February 19, 2017 / gbl08ma / 0 Comments
I spent the past week, the last one of my winter break, redesigning how the Clouttery server stores data.
The Clouttery server, which is written in Go, was using a simple key-value store (Bolt). I slowly came to the realization that some of the features on the roadmap would be kind of hard to implement using Bolt; that the nested buckets structure used with Bolt was too limiting, by forcing a hierarchy on the data, when sometimes it could be useful to interpret it in other ways. For example, sometimes it could be useful to look at all the battery log entries from all users; with the database structure I had, that required looking into each user’s bucket separately, and within those, into each device separately.
The databases course I took last semester forced me to get my hands very dirty with SQL, and after seeing the benefits, I decided to move to a relational database.
Another reason for moving was that Bolt can’t scale (no replication, it’s meant for use by a single app, like SQLite), and while the server software is not yet ready to be clustered, moving away from Bolt (and, in general, uncoupling the server from the database) is a giant step towards the goal of being able to scale the server to multiple nodes. I had known for long that I had to use something other than Bolt if I wanted to make the server distributed, I just wasn’t sure whether to move to a relational database, another barebones key-value store, or some amalgamation of solutions involving specialized time series databases or what-have-you.
The database can now be accessed transparently by multiple applications, which means that, for example, in case I want to do some complex analysis on the battery histories, I no longer have to stuff that code into the server. I can even use a language other than Go, like Python, which I really don’t like, but has many libraries for data analysis.
I tried to use CockroachDB (and I can’t stress the terribleness of that name enough). At some point, the server was mostly ready to work with it, and it was time to import the data from the Bolt database. My code migrated all data in a single transaction, that was rolled back in the case of errors – that way, as I stumbled upon problems and general incompleteness in my migration code, I did not have to be constantly dropping and recreating the database, as with every failure the database would be always supposedly in a pristine state, with all the empty tables waiting for data.
Let’s just say things were not as smooth as I was hoping. On my laptop with an aging but still plenty fast i7, 8 GB of RAM and a SSD, data would get into CockroachDB relatively fast… but no matter if the transaction was committed or rolled back, once I tried to perform any query – basically any query, even if just counting the amount of users (about 40), would make CockroachDB’s RAM usage skyrocket, to the point where the whole system just hanged for seconds at a time, due to how much swapping was going on.
So I decided to scrap CockroachDB and go with plain old PostgreSQL. Given that the SQL supported by the former is relatively similar to what PostgreSQL supports, changing the queries to work with Postgres was not too hard. The most annoying part is the lack of support of PostgreSQL for the UPSERT command, which in CockroachDB and other databases, behaves like a INSERT when there’s no uniqueness conflict, and like a UPDATE when there’s a conflict (in which case it will update all the other columns). I had about ten UPSERTs that had to be rewritten as INSERT … ON CONFLICT (…) DO UPDATE SET – followed by all the columns to update. Ugh.
Importing data into Postgres was noticeably faster than into CockroachDB, and most importantly everything kept working fine after about a million entries were in the battery history table. And yes, everything was still inserted in a single transaction.
I took the opportunity to perform some long-needed changes to the data types used by the server. Making sure Clouttery clients kept receiving data with the formats and semantics they were expecting was a bit of a challenge, but very easy in the grand scheme of things.
As a very nice bonus, the server now does transactions properly. Previously, for a single API or website request, multiple Bolt transactions could be made. If something went wrong with one of the latter transactions, that one would be rolled back and no more transactions would be performed, but the changes done by previous ones would stay – like most databases, Bolt doesn’t let you rollback a committed transaction. Obviously, this could result in an inconsistent state.
Now, and after changing most functions in the server code to accept what can be described as a “transaction node”, each API request, web console request, or admin command works in a single transaction. Either there’s no error and everything goes through, or everything is rolled back. No more inconsistent data. sqalx was the library used to implement this.
The changes were pushed to production about two hours ago – after extensive testing on the staging environment, which unfortunately didn’t catch all the bugs. To identify problems, there’s nothing like dozens of devices running different clients and submitting different data to your server…
A few hotfixes later, everything appears to be working fine, but I’ll be keeping a close eye on the logs where, hopefully, all errors are logged. I say “hopefully”, because during testing I found out that the error return values (in Go, errors are values) from some of my own functions were not being logged, and some were completely ignored…
It would be great if over the next few days users could pay a bit more attention to the behavior of Clouttery, namely making sure that battery histories are updating as they should, and that notifications are generated when they should, according to their settings.
I’m probably a bit too much proud of this – at least, until I find a horrendous bug. This is how things should have been from the start, but at the same time, when I started this project, I did not know enough about relational database design to even do a mediocre job. So I went the easy, “no SQL” route and just used Bolt, which allowed me to get to something that worked, relatively quickly. And now I’m glad I could turn it into something better after about 60 hours of work…
I barely have time to work on Clouttery, and it becomes less and less of a commercially viable project as time goes by. It’s one of those projects that seems to never leave Beta status, and not for good reasons. But oh boy, the things I learn…
June 28, 2016 / gbl08ma / 0 Comments
Because, why not? Let’s Encrypt makes it so easy…
Let’s Encrypt certificates are now used on all the websites maintained by Segvault, but not all of the websites of the TNY Network – the CPUVInf website, for example, seems to be using CloudFlare-provided TLS.
August 23, 2015 / gbl08ma / 1 Comment
Go to the bottom, “Summing it up”, for the TL;DR.
The day I turn this website into a portfolio/CV-like thing will come sooner or later, and arguably that’s a better use for the domain gbl08ma.com than this blog with posts nobody cares about – except when I rant about new operating systems from Microsoft. But if you really care about such posts, do not worry: the blog will still exist, it just won’t be as prominent.
Meanwhile, and off-topic intro aside, the content usually seen on such presentation websites everyone-and-their-cat seems to have these days, will have to wait. In anticipation for that kind of stuff, let’s go in a kind of depressing journey through my eight years programming experience.
The start
The beginning was what many people would consider a horror movie: programming in Visual Basic for Applications in Excel spreadsheets, or VBA for short. This is (or was, at the time; I have no idea how it is now) more or less a stripped down version of VB 6 that runs inside Microsoft Office and does not produce stand-alone executables. Everything lives inside Office documents.
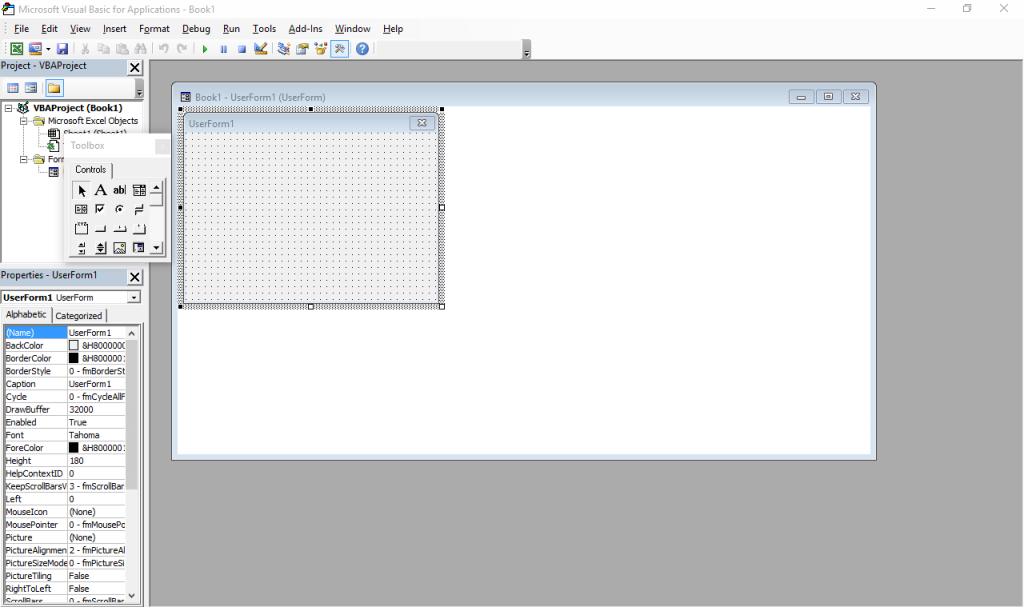
It still exists – just press Alt+F11 in any Office window. Also, the designer has Windows 7 Basic window styles… on Windows 10, which supposedly ditched all that?
I was introduced to it by my father, who knows his way around Excel pretty well (much better than I will probably ever will, especially as I have little interest). My temporal memory is quite fuzzy and I don’t have file timestamps with me for checking, so I was either 9, 10 or 11 years old at the time, but I’m more inclined to think 9-10. I actually went quite far with it, developing a Excel-backed POS system with support for costumer- and operator-facing character LCD screens and, if I remember correctly, support for discounts and loyalty cards (or at least the beginnings of it).
Some of my favorite things I did with VBA, consisted in making it do things it was not really designed for, such as messing with random ActiveX controls and making it draw strange-looking windows (forms) and controls through convoluted Win32 API calls I’d have copied from some website. I did not have administrator rights to my computer at the time, so I couldn’t just install something better. And I doubt my Pentium III-powered computer, already ancient at the time (but which still works today), would keep up with a better IDE.
I shall try to read these backup CDs and DVDs one day, for a big trip down the memory lane.
Programming newb v2
When I was 11 or 12 I was given a new computer. Dual core Intel woo! This and 2GB RAM meant I could finally run virtual machines and so I was put on probation: I administered the virtual computers, and soon the real hardware followed (the fact that people were tired of answering Vista’s UAC prompts also helped, I think). My first encounter with Linux (and a bunch other more obscure OS I tried for fun) was around this time. (But it would take some years for me to stop using Windows primarily.)
Around this time, Microsoft released the Express (free) editions of VS 2008. I finally “upgraded” to VB.NET, woo! So many new things to learn! Much of my VBA code needed changes. VB.Net really is a better VB, and thank Microsoft for that, otherwise the VB trauma would be much worse and I would not be the programmer I am today. I learned much about the .NET framework and Visual Studio with VB.NET, knowledge that would be useful years later, as my more skilled self did more serious stuff in C#.
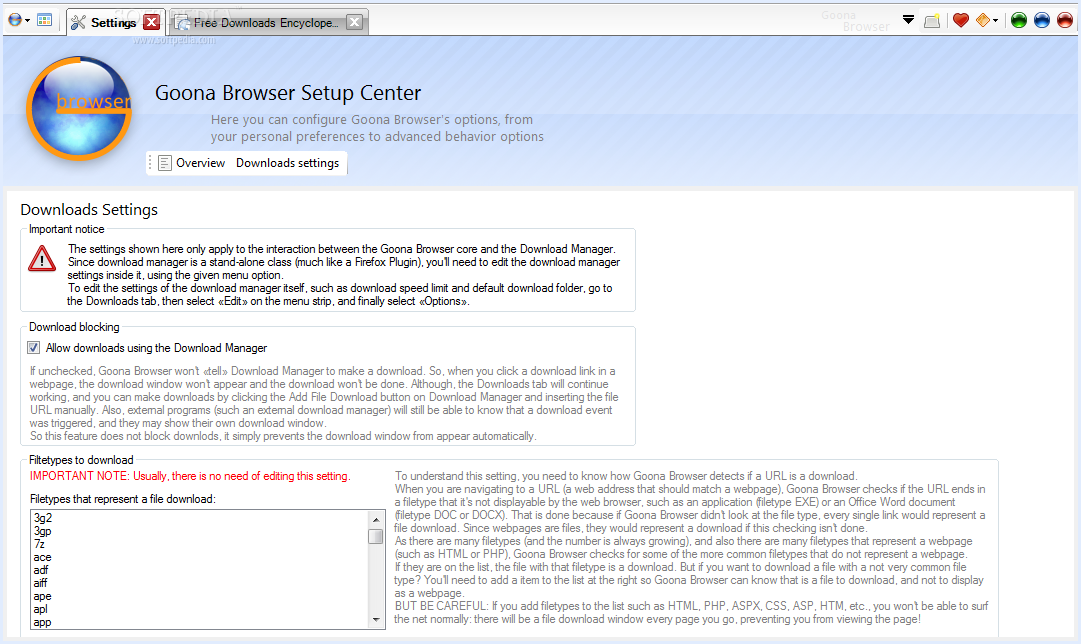
In VB.NET, I wrote many lines of mostly shoddy code. Much of that never saw the light of day, but there are some exceptions: multiple versions of Goona Browser made their way to the public. This was a dual-engine web browser with advanced UI, and futuristic concepts some major players copied, years later.
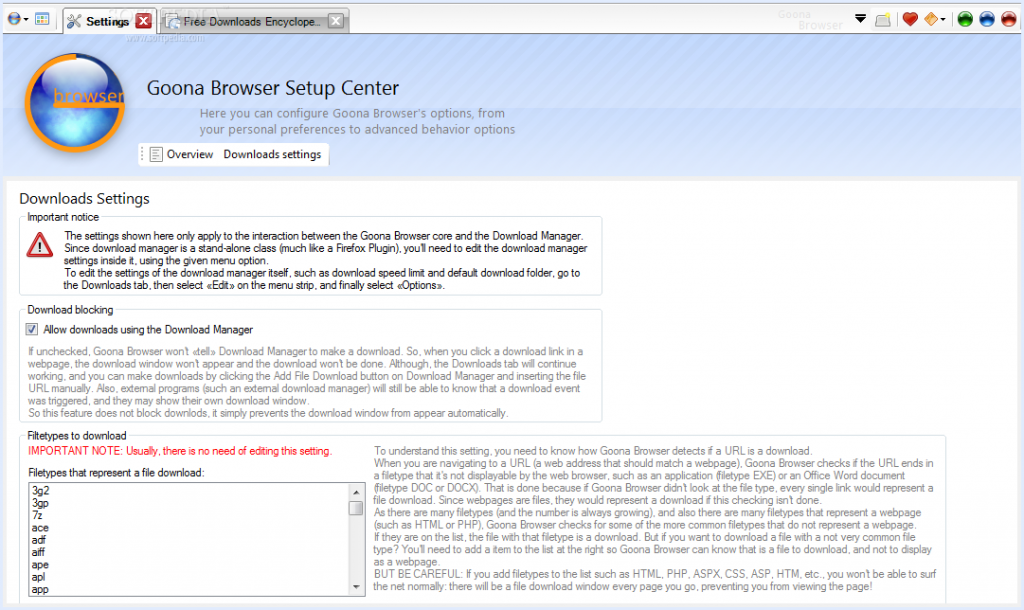
How things looked like, in good days (i.e. when it didn’t crash). Note the giant walls of broken English. I felt like “explain ALL the things”! And in case you noticed the watermark: yes, it was actually published to Softpedia.
If you search for it now, you can still find it, along with its website which I made mostly from scratch. All of this accompanied by my hilariously broken English, making the trip to the past worth its weight in laughs. Obviously I do not recommend installing the extremely buggy software, which, I found out recently, crashes on every launch but the first one.
Towards the later part of my VB.NET era, I also played a bit with C#. I had convinced myself I wanted to write an operating system, and at the time there was a project called COSMOS that allowed for writing (pretty limited) OS with C#… of course my “operating” systems were not much beyond a fancy command line prompt and help command. All of that is, too, stored in optical media, somewhere… and perhaps in the disk of said dual-core computer. I also studied and modified open source programs made in C# (such as the file downloader described in the Goona Browser screenshot) for my own amusement.
All this happened while I developed some static websites using Visual Web Developer Express as editor. You definitely don’t want to see those (mostly never published) websites, but they were detrimental to learning a fair bit of HTML and CSS. Before Web Developer I had also experimented with Dreamweaver 8 (yes, it was already old back then) and tried my hand at animation with Flash 8 (actually I had much more fun using it to disassemble existing SWFs).
Penguin programmer
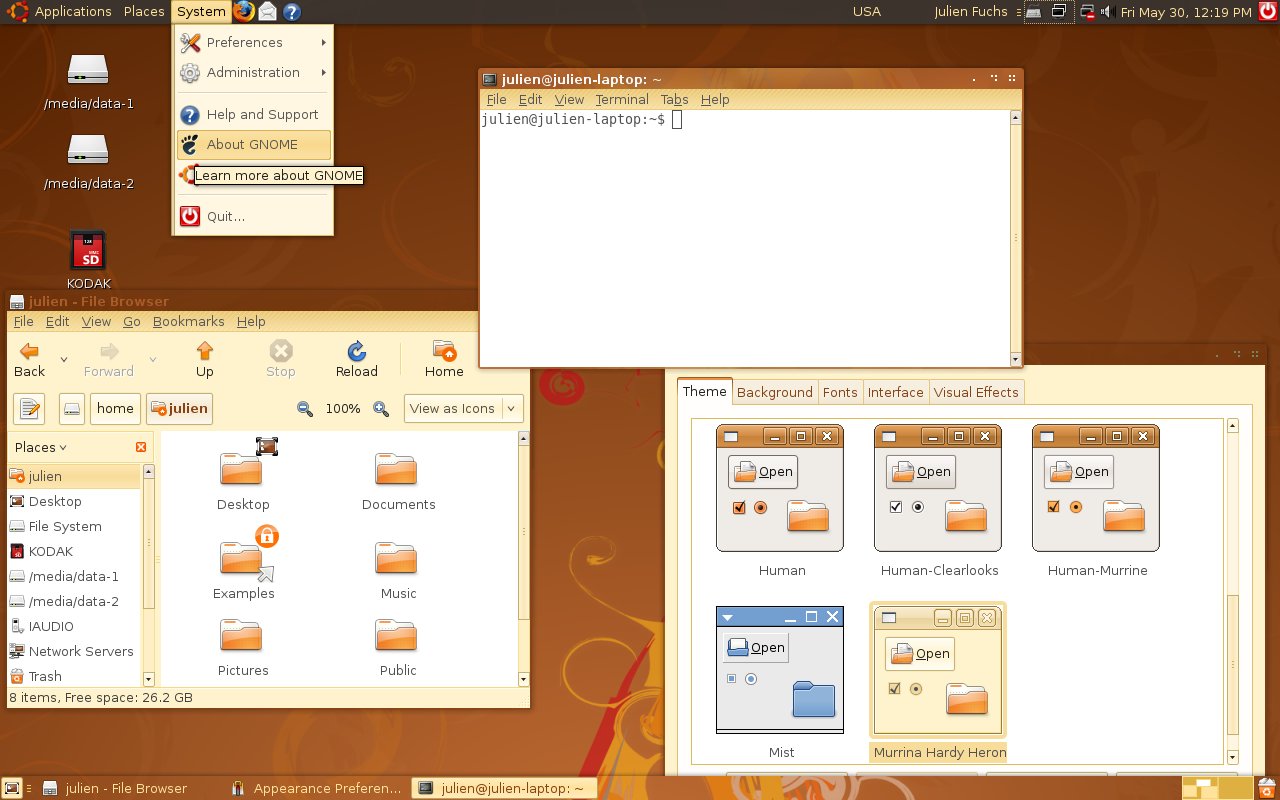
At this point I was 13 or so, had my first contact with Linux more than done, through VMs and Live CDs, aaand it happened: Ubuntu became my main OS. Microsoft “jail” no more (if only I knew what a real jailed platform was at the time…). No more clunky .NET! I was fed up with the high RAM usage of Goona Browser, and bugs I was having a hard time debugging, due to the general code clumsiness.
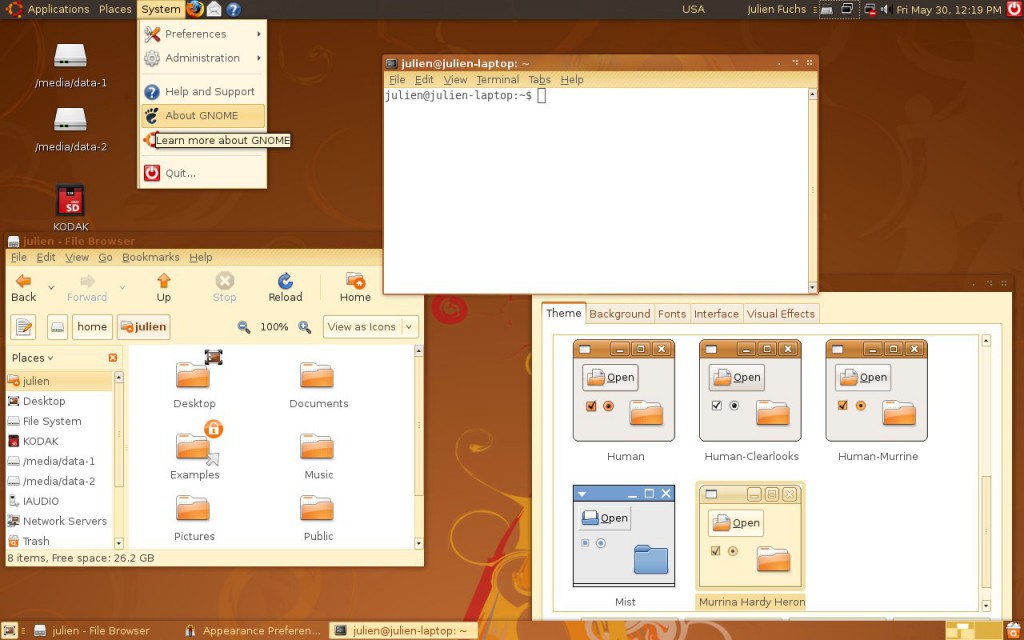
How Ubuntu looked like when I first tried it. Good times. Canonical, what did you do?
For a couple of years, in terms of desktop development, I only made some Python scripts for my own amusement and played a very small bit with MonoDevelop every time I missed .NET. I also made a couple Lua scripts for Rockbox. I learned much about Linux usage and system maintenance as I used it more and more on my own computers and on my first Virtual Private Servers, which I got after much drama in the free web hosting communities. Ugh, how I hate CPanel.
It was around this time that g.ro.lt and n.irc.su appeared. g.ro.lt was a URL shortener that would later evolve into 4.l.to and later tny.im. n.irc.su was a social network built on Elgg, which obviously failed. I also made some smaller websites, like one that would take you to random image hosting websites, URL shorteners and pastebins, so you would not use the same service every time you urgently needed one. These represented my first experiences with PHP programming.
I have no pictures to show. The websites are long gone, not on the Internet Archive, and if I took screenshots, I have no idea where I put them. Ditto for the logos. I believe I still have the source code for the random-web-service website somewhere, at least the front page layout.
All this working on top of free stuff: free (and crappy) subdomains, free (and crappy) web hosting, free (and less crappy) virtual servers. It would take me some time until I finally convinced myself I needed to spend some money for better reliability, a gist of support and less community drama. And even then I would spend Bitcoin, which I earned back when it was really cheap, making the rounds of silly faucets and pulling money out of CPAlead-like offers through the use of multiple proxies (oh, the joy of having multiple VPS…). To this day I still don’t have a PayPal account.
This time, and when I actively developed tny.im (as opposed to just helping maintain it), was the peak of my gbl08ma-as-web-developer phase. As I entered and went through high school, I would get more and more away from HTML and friends (but not server maintenance), to embrace something completely different…
Low level, little resources: embedded systems
For high school math everyone had to use a graphing calculator. My math teacher recommended (out of any interest) Casio calculators because of their ease of use (and even excitedly mentioned, Casio leaflet in hand, the existence of a new and awesome color screen model that “did everything and some more”). And some days later I had said model in my hands, a Casio fx-CG 20, or Prizm, which had been released about a year before. The price difference from the earlier dot-matrix screen Casio calcs was too small to let the color screen go.
I was turning 15, or had just turned 15. I remember setting up the calculator and thinking, not much after, “I want to code for this thing”. Casio’s built-in Basic dialect is way too limited (and after having coded in “real” languages, Basic was silly). This was in September 2011; in March next year I would be releasing my first Prizm add-in, CGlock, a calculator PIN-locking software.


Minimalist look, yay! So much you don’t even notice it’s a color screen.
This was my first experience with C; I remember struggling with pointers, and getting lots of compilation warnings and errors, and run-time errors. Then at some point everything just “clicked in” and C soon became my main language. Alas, for developing native software for the Prizm, this is the only option (besides using C++ without most of its features, not even the “new” keyword).
The Prizm is a horrible platform, especially for newbie C programmers. You can’t use a debugger, nor look at memory contents, the OS malloc/free implementation has bugs (and the heap is incredibly small, compared to the stack) and there’s always that small chance some program damages your calculator, or at least corrupts your estimated files and notes. To this day, using valgrind and gdb on the desktop feels to me as science fiction made true. The use of alloca (stack allocation) ends up being preferred in relation to dynamic allocation, leading to awkward design decisions.

Example of all the information you can get about an error in a Prizm add-in. It’s up to you to go through your binary (and in some cases, disassemble the OS) to find out what these mean. Oh, the bug only manifests itself when compiling with optimizations and without symbols? Good luck…
There is a proprietary emulator, but it wasn’t designed for software development and can’t emulate certain things. At least it’s better than risking damage to expensive hardware. The SuperH-4 CPU runs at 58 MHz and add-ins have access to about 600 KiB of memory, which is definitely better than with classic z80-powered Texas Instruments calculators, but one still can’t afford memory- or CPU-intensive stuff. But what you gain in performance and screen resolution, you lose in control over the hardware and the OS, which still have lots of unknowns.
Programming for the Prizm taught me how it’s like to work without the help of the C standard libraries (or better, with the help of incomplete and buggy standard libraries), what a stack overflow looks like (when there’s no stack protection), how flash memories work, what DMA is, what MMUs do and how systems can be bricked when their only bootloader is not read-only. It taught me how compilers work from an end-user perspective, what kind of problems and advantages optimizations introduce, and what it’s like to develop parts of the C standard library.
It also taught me Casio support in Portugal (Ename) is pretty incompetent at fixing calculators, turning my CG 20 into a CG 10 and leaving two big capacitors out of a replacement main board. In this hardware topic, I learned quite a bit about digital logic from Prizm hardware discussions at Cemetech. And I had some contact with SH4 assembly and a glimpse into how to use IDA Pro. Thank you Casio for developing a system that works so well and yet is so broken in so many under-the-hood ways, and thank you Cemetech for briefly holding the Prizm higher than TI calcs.
I developed other add-ins, some from scratch and others as ports of existing PC software (such as Eigenmath). I still develop for the Prizm from time to time, but I have less and less motivation as the homebrew community has stagnated and I use my Prizm much less, as I went to university. Experience in obscure calculator platforms does not make for a nice CV.
Yes, in three years or so I went from the likes of Visual Studio to a platform where the only way to debug is to write text to the screen. I still like embedded and real-time programming a lot and have moved to programming more generic and well-known things such as the ESP8266.
Getting in the elevator
During the later part of high school (which I started in the fall of 2011 and ended in the summer of 2014), I did more serious Python stuff, namely Mersit, later deprecated in favor of Picored, which is not written in Python but in Go. Yes, I began trying higher-level stuff again (higher level, getting in the elevator… sorry, I’m bad at jokes).
My first contact with Go was when I was 17, because I wanted to develop something that ran without external dependencies (i.e., unlike Java or .NET) and compiled to native code. I wanted to avoid C/C++, but I wasn’t looking for “a better C” either, so Rust was not it. Seeing so much stuff about Go at Hacker News, one day I decided to try my hand at it and I like it quite a lot – I’m still unsure if I like it because of the language itself or because of the great libraries one can use with it, but I think both play an important role.


This summer I decided to give C# another chance and I’m quite impressed – turns out I like it much more than I thought. It may have something to do with trying it after learning proper languages vs. trying it when one only knows VB. I guess my VB.NET scars are healed. I also tried a bit of Java, in my first contact with it ever, and it seems my .NET hate converted into Android API hate.
Programming with grades
University gave the opportunity (or better, the obligation) of having other people criticize my code. The general public could already see the open-source C code of my Casio Prizm add-ins, and even the ugly code of Goona Browser, but this time my code was getting graded. It went better than I initially thought – I guess the years of experience programming in different languages helped, especially as many of the people I’m being compared with have only started programming this year.
In the first semester we took an introductory programming course, which used Python, and while it was quite easy for me, I took the opportunity to learn Python to a greater depth than “language in which to write quick and dirty glue code”. You see, until then I had not used classes in my Python code, for example. (This only goes to show Python is a versatile language, even if slow.)
We also took an introductory computer architecture course where we learned how basic CPUs work (it was good for gluing all the separate knowledge I already had about it) and programmed in assembly for a course-specifc CISC-like architecture. My previous experience with reading SH4 assembly proved quite useful (and it seems that nowadays the line between RISC and CISC is more blurred than ever).
In the second semester, I had the opportunity to exercise my C knowledge, this time not limited to the Prizm platform. More interestingly, logic programming, a paradigm I had no intention of ever programming in, was presented to us. So Prolog it was. It went much better than I anticipated, but as most other people who (are forced to) learn it, I have no real use for it. So the knowledge is there, waiting for The Right Problems(tm). I am afraid I’ll forget much of it before it becomes useful, but if there’s something picking C# up again taught me, is that I can pick up pretty fast skills learned and abandoned long ago.
The second year is about to begin and there’s some object-oriented programming coming, I hope I do well.
Summing it up
I have written non-trivial amounts of code in at least 8 languages: Visual Basic, PHP, C#, Python, Lua, C, Go, Java and Prolog. I have contacted with two assembly dialects and designed web pages with HTML, CSS and Javascript, and of course automated some tasks with bash or plain shell scripting. As can be seen, I’m yet to do any kind of functional programming.
I do not like “years of experience” as a way to measure language proficiency, especially when such languages are learned for use in short-lived side projects, so here’s a list with an approximate number of lines of code I have written in each language.
- C: anywhere between 40K lines and 50K lines. Call it three years experience if you will. Most of these were for Prizm add-ins, and have since been rewritten or heavily optimized. This is changing as I develop less and less for the Prizm.
- PHP: over 15K lines, two years if you want to think that way. The biggest chunk of these were for developing the additions to YOURLS used in tny.im, but every other small project takes its own 200-500 lines of code. Unfortunately, most of this is “bad” code, far from idiomatic. The usual PHP mess, you know.
- Python: at least 5K lines over what amounts to about six months. Of these, most of the “clean” lines (25-35%) were for university projects.
- Go: around 7K lines, six months. Not exactly idiomatic code, but it’s clean and works well.
- VBA: uh, perhaps 3 or 4K lines, all bad code 🙂
- VB.NET: 10K lines or so, most of it shoddy code with lots of Try…Catch to “fix” the problems. Call it two years experience.
- C#: 10K lines of mostly clean and documented code. One month or so 🙂
- Lua: mostly small glue scripts for my own amusement, plus some more lines for use in games such as Minetest, I estimate 3-4 K lines of varying quality.
- Java: I just started, and mostly ported C# code… uh, one week and 1.5K lines?
- HTML, CSS and JS: my experience with JS doesn’t go much beyond what’s needed to modify DOM elements and make simple AJAX requests. I’ve made the frontend for over 5 websites, using the Bootstrap and INK frameworks.
- Prolog: a single university assignment, ~250 lines or one month. A++ impression, would repeat – I just don’t see what for.
In addition to all this, I have some experience launching the programs and services I make – designing logos/branding, versioning, keeping changelogs, update instructions, publishing, advertising, user support. Note that I didn’t say I’m good at any of these things, only that I have experience doing them, for better or worse…
Things I’d like to have more experience with:
- Continuous integration / testing in general;
- Debugging code outside of .NET/Visual Studio and printing debug lines in C;
- Using Git and other VCS in big repos/repos with more people (I want to see those merge conflicts and commits to the wrong branch coming);
- Server-side web development on something other than PHP and Go. And learning to use MVC frameworks, independently of the language;
- C++ (and Java, out of necessity. Damned Android);
- Game development. Actually, this is how many people start, but I’m so cool that I started by developing POS software 🙂
July 31, 2013 / gbl08ma / 3 Comments
For a long time, I’ve used YOURLS in my URL shortener projects. I have always liked extending it, so that it did something more than just URL shortening. The results of my work have turned, over the past two years, into what tny.im is today.
Until a few days ago, tny.im was running with software based on YOURLS. Yes, “based on YOURLS”. It wasn’t running “on top of” YOURLS. As I added more features to this URL shortener, I found it easier to just modify the core files and add rows to database tables at will. This came with a price: updating YOURLS without losing my modifications and while keeping database compatibility was really hard, requiring me to rewrite all the modifications. To make things even worse, I had modified some of the core files for them to work with the Bootstrap CSS and JS things. The statistics page (yourls-infos.php), which I had also managed to modify to a point where not only it was Bootstrap-themed, but was also the main UI for users to edit short URLs, was a specially hard problem to solve if I was updating YOURLS.
I could have stayed running the 1.5 version of the said script forever. However, it lacked many under-the-hood improvements of the 1.6 versions, and as new versions would be released, it would only become more obsolete. Again, a big problem resided on the link statistics page: it wouldn’t handle links with many clicks properly, because it would use a lot of memory. This bug no longer existed on 1.6, and this was something that kept me thinking I really should update to a newer version.
Another thing that I had heavily modified for tny.im was the public API. I had modified it to not support some methods which would disclose too much information (e.g. long URLs for paid-access links and links which had reached their hit limit), as well as added support for tny.im-specific features like the passcode, hitlimit and Bitcoin related things.
My code for all these things was really ugly. It had been progressively added and changed over the course of two years, had multiple coding styles, multiple indentation styles, multiple bug styles and God-knows-what-else. The fact that I only worked on the project sporadically meant that I often didn’t remember what I had done already, meaning there were giant mistakes like two variables for the same thing. Somehow it all worked, well enough to take to the correct destination over two hundred thousand short URL clicks.
Some days ago, I finally decided it was time to do something. I wanted to add new features to tny.im and future-proof it at the same time, but the code was impossible to maintain – the original core code, mixed with my bad code, made it seem it would inevitably break if I touched it. I knew, from the start, that the proper way to add features to YOURLS was to code plugins – but laziness, convenience and the fact that version 1.5 didn’t offer that many plugin hooks made me modify the core files, as I said above.
I had to start from scratch, doing things in a “staging” vhost that had no communication to the live tny.im website. I started by installing YOURLS on that vhost, on a database separate from the live one, of course. Then I accepted the challenge of trying to implement all the tny.im features, including the Bootstrap theme, without ever touching the core files of YOURLS.
Fortunately, version 1.6 of YOURLS had many more plugin hooks. But I knew I wouldn’t be able to implement every feature as a plugin. Things ended up like this: I consolidated my hackish plugin soup from the old tny.im scripts in a single “tnyim-framework” plugin, and things like the index page UI, link lists/folders, Bitcoin address shortening and “internet toll” features, as well as login/logout (which is separate, and has always been, from YOURLS auth methods) would keep being separate from YOURLS.
Instead of modifying core files like functions.php and functions-html.php to add my code, I put them in a separate tny.im-specific folder. It has it’s own “load-tnyim.php” file, in the style of the “load-yourls.php” file, which loads the necessary variables and files for the tny.im features and UI.
The problem with the statistics page, as well as some modifications I had made on yourls-loader.php, was solved my creating tny.im-specific files that are similar to the YOURLS ones and perform the same functions, but have my modifications. The new statistics page is based on the YOURLS 1.6 one, and it was a hassle to modify to meet the functionality of the old one, that is, Bootstrap-themed, and with that “Manage” tab that allows people to edit links. This was mainly because, as @ozh says, it is an “awful HTML/PHP soup”. Also, it has little to none plugin hooks from what I can see, but even if it had, they would never be enough to allow me to customize it to the point where I did.
Things like link preview, and the API modifications, went in the tnyim-framework plugin. And the reason why I think YOURLS is awesome, is that I managed to change much of the API behavior, adding new return and request fields, as well as obfuscating some, just with plugin hooks.
As for the database, rows specific to tny.im are now kept on their own table. The functions.php on the tny.im folder has methods for adding and editing URLs that handle the tny.im features. It works like this: the code calls my custom methods for adding/editing short links; then, things are added/edited on the normal YOURLS DB table using the core methods, and then my code takes care of the other table which stores things like link hit limit and price (for internet toll links), as well as adding the link to the users’ account when appropriate.
Speaking of user accounts, the data that relates users to the keywords they have access to, is kept also separate from YOURLS tables. Same with the lists of links feature.
Finally I moved the columns of each database table to their correct destination in the new tables – five hours worth of SQL commands. Then I moved the new script files to the vhost of the live site, after editing the YOURLS configuration file and the nginx vhost config of course. It seemed to start working right away. All this took me two days.
Now the code for tny.im is much more clean, readable and most importantly, maintainable. I can finally add new features to tny.im without breaking half of the existing ones. And I can update YOURLS without breaking the whole thing, since none of the new features are implemented in the core files. @ozh’s improvements in pages like the links statistics one and yourls-loader will not automatically get merged with the tny.im code, but I can add them manually while keeping my changes.
I’m not yet fully sure the new tny.im is clear of bugs, but over 90% of it seems to work the same or better than before. It should look and work pretty much the same as it did before – which only proves, that I really made a wrong move when I started editing core files, since everything could have been done without touching them. I think I learned the lesson, hopefully not only for YOURLS, but for most scripts which have plugin interfaces.
I think I made the most full-featured URL shortener ever seen, and obviously I’m proud (certainly too proud) of it. It’s all built around YOURLS, and I bet you wouldn’t even tell it was powered by that script at a first glance. Stay tuned as more features and bug fixes are to come.
May 30, 2012 / gbl08ma / 0 Comments
I have been very busy with my offline life: school, family and friends haven’t been leaving much time left for me to blog here. When I have some free time, I try to keep up-to-date with the online communities I take part in and also work on my l.f.nu URL shortener. By the way, have I told you that l.f.nu now supports editing short links?
When you shorten a new link, you receive a random code specific to it. Keep that code saved as if it were a password, as it is the only way to edit a shorten link through its Click Statistics page (add a + symbol to the end of the shorten link, then open the tab “Manage”).
This feature about link passwords (which I call “passcodes”) is something I developed just for l.f.nu, it is not available in the standard YOURLS installation. I have no plans to make it open source right now, as I haven’t implemented the thing as a plugin, and the code is a bit unorganized.
So no, I haven’t disappeared from the online world yet. I’m just a bit more silent these days…
April 21, 2012 / gbl08ma / 0 Comments
Of all the ways to express your opinion on some subject, I believe the “Like”, “+1” and similar buttons are some of the worst. Why? Well, nowadays “liking” something on the internet means little to nothing. People are asked to “like” things, “likes” are sold and bought as a product and not actually as a consequence on someone’s feelings on what one has seen/read/experienced, and now the quality of things seems to have become measured in the number of “likes”.
I usually say the “Like” button was the best invention for those that are so lazy that don’t want to write anything, or those so lazy that don’t want to create an opinion on a certain subject. It is also a great thing for those who don’t care about explaining why they “like”. The same argument is also true for “disliking”, on the places where that’s permitted. Those who have something to say will comment or reply, but “liking” is something so vague that adds little value.
It’s important to let people express their opinion on other Internet content in a meaningful way. Allowing users to comment and reply in an Internet that’s more and more made by its daily users is a good thing (that is, if you really promote freedom of speech). It perhaps even motivates people to think about things and form their own view on the subject, instead of just “liking” a view that’s being forced into their minds.
Imagine someone on the Internet says “WordPress is a really cool blogging tool”. You have the following options: you can either “Like” this statement, comment on it, or don’t give a s*** about it and move on. If you agree with the point of view stated, but have nothing to say on it, you’ll probably click the “Like” button. If you don’t agree, you’ll move on, or eventually post a short comment stating that you don’t agree. And if you are of those that actually wants to express an opinion and cares to write trying to use the language properly, you’ll comment. Now imagine you can’t comment… probably you’ll just move on.
If you comment and your comment is insightful, it will add value to an existing discussion or perhaps even start a new one. But those who “like”… what will happen? When you see “34 people like this”, do you have any idea of what those 34 people think? Did they “like” because they found it funny? Because that content was interesting? Because it was so wrong that it made one laugh? And who knows how many people didn’t like that content, specially when compared to something else? I think this need for comparison and ranking caused “likes” to be used as if they were a measurement unit, as I’ll explain later.
I even fear one day people living in a democracy will vote for their representatives by “liking” them. Knowing how many didn’t “like” any of the options is going to be hard. And you won’t know it was because none of the options suited them, or because they were ill in the elections day, or because they preferred going to the beach instead of voting, errm, “liking”. Knowing how many people “liked” twice can get hard too, but that’s easily fixed.
One more thing that illustrates the stupidity of the “Like” (or similar) button: it doesn’t exist in natural human communication. Well, it does exist, but it’s way more elaborated than a “Like”. Imagine you’re hanging out with your friends, in the pre-“Like”-button era, and one of them tells a joke. Nobody’s going to say “I like” without saying anything more. Since it was a joke, if one has found it funny, laughs will follow. And if it was really funny, one will laugh a lot (I also have my opinion on the LOL thing, but that’s for another post). And if the joke wasn’t funny at all, or the way it was told wasn’t good enough, one will at least smile, or say “Man, you’re not good at telling jokes”.
And another example: if you go to a restaurant and you enjoy the meal you ordered, it’s unlikely that you just say “Like”. Even if you only want to say you liked what you ate, there are many, many ways to say “Like”. Now if I want to be ultra-nerd, I can even say the “Like” button impoverishes people’s vocabulary. 🙂 So to conclude this point: at most, people have brought “I like this” into real-life communication after it became popular in the web – it didn’t exist in such a monotone and endlessly overused way before that.
I’m not saying the “Like” button isn’t useful – for the times when you actually like and there’s nothing else to say. The problem is, people became lazy and now they prefer to click a button than to write their opinion – sometimes because they don’t have any opinion, other times because it’s just easier to “Like”. Again, if I jump to extreme cases, the web might become something where some party says “1+2=5” and all there is to say is that “56,322,943 people like this”.
Now about the “Like” button as a measure of quality of things. If for a given “product X” there are 60000 likes on some social network and for another “product Y” there are only 2000 likes, people will often think “product X” is better than “product Y”. But those who will care about doing some research will find that “product Y” doesn’t contain “substance N”, which is really bad for health, while “product X” does contain it. “Product X” has more likes because it appeared first on that social network as part of an advertising campaign that costed millions. Conclusion: the number of people that “Like” something is worth nothing, even though at first it might look like so. Even because “likes” can often be bought: imagine that millionaire advertising campaign included buying 10000 “likes” to bootstrap it, and “liking” things becomes even more meaningless.
But the example doesn’t need to be about evil companies and products that are bad for health being advertised in a giant scale. You certainly know those people that ask for likes on their content. And those annoying “If you are happy, like this”-style messages. This happens in social networks in each other’s friends circles.
Oh, and another thing: “Like” buttons are used for tracking people whenever they go on the web. You can leave the “website X” that hosts a “Like” button, that as long as there is a “Like” button of that “website X” in any other page, the owners of that website can know you’re at that page. And I’m not dreaming, as you know, Facebook and other social networks do this.
This stupid “Like”/”+1” button is one of the many reasons why I deactivated my Facebook account some days ago. But this isn’t only about Facebook, it’s about everything sponsoring a “Like” button. (At least Twitter doesn’t have such a “feature”, hooray! 🙂 )
Putting short: yes, you can keep the “Like” button, but make sure people can comment – and I’d encourage them to comment and show their views on things whenever possible: I think it adds a lot more value to the Internet.
EDIT: looks like Facebook “Likes” aren’t speech protected by the US First Amendment.
December 27, 2011 / gbl08ma / 0 Comments
Do you remember the OpenID standard, that aims to describe “how users can be authenticated in a decentralized manner, eliminating the need for services to provide their own ad hoc systems and allowing users to consolidate their digital identities.”? Well, if you happen to frequently authenticate on a service or website that supports it, or if you happen to run or maintain one of these websites or services, most likely you remember. But the surprising part is, OpenID is used in more things than you can imagine.
Till some time ago, I don’t recall seeing much opportunity for logging in with an OpenID – except on the websites of the ID provider themselves. The first OpenID authentication method I recall using was using Twitter IDs, although in that case I could as well have used Google or Facebook. But people use OpenID without actually recognizing it as an implementation of that standard. Yes, OpenID is that “Login with Facebook” or “Login with Twitter” thing. These login methods are usually just not (visibly) branded as being OpenID.
So basically, that represents a win for OpenID, right? Well, in theory yes, but my opinion is different. While many websites carry out OpenID in such a way that it is comfortable for every user, others simply don’t. What do I call a “comfortable usage” of OpenID? An implementation of the standard in such a way that it allows you to choose the ID you want to use. Eventually, it also lets you not use OpenID, through the creation and authentication of a traditional account, where the chosen authentication parameters are isolated to the website or service in question, like we’ve seen before the OpenID boom.
This “comfortable implementation” fits the most users I can think of: by assuring authentication using accounts on the most popular OpenID providers, such as Google, WordPress and Facebook, and using simpler, standalone (i.e. not tied to any service in particular) and/or less-known providers such as chi.mp, claimID and myOpenID, the chances of the person willing to be authenticated having an ID with one of the providers supported is way bigger. But because not everyone likes the OpenID idea, or they might simply not have a registered account with one of the IDs supported, an additional “traditional” authentication method should also be provided, so people can create an account with the website or service in question, and not tie that account with an OpenID.
The advantages of what I call a “comfortable implementation” are very noticeable in my opinion: it increases the user base of a website, since if people find it easy to login with an account they already have on other service, it’s very likely they’ll login on that website. It also makes the act of engaging with the website a breeze, because people don’t need to go over the hassle of maintaining yet another user/password combination, there is no signup form, captcha or email validation. While this may change depending on the OpenID provider and on the service or website implementing OpenID authentication, in most situations the OpenID login process is easier. We just got to recognize another advantage: if users find registering and logging in easier, the website or service will not only get more users, as it will have its users more satisfied. As I said, for the user there’s not the hassle of not remembering the specific password and having to reset it, and for the website management, there can be also a reduction in the number of support requests, assuming OpenID is properly implemented. All I did here was point some of the advantages of OpenID, but it can also have a lot of disadvantages when its implementation is not so comfortable for the user.
A website that I remember having a proper implementation of open IDs is Blogger, at least when posting a comment on a blog – it allows you to choose which profile you want to comment under, from a Twitter, WordPress or Google account to a OpenID, discussed here.
But what is an “uncomfortable implementation”? From my point of view, OpenID can become a very negative thing if, for example, the website the user’s tying to authenticate to doesn’t offer the ID provider on which the user has an account. It is also possible that an OpenID implementation fits most, but not all. A very clear evidence of this problem is given with websites that offer “Login with Facebook” as their only authentication method – I don’t think this can be called an OpenID implementation, even though Facebook is an OpenID provider. But why is this a problem? People just start based on the premise that all the internet users have a Facebook account. False. I can illustrate this with personal situations… it’s not happened once nor twice, but dozens of times: *le me browsing the ‘net*, *le me finds a website he likes*, *thinks he should signup*, *looks for the signup link*… oh crap, looks like all we get is this:

Call me stupid, “forever alone”, or whatever you want: I might even have a Facebook account, but I may not use it and even if I do, I don’t want all dozens of websites being authenticated with that s*ht Facebook is, and eventually with these websites being able to post to my Facebook wall, access my status, photos or other things “normal” people put on Facebook.
I’m giving this example for Facebook, but the problem goes for other ID providers. There are websites that support open IDs, and a few even say they support OpenID (the standard), but then you’re presented with a “Login with XYX” link where XYX is a single ID provider of their liking. Sometimes you’re lucky enough and you have an ID from this provider, other times you just need to go registering for yet another ID, defeating all the purpose of open identification and OpenID.
Although, there are cases where requiring a login with a specific service is mandatory. For example, on services that are dedicated to changing your Twitter profile background with a generated one, a Twitter account is of course required, so a Twitter-only login makes all sense. Same goes for Google/Blogger/Facebook/WordPress dedicated services, but please, if it’s not required to be tied into a specific service, then just let people use whatever ID provider they want, or provide a traditional signup and login method. Else, open authentication and OpenID might become hassles that drive users away.
Other things can be discussed about OpenID – I can argue that it is unsafer than traditional user/password logins, because if the OpenID provider gets cracked and authentication information gets exposed, then all the accounts authenticated with OpenID on other websites are open to the crackers – much like an user that always uses the same password and username on multiple websites. We can also discuss about these shiny buttons provided by social networks and the like, that allow you to authenticate using your account on them, to “like” or to “share” posts – these are used for user tracking, and seeing what the crowd likes, helping on creating even more directed advertising. There are plugins that block these trackers, and usually some hosts file or iptable rules work well, fortunately (if you don’t use the service from which the shiny trackers are coming).
I do not represent the OpenID foundation, Facebook, Google, Twitter or other OpenID provider. I am not encouraging their use or otherwise; I’m just exposing my very irrelevant opinion on the subject. If you spot any factual or spelling mistake, please contact me or comment below. Thanks for spending some minutes of your life reading this post!