning my CG 20 into a CG 10 and leaving two big capacitors out of a replacement main board. In this hardware topic, I learned quite a bit about digital logic from Prizm hardware discussions at Cemetech. And I had some contact with SH4 assembly and a glimpse into how to use IDA Pro. Thank you Casio for developing a system that works so well and yet is so broken in so many under-the-hood ways, and thank you Cemetech for briefly holding the Prizm higher than TI calcs.
I developed other add-ins, some from scratch and others as ports of existing PC software (such as Eigenmath). I still develop for the Prizm from time to time, but I have less and less motivation as the homebrew community has stagnated and I use my Prizm much less, as I went to university. Experience in obscure calculator platforms does not make for a nice CV.
Yes, in three years or so I went from the likes of Visual Studio to a platform where the only way to debug is to write text to the screen. I still like embedded and real-time programming a lot and have moved to programming more generic and well-known things such as the ESP8266.
Getting in the elevator
During the later part of high school (which I started in the fall of 2011 and ended in the summer of 2014), I did more serious Python stuff, namely Mersit, later deprecated in favor of Picored, which is not written in Python but in Go. Yes, I began trying higher-level stuff again (higher level, getting in the elevator… sorry, I’m bad at jokes).
My first contact with Go was when I was 17, because I wanted to develop something that ran without external dependencies (i.e., unlike Java or .NET) and compiled to native code. I wanted to avoid C/C++, but I wasn’t looking for “a better C” either, so Rust was not it. Seeing so much stuff about Go at Hacker News, one day I decided to try my hand at it and I like it quite a lot – I’m still unsure if I like it because of the language itself or because of the great libraries one can use with it, but I think both play an important role.


This summer I decided to give C# another chance and I’m quite impressed – turns out I like it much more than I thought. It may have something to do with trying it after learning proper languages vs. trying it when one only knows VB. I guess my VB.NET scars are healed. I also tried a bit of Java, in my first contact with it ever, and it seems my .NET hate converted into Android API hate.
Programming with grades
University gave the opportunity (or better, the obligation) of having other people criticize my code. The general public could already see the open-source C code of my Casio Prizm add-ins, and even the ugly code of Goona Browser, but this time my code was getting graded. It went better than I initially thought – I guess the years of experience programming in different languages helped, especially as many of the people I’m being compared with have only started programming this year.
In the first semester we took an introductory programming course, which used Python, and while it was quite easy for me, I took the opportunity to learn Python to a greater depth than “language in which to write quick and dirty glue code”. You see, until then I had not used classes in my Python code, for example. (This only goes to show Python is a versatile language, even if slow.)
We also took an introductory computer architecture course where we learned how basic CPUs work (it was good for gluing all the separate knowledge I already had about it) and programmed in assembly for a course-specifc CISC-like architecture. My previous experience with reading SH4 assembly proved quite useful (and it seems that nowadays the line between RISC and CISC is more blurred than ever).
In the second semester, I had the opportunity to exercise my C knowledge, this time not limited to the Prizm platform. More interestingly, logic programming, a paradigm I had no intention of ever programming in, was presented to us. So Prolog it was. It went much better than I anticipated, but as most other people who (are forced to) learn it, I have no real use for it. So the knowledge is there, waiting for The Right Problems(tm). I am afraid I’ll forget much of it before it becomes useful, but if there’s something picking C# up again taught me, is that I can pick up pretty fast skills learned and abandoned long ago.
The second year is about to begin and there’s some object-oriented programming coming, I hope I do well.
Summing it up
I have written non-trivial amounts of code in at least 8 languages: Visual Basic, PHP, C#, Python, Lua, C, Go, Java and Prolog. I have contacted with two assembly dialects and designed web pages with HTML, CSS and Javascript, and of course automated some tasks with bash or plain shell scripting. As can be seen, I’m yet to do any kind of functional programming.
I do not like “years of experience” as a way to measure language proficiency, especially when such languages are learned for use in short-lived side projects, so here’s a list with an approximate number of lines of code I have written in each language.
- C: anywhere between 40K lines and 50K lines. Call it three years experience if you will. Most of these were for Prizm add-ins, and have since been rewritten or heavily optimized. This is changing as I develop less and less for the Prizm.
- PHP: over 15K lines, two years if you want to think that way. The biggest chunk of these were for developing the additions to YOURLS used in tny.im, but every other small project takes its own 200-500 lines of code. Unfortunately, most of this is “bad” code, far from idiomatic. The usual PHP mess, you know.
- Python: at least 5K lines over what amounts to about six months. Of these, most of the “clean” lines (25-35%) were for university projects.
- Go: around 7K lines, six months. Not exactly idiomatic code, but it’s clean and works well.
- VBA: uh, perhaps 3 or 4K lines, all bad code 🙂
- VB.NET: 10K lines or so, most of it shoddy code with lots of Try…Catch to “fix” the problems. Call it two years experience.
- C#: 10K lines of mostly clean and documented code. One month or so 🙂
- Lua: mostly small glue scripts for my own amusement, plus some more lines for use in games such as Minetest, I estimate 3-4 K lines of varying quality.
- Java: I just started, and mostly ported C# code… uh, one week and 1.5K lines?
- HTML, CSS and JS: my experience with JS doesn’t go much beyond what’s needed to modify DOM elements and make simple AJAX requests. I’ve made the frontend for over 5 websites, using the Bootstrap and INK frameworks.
- Prolog: a single university assignment, ~250 lines or one month. A++ impression, would repeat – I just don’t see what for.
In addition to all this, I have some experience launching the programs and services I make – designing logos/branding, versioning, keeping changelogs, update instructions, publishing, advertising, user support. Note that I didn’t say I’m good at any of these things, only that I have experience doing them, for better or worse…
Things I’d like to have more experience with:
- Continuous integration / testing in general;
- Debugging code outside of .NET/Visual Studio and printing debug lines in C;
- Using Git and other VCS in big repos/repos with more people (I want to see those merge conflicts and commits to the wrong branch coming);
- Server-side web development on something other than PHP and Go. And learning to use MVC frameworks, independently of the language;
- C++ (and Java, out of necessity. Damned Android);
- Game development. Actually, this is how many people start, but I’m so cool that I started by developing POS software 🙂
January 11, 2014 / gbl08ma / 0 Comments
In case you haven’t noticed yet, the version 1.2 of the Utilities add-in for the Casio fx-CG 10 and 20 (known as Prizm) has been released today. More information and download on this page.
Following my announcement on Twitter about the new release, it got retweeted by the official Casio Prizm Twitter account. This is a move without precedents on their part – no 3rd party add-in had ever received the slightest official public recognition. Most likely the social media marketeer retweeted my nice tweet without really knowing what he/she was doing.
However, this had little impact. The tny.im shortlinks you see received less hits by the time they retweeted, than by the time I originally tweeted – despite @CasioPrizm having over the quintuple of followers I have.
March 3, 2013 / gbl08ma / 0 Comments
Seeing that I’m getting a lot of hits on this blog from people searching about the SliTaz servers being down right now, probably because I have a blog post with the words “SliTaz” and “dead” on the title, which was published over a year ago, I’d like to inform that I know nothing about the server situation other than the fact that the website is unavailable for me too.
(talking about SliTaz, I kinda stopped following the project, even though I find it interesting… note to self: pay more attention to it from now on)
February 21, 2012 / gbl08ma / 1 Comment
My last blog post has been about the fact that ReactOS is not a dead open source project, and that in fact they had just released a new alpha version. So to keep with my line of open-source-projects-journalism, today I talk about another open source project, this time a GNU/Linux distro: SliTaz.
You may have heard about this project before: SliTaz has been around since 2007, when the first “cooking” version of the distro was released. But what is SliTaz? As it says on the official website, it is “a free operating system providing a fully featured desktop or server in less than 30 MB”. And indeed, you download an ISO file that weights at about 30MB, which you can burn to a USB stick, CD or DVD, or run on a virtual machine. From there, SliTaz boots to a complete desktop with various utilities and office applications, server-side software and, of course, a web browser. A nice control panel lets you configure the system and install more applications.
The whole system runs in a small amount RAM, meaning you don’t need to install it to a hard disk to be able to use it; when you turn off the computer, the changes made are lost. So, this is not more nor less than a LiveCD that has a size of ~30MB. It is very fast, even on older computers.
Is this news? No, there have been tiny Linux distros around before, and SliTaz itself has been around for a lot of time, as I told. Damn Small Linux, Puppy Linux and TinyCore are some examples of other GNU/Linux distros that have the goal of being small in size. I particularly like SliTaz because of its uniqueness: a unique packaging system (tazpkg), unique utilities, and a unique look too. DSL and Puppy Linux are already too “big” for me, and TinyCore is too small to be useful to me. So SliTaz just got it right for my concept of “tiny Linux distro”.
I don’t use SliTaz every day – it’s not my daily use distro – but I still like it very much and it’s been useful to me a few times. I use to keep around a USB pendrive with a copy of SliTaz installed – one never knows when it may be useful, specially after you’ve installed office tools like Abiword and Gnumeric. Of course, your idea of usefulness certainly varies from mine, and that’s why I like open source: just change it so it works the way it’s useful to you.
There have been no cooking or stable releases of SliTaz recently, and there was a lack of word from the developers. I started to think that the project was slowly becoming abandoned. Fortunately, today I checked their website, and this is what I see: news! Well, not really in the news section, but a blog post: Lack of news but work never stops.
So, in conclusion, it seems the project is still active, the only problem is that everyone is too busy to release cooking versions and write press-releases. And it looks like the team is working to get a cooking version out soon, which is great news, since the latest cooking was in May of last year and it’s out of date when compared to the work that’s been done on the repositories since that time.
To the SliTaz developers: Keep up the great work! 🙂
Edit 23rd February 2012: Slitaz 4.0 RC1 is out! Check how the new version looks like.
February 12, 2012 / gbl08ma / 0 Comments
Looks like ReactOS 0.3.14 has been finally released. See the news here, on the official website.
I can’t say I care a lot about ReactOS, as I mostly use Linux and other *nix and have no interest on NT-based operating systems. ReactOS is one of the OSS projects I follow by keeping a “semi-closed eye” on them. But still, it is interesting to see how the project has evolved since its 0.3.13 release, almost a year ago. They now support Windows XP themes, wifi drivers, ACPI among other improvements.
But again, will ReactOS do any good when it finally achieves full Windows XP capability? I blogged about that some time ago.
December 24, 2011 / gbl08ma / 0 Comments
I know it’s a bit too late already, but since what matters is the Christmas spirit and not the timings, here are my wishes for a great Christmas and a happy new year 2012. Let the happiness and healthiness be with you this Christmas and new year eve, as well as throughout 2012 and, well, your whole life. I hope all your good wishes come true! 😀
Now, my turn on Christmas wishes: let’s hope my new shiny, cheap Android tablet I bought (Flytouch 3, P041 model, not a Christmas gift!) gets fixed – its internal memory (a microSD card) is corrupt. Now I need to fix the microSD card in a Linux computer. Linux computer? Check. SD card reader? Check. microSD reader? Missing. Trying alternatives… microSD-to-SD adapter? Missing… Santa, all there is on my gifts list is a way to fix that tablet’s microSD, I want a microSD-to-SD adapter or a USB microSD reader (costs $1)!
I’ll let you know if/when I fix the device and get rid of that damn error the Flytouch returns when trying to burn the Linux kernel to said microSD!
Merry Christmas!
gbl08ma / Gabriel Maia
November 19, 2011 / gbl08ma / 1 Comment
I’ve met the Raspberry Pi project around three months ago, and immediately fell in love for its concept and idea: to build a extremely cheap Linux box that could be used to teach children the world of programming, Linux and even open source in general. But when I first knew about this project (it was on Slashdot if I remember correctly), me and lots of other people were skeptical about it, specially because of the aim price (USD $25/18,5€), because of the size of the prototype board (the first one presented was no big than a USB flash drive, and in fact, was smaller than many of them), and because their website consisted of a single page with an image of that prototype board and a few technical details; it also said the Raspberry Pi Foundation was a charity (non-profit).
I forgot about the project for a few weeks: like many other people, I thought this was no more than vaporware. Later, when I visited their website again, I found it to be much more complete, and it already had some more information and more facts had been confirmed. From then on, I began to check the website much more frequently and, currently, the Raspberry Pi doesn’t look like vaporware anymore: there are alpha boards built that have been distributed to various people doing software work on them, and the project staff has ran demos of the Alpha boards at many meetings. The Raspberry Pi was and continues to be responsible by news articles, sometimes front-page articles, on many technology sites. They also shown on UK television and radio. All this, and they haven’t released a final product to the market yet!
So what is the Raspberry Pi, in conclusion? It’s a extremely cheap, cheaper than many books, embedded Linux board. At launch, there will be two models: A and B. The model B has better features than the A, they will cost $35 and $25 respectively. Behind the project there’s a charity with the same name, the UK-based Raspberry Pi Foundation.
Both models feature an ARM11 Broadcom CPU clocked at 700MHz and a GPU capable of drawing Full HD H.264 videos at 30fps, and supporting OpenGL ES 2.0; a SD/MMC/SDIO card slot from which the OS will boot. For video output, the Pi has both an HDMI connector and a good old composite video connector, which means the Pi will be able to display not only on a modern LCD with HDMI connectors, but also on older TV sets and displays that feature composite video input(s). The RAM varies according to each model, and is presented stacked on top of the CPU (PoP configuration). Both models have some GPIO (General Purpose Input/Output) pins, although nowhere as many as things like the Arduino.
As for power supply, the Raspberry Pi will ask for a 5V input, and it should run off 4 AA cells. It will use a micro-USB connector for power supply, but note that it doesn’t act as a USB client device (it only draws power from micro-USB, no data). The energy consumption of the board is also incredibly low, and I believe it is lower than the consumption of many devices in standby mode.

The publicly shown Raspberry Pi Alpha board
Model A will only have 1 USB port, no ethernet and 128MB of RAM, whereas the model B will feature 2 USB ports, an ethernet jack and 256MB RAM. The final PCB design has been released, after lots of work doing the routing of the tracks of the PCB to ensure the maximum efficiency of the Raspberry Pi; the board will have the same area as a credit card (it’s amazing how could they fit all the connectors in such a small size board).
Oh, and I forgot to say: the Pi also has a 3.5 mm jack audio output; combine this with the small form factor of the board, some portable power supply and buttons connected to the GPIO, and there you have a very powerful MP3 player that also turns into a full-featured PC when you connect a display, keyboard and mice to its USB port(s). Or you could bring a touchscreen and make your very own Android/Ubuntu/whatever Linux tablet!

The circuit scheme of the final board
As for the software, the board is designed to run ARM Linux distros, but people are already planning on porting other lightweight OS – don’t expect Windows in any way though as a) this device is simply too open-source for Microsoft’s mind and b) There’s not enough RAM to run Windows 8 in any way. Plus, WINE and other Windows abstraction layer software will not work, as these are not designed for ARM. Apart from these limitations (that most certainly don’t affect you unless you were expecting to make a hardcore gaming machine out of it), the Pi will do, better or worse, practically everything you do with a PC: web browsing, email, word processing, spreadsheet, instant messaging… for more advanced users, this is also a perfect server, either for serving files on USB drives, or hosting websites. For those (of any age!) willing to learn (embedded) software development, this is also the perfect device – specially because it’s cheap as hell, when compared to things like the successful Beagleboard.
I guess that we only need to allow time for humans to develop uses for the Raspberry Pi, and some of them will drive our minds crazy I’m sure. Enough presenting the Pi, if you want to know more you can do research…
Why I think the Pi will make a difference
You already saw what the Pi is from my quite long introduction above. I won’t say this is a revolutionary device, that will change the way we see technology. I won’t say that this is going to cause an impact as big as the iPhone caused on mobile phones or as the iPod on digital music, either, specially because a) the Pi doesn’t have an Apple on the back, b) the iPhone/iPod weren’t news either, since things like them already existed before; that fruit company only made them friendly to the masses (and credit to them for that).
Other thing that makes me think the Pi won’t reach the intended audience so fast as some expect is it’s appearance. I don’t want to make more analogies with Apple’s devices, but please allow for just another one: smartphones existed well before the iPhone, and I have an HTC phone from 2005 that did more (has 3G connectivity, for example) than the first iPhone, that was launched much later. Then why didn’t the older smartphones make much success? I don’t think expensive is the problem, but their look: most of them look ugly, to the masses at least, something the iPhone did better (just like with most recent Apple products).
Stopping with Apple analogies (I promise!)… the Pi is an innovative product by its size, its price and its main objective. If enough people know about it, it will suppress many markets, such as the thin clients one. From my point of view, this is the most cheap and minimal mini-ITX you can get, with the detail it doesn’t run Windows, but that is a matter of getting the world used to Linux. Due to its small power supply requirements and the cheap price, it will also bring computing where it is very rare nowadays, enabling people in development countries to have their first PC (or PED – personal embedded device 🙂 ). If we find a way to cheaply connect the Pi to the internet no matter where one is, it is even better, because people that have gain access to the ‘net and to who we teach how to use it, will eventually become better informed people.
In other words, this is a bit like the OLPC project, except that, at least in my honest opinion, and based on what I know from the OLPC project (which might not be accurate), it is being done with much more responsibility and a true knowledge of the requirements of the target audience. It also uses emerging technologies such as Linux for the ARM architecture, contributing to the evolution of the open source universe. But still, I don’t want to say the Pi is the perfect device: the Universe doesn’t allow perfect things to be made, duh. So, not being the perfect device, there’s always space for improvement, specially because one size doesn’t always fit all, and people will always one to thinker with a Pi to make them more like their own definition of “perfect”.
Other important difference in comparison with the OLPC project is that it isn’t just for children: indeed, the first batch of 10000 Raspberry Pies will be more targeted at developers and hackers (that doesn’t mean some “hackers” aren’t as young as me…), however and unlike was wrongly stated in many news, any person can buy it. Detail: I’m not yet sure if the first batch will be sold as a buy-one-donate-another project, making you pay for two Pis whereas you’ll only receive one, having the other going to charity. Please enlighten me on this subject!
The defects of the Raspberry Pi
As I said, this isn’t the perfect thing, and I think it’s important to point out its defects and limitations, because only this way we can improve on them. So, here are the things that according to my thoughts are yet to be solved or better discussed:
- Peripherals: the Pi can be considered nothing more than a PC’s motherboard; it still needs you to have all the peripherals, from keyboards, mice, SD cards, and specially, a screen where to show things. The screen is the most expensive part, if you assume people can’t use an existing screen because of e.g. the lack of one.
- Power supply: well, this is a “defect” that comes with every device, so I’m not considering it as a defect, but more of a “thing to discuss” – and many people are already discussing it, fortunately. Even if the Pi consumes such little power that it can run of standard AA cells, the things you’re going to connect to it won’t. And being the Pi basically just what a motherboard is to the PC, it’s pretty useless without some input/output devices – and these will consume much more power than the Pi. Well, we can assume you only connect a four-line character cell display to it, and a USB keyboard for input, and then use the display to show four lines of Linux shell – not very practical, obviously.
- Memory/CPU specifications: As I said above, it’s not going to run the traditional Windows, nor a recent Firefox on Linux, at least until they stop making memory-hungry Firefoxes. It’s all a matter of studying the capabilities of the device and see if it applies for your project. I think the low specifications of the board also have a positive point: It will teach the young developers how to make apps that don’t use 1GB of RAM after half an hour of use, thus teaching these developers how to manage the system resources.
- The case: it’s known that the Pi will ship without case. There will be cases available on the online store of Raspberry Pi, but of course these cost some money, increasing the price of the device if you must have a case. Of course, we can’t see just the negative part of this: the lack of a case opens people’s mind to creativity and curiosity, making them poke inside the Pi. If it breaks… well, if you have enough money to buy another, that’s not a problem. However, if we want to incentive children to learn programming with the Pi, it must be made somewhat attractive.
Finished! This is my long essay on the Raspberry Pi… please correct me if you find any errors on the facts presented here, and take the opportunity to express your own opinion by dropping a line on the comments. Oh, and of course don’t forget to visit the official Raspberry Pi website for more amusement! 😉